Interval spoľahlivosti pre odhad priemeru (rozptyl je známy) v MS EXCEL. Interval spoľahlivosti
Akákoľvek vzorka poskytuje len približnú predstavu o všeobecnej populácii a všetky štatistické charakteristiky vzorky (priemer, modus, rozptyl...) sú aproximáciou alebo povedzme odhadom všeobecných parametrov, ktoré vo väčšine prípadov nie je možné vypočítať. k neprístupnosti bežnej populácie (obrázok 20) .
Obrázok 20. Chyba pri odbere vzoriek
Môžete však určiť interval, v ktorom s určitou mierou pravdepodobnosti leží skutočná (všeobecná) hodnota štatistickej charakteristiky. Tento interval sa nazýva d interval spoľahlivosti (CI).
Takže všeobecná priemerná hodnota s pravdepodobnosťou 95% leží v rámci
od do, (20)
Kde t – tabuľková hodnota Študentovho testu pre α = 0,05 a f= n-1
V tomto prípade možno nájsť aj 99 % CI t vybrané pre α =0,01.
Aký je praktický význam intervalu spoľahlivosti?
Široký interval spoľahlivosti naznačuje, že priemer vzorky presne neodráža priemer populácie. Je to zvyčajne spôsobené nedostatočnou veľkosťou vzorky, prípadne jej heterogenitou, t.j. veľký rozptyl. Obidve poskytujú väčšiu chybu priemeru, a teda aj širší CI. A to je základ pre návrat do fázy plánovania výskumu.
Horná a dolná hranica CI poskytujú odhad, či budú výsledky klinicky významné
Zastavme sa podrobnejšie pri otázke štatistickej a klinickej významnosti výsledkov štúdia skupinových vlastností. Pripomeňme si, že úlohou štatistiky je na základe vzorových údajov odhaliť aspoň nejaké rozdiely vo všeobecných populáciách. Výzvou pre lekárov je odhaliť rozdiely (nie hocijaké), ktoré pomôžu diagnostike alebo liečbe. A štatistické závery nie sú vždy základom pre klinické závery. Štatisticky významný pokles hemoglobínu o 3 g/l teda nie je dôvodom na obavy. A naopak, ak nejaký problém v ľudskom tele nie je rozšírený na úrovni celej populácie, nie je to dôvod, aby sme sa týmto problémom nezaoberali.
|
Pozrime sa na túto situáciu príklad. Výskumníkov zaujímalo, či chlapci, ktorí trpeli nejakým druhom infekčného ochorenia, nezaostávajú v raste za svojimi rovesníkmi. Na tento účel bola vykonaná vzorová štúdia, ktorej sa zúčastnilo 10 chlapcov, ktorí trpeli týmto ochorením. Výsledky sú uvedené v tabuľke 23. Tabuľka 23. Výsledky štatistického spracovania
Z týchto výpočtov vyplýva, že priemerná výška vzorky 10-ročných chlapcov, ktorí trpeli nejakým infekčným ochorením, sa blíži k normálu (132,5 cm). Spodná hranica intervalu spoľahlivosti (126,6 cm) však naznačuje, že existuje 95% pravdepodobnosť, že skutočná priemerná výška týchto detí zodpovedá pojmu „nízka výška“, t.j. tieto deti sú zakrpatené. V tomto príklade sú výsledky výpočtov intervalu spoľahlivosti klinicky významné. |
|||||||||||||||||||
V predchádzajúcich podkapitolách sme sa zaoberali otázkou odhadu neznámeho parametra A jedno číslo. Toto sa nazýva „bodový“ odhad. V mnohých úlohách musíte nielen nájsť parameter A vhodnú číselnú hodnotu, ale aj na vyhodnotenie jej presnosti a spoľahlivosti. Musíte vedieť, k akým chybám môže výmena parametra viesť A jeho bodový odhad A a s akou mierou istoty môžeme očakávať, že tieto chyby nepresiahnu známe limity?
Problémy tohto druhu sú relevantné najmä pri malom počte pozorovaní, keď bodový odhad a v je do značnej miery náhodné a približné nahradenie a môže viesť k vážnym chybám.
Aby ste získali predstavu o presnosti a spoľahlivosti odhadu A,
V matematickej štatistike sa používajú takzvané intervaly spoľahlivosti a pravdepodobnosti spoľahlivosti.
Nech pre parameter A nestranný odhad získaný zo skúseností A. V tomto prípade chceme odhadnúť možnú chybu. Priraďme nejakú dostatočne veľkú pravdepodobnosť p (napríklad p = 0,9, 0,95 alebo 0,99) takú, že udalosť s pravdepodobnosťou p možno považovať za prakticky spoľahlivú a nájdime hodnotu s, pre ktorú
Potom rozsah prakticky možných hodnôt chyby vznikajúcej pri výmene A na A, bude ± s; Veľké chyby v absolútnej hodnote sa objavia len s nízkou pravdepodobnosťou a = 1 - p. Prepíšme (14.3.1) ako:
Rovnosť (14.3.2) znamená, že s pravdepodobnosťou p je neznáma hodnota parametra A spadá do intervalu
Je potrebné poznamenať jednu okolnosť. Predtým sme opakovane zvažovali pravdepodobnosť, že náhodná premenná spadne do daného nenáhodného intervalu. Tu je situácia iná: veľkosť A nie je náhodný, ale interval / p je náhodný. Jeho poloha na osi x je náhodná, určená jeho stredom A; Vo všeobecnosti je dĺžka intervalu 2s tiež náhodná, pretože hodnota s sa vypočítava spravidla z experimentálnych údajov. Preto by v tomto prípade bolo lepšie interpretovať hodnotu p nie ako pravdepodobnosť „zasiahnutia“ bodu A v intervale / p, a ako pravdepodobnosť, že náhodný interval / p pokryje bod A(obr. 14.3.1).

Ryža. 14.3.1
Pravdepodobnosť p sa zvyčajne nazýva pravdepodobnosť dôvery, a interval / p - interval spoľahlivosti. Hranice intervalov Ak. a x =a- s a a 2 = a + a sú povolaní hranice dôvery.
Uveďme iný výklad pojmu interval spoľahlivosti: možno ho považovať za interval hodnôt parametrov A, kompatibilné s experimentálnymi údajmi a nie sú v rozpore s nimi. V skutočnosti, ak súhlasíme s tým, že udalosť s pravdepodobnosťou a = 1-p považujeme za prakticky nemožnú, potom tie hodnoty parametra a, pre ktoré a - a> s musia byť uznané ako protichodné experimentálne údaje a tie, pre ktoré |a - A a t na 2.
Nech pre parameter A existuje nestranný odhad A. Keby sme poznali zákon rozdelenia množstva A, úloha nájsť interval spoľahlivosti by bola veľmi jednoduchá: stačilo by nájsť hodnotu s, pre ktorú
![]()
Problém je v tom, že zákon distribúcie odhadov A závisí od distribučného zákona množstva X a teda na jeho neznámych parametroch (najmä na samotnom parametri A).
Na obídenie tohto problému môžete použiť nasledujúcu približnú techniku: nahraďte neznáme parametre vo výraze pre s ich bodovými odhadmi. S pomerne veľkým počtom experimentov P(asi 20...30) táto technika zvyčajne poskytuje výsledky, ktoré sú z hľadiska presnosti uspokojivé.
Ako príklad uvažujme problém intervalu spoľahlivosti pre matematické očakávania.
Nech sa vyrába P X, ktorých charakteristikou je matematické očakávanie T a rozptyl D- neznámy. Pre tieto parametre sa získali nasledujúce odhady:

Je potrebné zostrojiť interval spoľahlivosti / p zodpovedajúci pravdepodobnosti spoľahlivosti p pre matematické očakávanie T množstvá X.
Pri riešení tohto problému využijeme fakt, že množstvo T predstavuje súčet P nezávislé identicky rozdelené náhodné premenné X h a podľa centrálnej limitnej vety pre dostatočne veľkú P jeho distribučný zákon je blízky normálu. V praxi aj pri relatívne malom počte členov (asi 10...20) možno distribučný zákon súčtu považovať približne za normálny. Budeme predpokladať, že hodnota T distribuované podľa bežného zákona. Charakteristiky tohto zákona – matematické očakávanie a rozptyl – sa rovnajú, resp T A
(pozri kapitolu 13 pododdiel 13.3). Predpokladajme, že hodnota D poznáme a nájdeme hodnotu Ep, pre ktorú
Pomocou vzorca (6.3.5) z kapitoly 6 vyjadríme pravdepodobnosť na ľavej strane (14.3.5) prostredníctvom funkcie normálneho rozdelenia
kde je štandardná odchýlka odhadu T.
Z rov.

nájdite hodnotu Sp: 
kde arg Ф* (х) je inverzná funkcia Ф* (X), tie. taká hodnota argumentu, pre ktorú sa funkcia normálneho rozdelenia rovná X.
Disperzia D, prostredníctvom ktorého sa množstvo vyjadruje A 1P, nevieme presne; ako jeho približnú hodnotu môžete použiť odhad D(14.3.4) a uveďte približne:

Problém konštrukcie intervalu spoľahlivosti bol teda približne vyriešený, čo sa rovná:
kde gp je určené vzorcom (14.3.7).
Aby sa predišlo spätnej interpolácii v tabuľkách funkcie Ф* (l) pri výpočte s p, je vhodné zostaviť špeciálnu tabuľku (tabuľka 14.3.1), ktorá udáva hodnoty množstva
v závislosti od r. Hodnota (p určuje pre normálny zákon počet smerodajných odchýlok, ktoré je potrebné vykresliť vpravo a vľavo od stredu disperzie tak, aby pravdepodobnosť vstupu do výslednej oblasti bola rovná p.
Pomocou hodnoty 7 p je interval spoľahlivosti vyjadrený ako:

Tabuľka 14.3.1
Príklad 1. Uskutočnilo sa 20 experimentov s množstvom X; výsledky sú uvedené v tabuľke. 14.3.2.
Tabuľka 14.3.2
Je potrebné nájsť odhad z pre matematické očakávanie množstva X a zostrojte interval spoľahlivosti zodpovedajúci pravdepodobnosti spoľahlivosti p = 0,8.
Riešenie. Máme:

Ak ako referenčný bod zvolíme l: = 10, pomocou tretieho vzorca (14.2.14) nájdeme nezaujatý odhad D :

Podľa tabuľky 14.3.1 nájdeme ![]()
![]()
Hranice spoľahlivosti:

Interval spoľahlivosti:
![]()
Hodnoty parametrov T, ležiace v tomto intervale sú kompatibilné s experimentálnymi údajmi uvedenými v tabuľke. 14.3.2.
Interval spoľahlivosti pre rozptyl možno zostrojiť podobným spôsobom.
Nech sa vyrába P nezávislé experimenty na náhodnej premennej X s neznámymi parametrami pre A aj disperziu D bol získaný nestranný odhad:


Je potrebné približne zostrojiť interval spoľahlivosti pre rozptyl.
Zo vzorca (14.3.11) je zrejmé, že množstvo D predstavuje
čiastka P náhodné premenné formulára . Tieto hodnoty nie sú
nezávislé, pretože ktorýkoľvek z nich zahŕňa množstvo T, závislý na všetkých ostatných. Dá sa však ukázať, že s pribúdajúcimi P distribučný zákon ich súčtu sa tiež blíži k normálu. Takmer o P= 20...30 to už možno považovať za normálne.
Predpokladajme, že je to tak, a nájdime charakteristiky tohto zákona: matematické očakávanie a rozptyl. Od hodnotenia D- teda nezaujatý M[D] = D.
Výpočet rozptylu D D je spojená s pomerne zložitými výpočtami, preto uvádzame jej vyjadrenie bez odvodenia:
kde q 4 je štvrtý centrálny moment veľkosti X.
Ak chcete použiť tento výraz, musíte nahradiť hodnoty \u003d 4 a D(aspoň blízkych). Namiesto D môžete použiť jeho hodnotenie D. V zásade môže byť štvrtý centrálny moment nahradený aj odhadom, napríklad hodnotou tvaru:

ale takáto náhrada poskytne extrémne nízku presnosť, pretože vo všeobecnosti sa pri obmedzenom počte experimentov určujú momenty vysokého rádu s veľkými chybami. V praxi sa však často stáva, že typ rozdelenia množstva zákon X vopred známy: neznáme sú len jeho parametre. Potom sa môžete pokúsiť vyjadriť μ 4 prostredníctvom D.
Zoberme si najbežnejší prípad, kedy je hodnota X distribuované podľa bežného zákona. Potom je jeho štvrtý centrálny moment vyjadrený rozptylom (pozri kapitolu 6, pododdiel 6.2);
![]()
a vzorec (14.3.12) dáva  alebo
alebo
Nahradenie neznámeho v (14.3.14) D jeho hodnotenie D, dostaneme: odkiaľ 
Moment μ 4 možno vyjadriť cez D aj v niektorých iných prípadoch, keď rozdelenie hodnoty X nie je normálne, ale jeho vzhľad je známy. Napríklad pre zákon rovnomernej hustoty (pozri kapitolu 5) máme: 
kde (a, P) je interval, na ktorom je zákon špecifikovaný.
teda
![]()
Pomocou vzorca (14.3.12) dostaneme:  kde približne nájdeme
kde približne nájdeme
V prípadoch, keď nie je známy typ rozdeľovacieho zákona pre veličinu 26, pri približnom odhade hodnoty a/) sa stále odporúča použiť vzorec (14.3.16), pokiaľ neexistujú osobitné dôvody domnievať sa, že tento zákon sa veľmi líši od bežného (má znateľné kladné alebo záporné špičky).
Ak sa približná hodnota a/) získa tak či onak, potom môžeme zostrojiť interval spoľahlivosti pre rozptyl rovnakým spôsobom, ako sme ho vytvorili pre matematické očakávanie:
kde hodnotu závislú od danej pravdepodobnosti p nájdeme podľa tabuľky. 14.3.1.
Príklad 2. Nájdite približne 80 % interval spoľahlivosti pre rozptyl náhodnej premennej X za podmienok príkladu 1, ak je známe, že hodnota X distribuované podľa zákona blízkeho normálu.
Riešenie. Hodnota zostáva rovnaká ako v tabuľke. 14.3.1:
![]()
Podľa vzorca (14.3.16)

Pomocou vzorca (14.3.18) nájdeme interval spoľahlivosti:
![]()
Zodpovedajúci rozsah hodnôt štandardnej odchýlky: (0,21; 0,29).
14.4. Presné metódy konštrukcie intervalov spoľahlivosti pre parametre náhodnej premennej distribuovanej podľa normálneho zákona
V predchádzajúcej podkapitole sme skúmali približne približné metódy konštrukcie intervalov spoľahlivosti pre matematické očakávania a rozptyl. Tu poskytneme predstavu o presných metódach riešenia rovnakého problému. Zdôrazňujeme, že pre presné nájdenie intervalov spoľahlivosti je bezpodmienečne nutné vopred poznať formu distribučného zákona množstva X, pričom pre aplikáciu približných metód to nie je potrebné.
Myšlienka presných metód na zostavenie intervalov spoľahlivosti vychádza z nasledujúceho. Akýkoľvek interval spoľahlivosti sa zistí z podmienky vyjadrujúcej pravdepodobnosť splnenia určitých nerovností, medzi ktoré patrí aj odhad, ktorý nás zaujíma A. Zákon rozdelenia ocenenia A vo všeobecnom prípade závisí od neznámych parametrov veličiny X. Niekedy je však možné prejsť v nerovnostiach z náhodnej premennej A na nejakú inú funkciu pozorovaných hodnôt X p X 2, ..., X str. ktorého distribučný zákon nezávisí od neznámych parametrov, ale závisí len od počtu pokusov a od typu distribučného zákona veličiny X. Tieto druhy náhodných premenných hrajú dôležitú úlohu v matematickej štatistike; boli najpodrobnejšie študované pre prípad normálneho rozdelenia množstva X.
Napríklad je dokázané, že pri normálnom rozdelení hodnoty X náhodná hodnota

podriaďuje sa tzv Zákon o distribúcii študentov s P- 1 stupeň voľnosti; hustota tohto zákona má tvar

kde G(x) je známa funkcia gama:

Bolo tiež dokázané, že náhodná premenná
má „distribúciu %2“ s P- 1 stupeň voľnosti (pozri kapitolu 7), ktorého hustota je vyjadrená vzorcom

Bez toho, aby sme sa zaoberali deriváciami rozdelení (14.4.2) a (14.4.4), ukážeme, ako ich možno použiť pri konštrukcii intervalov spoľahlivosti pre parametre ty D.
Nech sa vyrába P nezávislé experimenty na náhodnej premennej X, normálne distribuované s neznámymi parametrami T&O. Pre tieto parametre boli získané odhady

Je potrebné zostrojiť intervaly spoľahlivosti pre oba parametre zodpovedajúce pravdepodobnosti spoľahlivosti p.
Najprv zostrojme interval spoľahlivosti pre matematické očakávanie. Je prirodzené brať tento interval symetrický vzhľadom na T; nech s p označuje polovicu dĺžky intervalu. Hodnota s p musí byť zvolená tak, aby bola podmienka splnená
Skúsme sa presunúť na ľavú stranu rovnosti (14.4.5) od náhodnej premennej T na náhodnú premennú T, distribuované podľa študentského zákona. Ak to chcete urobiť, vynásobte obe strany nerovnosti |m-w?|
kladnou hodnotou:  alebo pomocou zápisu (14.4.1),
alebo pomocou zápisu (14.4.1),

Nájdite číslo / p také, aby sa hodnota / p dala nájsť z podmienky

Zo vzorca (14.4.2) je zrejmé, že (1) je párna funkcia, preto (14.4.8) dáva 
Rovnosť (14.4.9) určuje hodnotu / p v závislosti od p. Ak máte k dispozícii tabuľku integrálnych hodnôt

potom hodnotu /p je možné nájsť reverznou interpoláciou v tabuľke. Je však pohodlnejšie vopred zostaviť tabuľku hodnôt /p. Takáto tabuľka je uvedená v prílohe (tabuľka 5). Táto tabuľka zobrazuje hodnoty v závislosti od úrovne spoľahlivosti p a počtu stupňov voľnosti P- 1. Po určení / p z tabuľky. 5 a za predpokladu 
nájdeme polovičnú šírku intervalu spoľahlivosti / p a samotný interval
Príklad 1. Uskutočnilo sa 5 nezávislých experimentov s náhodnou premennou X, normálne distribuované s neznámymi parametrami T a o. Výsledky experimentov sú uvedené v tabuľke. 14.4.1.
Tabuľka 14.4.1
Nájsť hodnotenie T pre matematické očakávanie a zostrojte preň 90 % interval spoľahlivosti / p (t. j. interval zodpovedajúci pravdepodobnosti spoľahlivosti p = 0,9).
Riešenie. Máme:
![]()
Podľa tabuľky 5 žiadosti o P - 1 = 4 a p = 0,9 nájdeme ![]() kde
kde 
Interval spoľahlivosti bude
Príklad 2. Pre podmienky príkladu 1 pododdielu 14.3, za predpokladu hodnoty X normálne rozložené, nájdite presný interval spoľahlivosti.
Riešenie. Podľa tabuľky 5 v prílohe zistíme kedy P - 1 = 19ir =
0,8 / p = 1,328; odtiaľ 
V porovnaní s riešením z príkladu 1 pododdielu 14.3 (e p = 0,072) sme presvedčení, že nezrovnalosť je veľmi nevýznamná. Ak zachováme presnosť na dve desatinné miesta, potom sa intervaly spoľahlivosti zistené presnou a približnou metódou zhodujú:
![]()
Prejdime ku konštrukcii intervalu spoľahlivosti pre rozptyl. Zvážte nezaujatý odhad rozptylu

a vyjadriť náhodnú premennú D cez veľkosť V(14.4.3), s rozdelením x 2 (14.4.4):

Poznať zákon rozdelenia množstva V, môžete nájsť interval /(1), do ktorého spadá s danou pravdepodobnosťou p.
Zákon distribúcie kn_x(v) magnitúda I7 má tvar znázornený na obr. 14.4.1.

Ryža. 14.4.1
Vynára sa otázka: ako zvoliť interval / p? Ak zákon rozdelenia vel V bol symetrický (ako normálny zákon alebo Studentovo rozdelenie), bolo by prirodzené brať interval /p symetrický vzhľadom na matematické očakávanie. V tomto prípade zákon k p_x (v) asymetrické. Dohodnime sa, že zvolíme interval /p tak, aby pravdepodobnosť hodnoty bola V za intervalom vpravo a vľavo (tieňované oblasti na obr. 14.4.1) boli rovnaké a rovnaké

Na vytvorenie intervalu /p s touto vlastnosťou použijeme tabuľku. 4 aplikácie: obsahuje čísla y) také že
![]()
za hodnotu V, s x 2 -distribúciou s r stupňami voľnosti. V našom prípade r = n- 1. Poďme opraviť r = n- 1 a nájdite v príslušnom riadku tabuľky. 4 dva významy x 2 - jeden zodpovedá pravdepodobnosti druhý - pravdepodobnosť Označme tieto
hodnoty o 2 A xl? Interval má y 2,ľavou stranou a y ~ pravý koniec.
Teraz nájdime z intervalu / p požadovaný interval spoľahlivosti /| pre disperziu s hranicami D, a D2, ktorý pokrýva pointu D s pravdepodobnosťou p: ![]()
Zostrojme interval / (, = (?> ь А), ktorý pokrýva bod D vtedy a len vtedy, ak hodnota V spadá do intervalu /r. Ukážme, že interval

spĺňa túto podmienku. Pravdaže, nerovnosti  sú ekvivalentné nerovnostiam
sú ekvivalentné nerovnostiam
![]()
a tieto nerovnosti sa uspokoja s pravdepodobnosťou p. Interval spoľahlivosti pre rozptyl bol teda nájdený a je vyjadrený vzorcom (14.4.13).
Príklad 3. Nájdite interval spoľahlivosti pre rozptyl za podmienok príkladu 2 pododdielu 14.3, ak je známe, že hodnota X normálne distribuované.
Riešenie. Máme ![]() . Podľa tabuľky 4 prílohy
. Podľa tabuľky 4 prílohy
nájdeme na r = n - 1 = 19

Pomocou vzorca (14.4.13) nájdeme interval spoľahlivosti pre rozptyl ![]()
Zodpovedajúci interval pre štandardnú odchýlku je (0,21; 0,32). Tento interval len mierne presahuje interval (0,21; 0,29) získaný v príklade 2 pododdielu 14.3 približnou metódou.
- Obrázok 14.3.1 uvažuje interval spoľahlivosti symetrický okolo a. Vo všeobecnosti, ako uvidíme neskôr, to nie je potrebné.
Cieľ– naučiť študentov algoritmy na výpočet intervalov spoľahlivosti štatistických parametrov.
Pri štatistickom spracovaní údajov by vypočítaný aritmetický priemer, variačný koeficient, korelačný koeficient, rozdielové kritériá a ďalšie bodové štatistiky mali dostať kvantitatívne medze spoľahlivosti, ktoré naznačujú možné výkyvy ukazovateľa v menšom a väčšom smere v rámci intervalu spoľahlivosti.
Príklad 3.1
.
Distribúcia vápnika v krvnom sére opíc, ako už bolo stanovené, je charakterizovaná nasledujúcimi ukazovateľmi vzorky: = 11,94 mg%;  = 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (
= 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (  ) s pravdepodobnosťou spoľahlivosti P
= 0,95.
) s pravdepodobnosťou spoľahlivosti P
= 0,95.
Všeobecný priemer sa s určitou pravdepodobnosťou nachádza v intervale:
 , Kde
, Kde 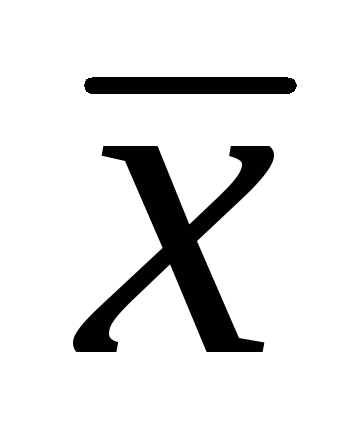 – vzorový aritmetický priemer; t- študentský test;
– vzorový aritmetický priemer; t- študentský test;  – chyba aritmetického priemeru.
– chyba aritmetického priemeru.
Pomocou tabuľky „Hodnoty študentského t-testu“ nájdeme hodnotu
 s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100-1 = 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100-1 = 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
alebo 11.69  12,19
12,19
S pravdepodobnosťou 95 % teda možno konštatovať, že všeobecný priemer tohto normálneho rozdelenia je medzi 11,69 a 12,19 mg %.
Príklad 3.2
. Určite hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl (  ) distribúcia vápnika v krvi opíc, ak je známe, že
) distribúcia vápnika v krvi opíc, ak je známe, že  = 1,60, at n
= 100.
= 1,60, at n
= 100.
Na vyriešenie problému môžete použiť nasledujúci vzorec:
Kde  – štatistická chyba rozptylu.
– štatistická chyba rozptylu.
Chybu výberového rozptylu nájdeme pomocou vzorca:  . Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
. Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
Použime vzorec a získame:
alebo 1,38  1,82
1,82
Presnejšie, interval spoľahlivosti všeobecného rozptylu možno zostrojiť pomocou  (chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria
(chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria  Na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta pomocou vzorca
Na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta pomocou vzorca  , na začiatok -
, na začiatok -  . Napríklad pre úroveň spoľahlivosti
. Napríklad pre úroveň spoľahlivosti  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Teda podľa tabuľky rozdelenia kritických hodnôt
= 0,990. Teda podľa tabuľky rozdelenia kritických hodnôt  s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty
s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty  A
A  . Dostaneme
. Dostaneme  rovná sa 135,80 a
rovná sa 135,80 a  rovná sa 70,06.
rovná sa 70,06.
Na nájdenie limitov spoľahlivosti pre všeobecný rozptyl pomocou  Použime vzorce: pre dolnú hranicu
Použime vzorce: pre dolnú hranicu 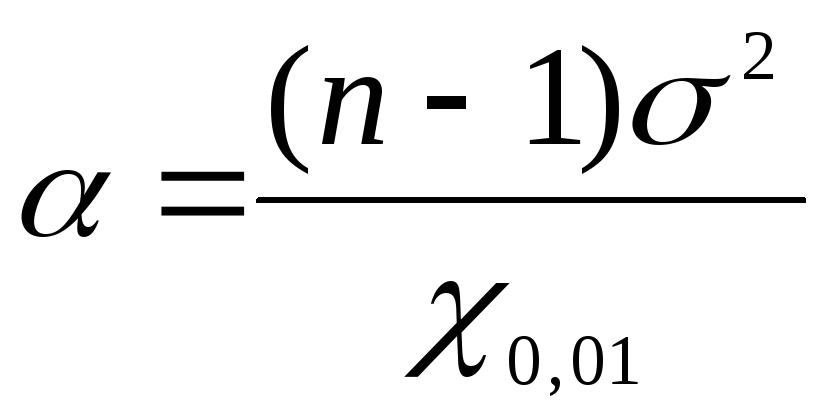 , pre hornú hranicu
, pre hornú hranicu  . Nahraďte nájdené hodnoty za problémové údaje
. Nahraďte nájdené hodnoty za problémové údaje  do vzorcov:
do vzorcov:  =
1,17;
=
1,17; = 2,26. Teda s pravdepodobnosťou spoľahlivosti P= 0,99 alebo 99 % všeobecný rozptyl bude ležať v rozsahu od 1,17 do 2,26 mg %, vrátane.
= 2,26. Teda s pravdepodobnosťou spoľahlivosti P= 0,99 alebo 99 % všeobecný rozptyl bude ležať v rozsahu od 1,17 do 2,26 mg %, vrátane.
Príklad 3.3 . Medzi 1000 semenami pšenice z dávky prijatej vo výťahu sa našlo 120 semien infikovaných námeľom. Je potrebné určiť pravdepodobné hranice všeobecného podielu infikovaných semien v danej partii pšenice.
Odporúča sa určiť limity spoľahlivosti pre všeobecný podiel pre všetky jeho možné hodnoty pomocou vzorca:
 ,
,
Kde n – počet pozorovaní; m– absolútna veľkosť jednej zo skupín; t– normalizovaná odchýlka.
Vzorkový podiel infikovaných semien je  alebo 12 %. S pravdepodobnosťou istoty R= 95 % normalizovaná odchýlka ( t-Skúška študenta o hod k
=
alebo 12 %. S pravdepodobnosťou istoty R= 95 % normalizovaná odchýlka ( t-Skúška študenta o hod k
=
 )t
= 1,960.
)t
= 1,960.
Dostupné údaje dosadíme do vzorca:
Hranice intervalu spoľahlivosti sa teda rovnajú  = 0,122–0,041 = 0,081 alebo 8,1 %;
= 0,122–0,041 = 0,081 alebo 8,1 %;  = 0,122 + 0,041 = 0,163 alebo 16,3 %.
= 0,122 + 0,041 = 0,163 alebo 16,3 %.
S pravdepodobnosťou spoľahlivosti 95 % možno teda konštatovať, že všeobecný podiel infikovaných semien je medzi 8,1 a 16,3 %.
Príklad 3.4 . Variačný koeficient charakterizujúci variáciu vápnika (mg %) v krvnom sére opíc bol rovný 10,6 %. Veľkosť vzorky n= 100. Je potrebné určiť hranice 95 % intervalu spoľahlivosti pre všeobecný parameter Životopis.
Hranice intervalu spoľahlivosti pre všeobecný variačný koeficient Životopis sa určujú podľa nasledujúcich vzorcov:
 A
A  , Kde K
medzihodnota vypočítaná podľa vzorca
, Kde K
medzihodnota vypočítaná podľa vzorca  .
.
Vedieť to s istou pravdepodobnosťou R= 95 % normalizovaná odchýlka (študentský test pri k
=
 )t
= 1,960, najprv vypočítajme hodnotu KOMU:
)t
= 1,960, najprv vypočítajme hodnotu KOMU:
 .
.
 alebo 9,3 %
alebo 9,3 %
 alebo 12,3 %
alebo 12,3 %
Všeobecný variačný koeficient s 95 % úrovňou spoľahlivosti teda leží v rozsahu od 9,3 do 12,3 %. Pri opakovaných vzorkách variačný koeficient nepresiahne 12,3 % a nebude nižší ako 9,3 % v 95 prípadoch zo 100.
Otázky na sebaovládanie:

Problémy na samostatné riešenie.
1. Priemerné percento tuku v mlieku počas laktácie kráv krížencov Kholmogory bolo nasledovné: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Stanovte intervaly spoľahlivosti pre všeobecný priemer na úrovni spoľahlivosti 95 % (20 bodov).
2. Na 400 hybridných rastlinách raže sa prvé kvety objavili v priemere 70,5 dňa po zasiatí. Štandardná odchýlka bola 6,9 dňa. Určte chybu priemeru a intervalu spoľahlivosti pre všeobecný priemer a rozptyl na hladine významnosti W= 0,05 a W= 0,01 (25 bodov).
3. Pri štúdiu dĺžky listov 502 exemplárov záhradných jahôd sa získali tieto údaje:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  =± 0,06 cm Stanovte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
=± 0,06 cm Stanovte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
4. V štúdii 150 dospelých mužov bola priemerná výška 167 cm, a σ = 6 cm Aké sú hranice všeobecného priemeru a všeobecného rozptylu s pravdepodobnosťou spoľahlivosti 0,99 a 0,95? (25 bodov).
5. Distribúciu vápnika v krvnom sére opíc charakterizujú tieto selektívne ukazovatele:
 = 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte 95 % interval spoľahlivosti pre všeobecný priemer tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
= 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte 95 % interval spoľahlivosti pre všeobecný priemer tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
6. Bol študovaný celkový obsah dusíka v krvnej plazme potkanov albínov vo veku 37 a 180 dní. Výsledky sú vyjadrené v gramoch na 100 cm 3 plazmy. Vo veku 37 dní malo 9 potkanov: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Vo veku 180 dní malo 8 potkanov: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Nastavte intervaly spoľahlivosti pre rozdiel na úrovni spoľahlivosti 0,95 (50 bodov).
7. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie vápnika (mg %) v krvnom sére opíc, ak pre toto rozdelenie je veľkosť vzorky n = 100, štatistická chyba rozptylu vzorky s σ 2 = 1,60 (40 bodov).
8. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie 40 pšeničných kláskov pozdĺž dĺžky (σ 2 = 40,87 mm 2). (25 bodov).
9. Fajčenie sa považuje za hlavný faktor predisponujúci k obštrukčným chorobám pľúc. Pasívne fajčenie sa za takýto faktor nepovažuje. Vedci pochybovali o neškodnosti pasívneho fajčenia a skúmali priechodnosť dýchacích ciest u nefajčiarov, pasívnych a aktívnych fajčiarov. Na charakterizáciu stavu dýchacieho traktu sme vzali jeden z ukazovateľov funkcie vonkajšieho dýchania - maximálny objemový prietok v strede výdychu. Zníženie tohto indikátora je znakom obštrukcie dýchacích ciest. Údaje z prieskumu sú uvedené v tabuľke.
|
Počet vyšetrených ľudí |
Maximálny stredný výdychový prietok, l/s |
||
|
Smerodajná odchýlka |
|||
|
Nefajčiari |
|||
|
práca v nefajčiarskom priestore | |||
|
práca v zadymenej miestnosti | |||
|
Fajčenie |
|||
|
fajčiť malé množstvo cigariet | |||
|
priemerný počet fajčiarov cigariet | |||
|
fajčiť veľké množstvo cigariet | |||
Pomocou údajov z tabuľky nájdite 95 % intervaly spoľahlivosti pre celkový priemer a celkový rozptyl pre každú skupinu. Aké sú rozdiely medzi skupinami? Výsledky prezentujte graficky (25 bodov).
10. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný rozptyl v počte prasiatok v 64 prasiatkach, ak štatistická chyba rozptylu vzorky s σ 2 = 8,25 (30 bodov).
11. Je známe, že priemerná hmotnosť králikov je 2,1 kg. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný priemer a rozptyl pri n= 30, σ = 0,56 kg (25 bodov).
12. Obsah zŕn klasu bol nameraný pre 100 klasov ( X), dĺžka ucha ( Y) a hmotnosť zrna v klase ( Z). Nájdite intervaly spoľahlivosti pre všeobecný priemer a rozptyl pri P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 ak
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064. (25 bodov).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2, 111, σ z 2 = 0, 064. (25 bodov).
13. V 100 náhodne vybraných klasoch ozimnej pšenice bol spočítaný počet kláskov. Vzorová populácia bola charakterizovaná nasledujúcimi ukazovateľmi:
 = 15 kláskov a σ = 2,28 ks. Určite, s akou presnosťou sa získal priemerný výsledok (
= 15 kláskov a σ = 2,28 ks. Určite, s akou presnosťou sa získal priemerný výsledok (  ) a zostrojte interval spoľahlivosti pre všeobecný priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
) a zostrojte interval spoľahlivosti pre všeobecný priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
14. Počet rebier na schránkach fosílnych mäkkýšov Ortambonity kaligrama:
To je známe n = 19, σ = 4,25. Určte hranice intervalu spoľahlivosti pre všeobecný priemer a všeobecný rozptyl na hladine významnosti W = 0,01 (25 bodov).
15. Na stanovenie dojivosti na komerčnej mliečnej farme bola denne stanovená úžitkovosť 15 kráv. Podľa údajov za rok dávala každá krava v priemere za deň nasledovné množstvo mlieka (l): 22; 19; 25; 20; 27; 17; tridsať; 21; 18; 24; 26; 23; 25; 20; 24. Zostrojte intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Môžeme očakávať priemernú ročnú dojivosť na kravu 10 000 litrov? (50 bodov).
16. Na zistenie priemernej úrody pšenice pre poľnohospodársky podnik bola vykonaná kosba na skúšobných pozemkoch o výmere 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 a 2 hektáre. Produktivita (c/ha) z pozemkov bola 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 resp. Zostrojte intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Dá sa očakávať, že priemerný poľnohospodársky výnos bude 42 c/ha? (50 bodov).
V štatistike existujú dva typy odhadov: bodové a intervalové. Bodový odhad je štatistika jednej vzorky, ktorá sa používa na odhad parametra populácie. Napríklad priemer vzorky je bodový odhad matematického očakávania populácie a rozptylu vzorky S 2- bodový odhad rozptylu populácie σ 2. ukázalo sa, že priemer vzorky je nezaujatým odhadom matematických očakávaní populácie. Priemer vzorky sa nazýva nezaujatý, pretože priemer všetkých priemerov vzorky (s rovnakou veľkosťou vzorky) n) sa rovná matematickým očakávaniam bežnej populácie.
Aby sa vzorový rozptyl S 2 sa stal nezaujatým odhadom rozptylu populácie σ 2, menovateľ rozptylu vzorky by mal byť nastavený ako rovný n – 1 , ale nie n. Inými slovami, rozptyl populácie je priemer všetkých možných rozptylov vzorky.
Pri odhadovaní parametrov populácie treba mať na pamäti, že výberové štatistiky ako napr , závisí od konkrétnych vzoriek. Zohľadniť túto skutočnosť, získať intervalový odhad matematické očakávania všeobecnej populácie, analyzovať rozdelenie výberových priemerov (podrobnejšie pozri). Zostrojený interval je charakterizovaný určitou úrovňou spoľahlivosti, ktorá predstavuje pravdepodobnosť, že skutočný parameter populácie je odhadnutý správne. Podobné intervaly spoľahlivosti možno použiť na odhad podielu charakteristiky R a hlavná distribuovaná masa obyvateľstva.
Stiahnite si poznámku vo formáte alebo formáte, príklady vo formáte
Zostrojenie intervalu spoľahlivosti pre matematické očakávania populácie so známou smerodajnou odchýlkou
Zostrojenie intervalu spoľahlivosti pre podiel charakteristiky v populácii
Táto časť rozširuje pojem intervalu spoľahlivosti na kategorické údaje. To nám umožňuje odhadnúť podiel charakteristiky v populácii R pomocou zdieľania vzorky RS= X/n. Ako je uvedené, ak množstvá nR A n(1 – p) prekročiť číslo 5, binomické rozdelenie možno aproximovať ako normálne. Preto odhadnúť podiel charakteristiky v populácii R je možné zostrojiť interval, ktorého úroveň spoľahlivosti sa rovná (1 – α) x 100 %.

Kde pS- podiel vzorky charakteristiky rovný X/n, t.j. počet úspechov vydelený veľkosťou vzorky, R- podiel charakteristiky vo všeobecnej populácii, Z- kritická hodnota štandardizovaného normálneho rozdelenia, n- veľkosť vzorky.
Príklad 3 Predpokladajme, že z informačného systému je extrahovaný vzor pozostávajúci zo 100 faktúr vyplnených za posledný mesiac. Povedzme, že 10 z týchto faktúr bolo zostavených s chybami. teda R= 10/100 = 0,1. 95 % úroveň spoľahlivosti zodpovedá kritickej hodnote Z = 1,96.
Pravdepodobnosť, že 4,12 % až 15,88 % faktúr obsahuje chyby, je teda 95 %.
Pre danú veľkosť vzorky sa interval spoľahlivosti obsahujúci podiel charakteristiky v populácii javí širší ako pre spojitú náhodnú premennú. Je to preto, že merania spojitej náhodnej premennej obsahujú viac informácií ako merania kategorických údajov. Inými slovami, kategorické údaje, ktoré majú iba dve hodnoty, obsahujú nedostatočné informácie na odhad parametrov ich distribúcie.
INvýpočet odhadov extrahovaných z konečnej populácie
Odhad matematického očakávania. Korekčný faktor pre konečnú populáciu ( fpc) sa použil na zníženie štandardnej chyby o faktor. Pri výpočte intervalov spoľahlivosti pre odhady parametrov populácie sa v situáciách, keď sa vzorky odoberajú bez vrátenia, použije korekčný faktor. Interval spoľahlivosti pre matematické očakávanie, ktorý má úroveň spoľahlivosti rovnajúcu sa (1 – α) x 100 %, sa vypočíta podľa vzorca:

Príklad 4. Aby sme ilustrovali použitie korekčného faktora pre konečný súbor, vráťme sa k problému výpočtu intervalu spoľahlivosti pre priemernú sumu faktúr, diskutovanému vyššie v príklade 3. Predpokladajme, že spoločnosť vystavuje 5 000 faktúr mesačne a X= 110,27 dolárov, S= 28,95 USD, N = 5000, n = 100, α = 0,05, t99 = 1,9842. Pomocou vzorca (6) dostaneme:
Odhad podielu funkcie. Pri výbere bez vrátenia sa interval spoľahlivosti pre podiel atribútu s úrovňou spoľahlivosti rovná (1 – α) x 100 %, sa vypočíta podľa vzorca:

Intervaly dôvery a etické otázky
Pri vzorkovaní populácie a vyvodzovaní štatistických záverov často vznikajú etické problémy. Hlavným je, ako sa zhodujú intervaly spoľahlivosti a bodové odhady štatistických údajov vzorky. Publikovanie bodových odhadov bez špecifikovania súvisiacich intervalov spoľahlivosti (zvyčajne na úrovni spoľahlivosti 95 %) a veľkosti vzorky, z ktorej sú odvodené, môže spôsobiť zmätok. To môže v používateľovi vyvolať dojem, že bodový odhad je presne to, čo potrebuje na predpovedanie vlastností celej populácie. Preto je potrebné pochopiť, že v každom výskume by sa pozornosť nemala sústrediť na bodové odhady, ale na intervalové odhady. Okrem toho by sa mala venovať osobitná pozornosť správnemu výberu veľkostí vzoriek.
Objektom štatistickej manipulácie sú najčastejšie výsledky sociologických prieskumov obyvateľstva o určitých politických otázkach. Zároveň sú výsledky prieskumu zverejnené na titulných stranách novín a niekde v strede je zverejnená výberová chyba a metodika štatistickej analýzy. Na preukázanie validity získaných bodových odhadov je potrebné uviesť veľkosť vzorky, na základe ktorej boli získané, hranice intervalu spoľahlivosti a jeho hladinu významnosti.
Ďalšia poznámka
Používajú sa materiály z knihy Levin et al Štatistika pre manažérov. – M.: Williams, 2004. – s. 448–462
Centrálna limitná veta uvádza, že pri dostatočne veľkej veľkosti vzorky je možné aproximáciu priemernej distribúcie vzorky pomocou normálneho rozdelenia. Táto vlastnosť nezávisí od typu rozloženia obyvateľstva.
A ďalšie.Všetky sú to odhady ich teoretických analógov, ktoré by sa dali získať, keby nebola k dispozícii vzorka, ale všeobecná populácia. Ale bohužiaľ, bežná populácia je veľmi drahá a často nedostupná.
Pojem intervalového odhadu
Akýkoľvek odhad vzorky má určitý rozptyl, pretože je náhodná premenná v závislosti od hodnôt v konkrétnej vzorke. Preto pre spoľahlivejšie štatistické závery treba poznať nielen bodový odhad, ale aj interval, ktorý s vysokou pravdepodobnosťou γ (gama) pokrýva hodnotený ukazovateľ θ (theta).
Formálne sú to dve takéto hodnoty (štatistika) T 1 (X) A T 2 (X), Čo T 1< T 2 , pre ktoré pri danej úrovni pravdepodobnosti γ podmienka je splnená:
Je to skrátka pravdepodobné γ alebo viac skutočný ukazovateľ je medzi bodmi T 1 (X) A T 2 (X), ktoré sa nazývajú dolná a horná hranica interval spoľahlivosti.
Jednou z podmienok konštrukcie intervalov spoľahlivosti je jeho maximálna úzka, t.j. mala by byť čo najkratšia. Túžba je celkom prirodzená, pretože... výskumník sa snaží presnejšie lokalizovať umiestnenie požadovaného parametra.
Z toho vyplýva, že interval spoľahlivosti musí pokrývať maximálne pravdepodobnosti rozdelenia. a samotné hodnotenie by malo byť v centre.
![]()
To znamená, že pravdepodobnosť odchýlky (skutočného ukazovateľa od odhadu) smerom nahor sa rovná pravdepodobnosti odchýlky smerom nadol. Treba tiež poznamenať, že pre asymetrické distribúcie sa interval vpravo nerovná intervalu vľavo.
Vyššie uvedený obrázok jasne ukazuje, že čím väčšia je pravdepodobnosť spoľahlivosti, tým širší je interval - priamy vzťah.
Toto bol krátky úvod do teórie intervalového odhadu neznámych parametrov. Prejdime k hľadaniu hraníc spoľahlivosti pre matematické očakávania.
Interval spoľahlivosti pre matematické očakávania
Ak sú pôvodné údaje rozdelené na , priemer bude normálna hodnota. Vyplýva to z pravidla, že lineárna kombinácia normálnych hodnôt má tiež normálne rozdelenie. Preto by sme na výpočet pravdepodobností mohli použiť matematický aparát zákona normálneho rozdelenia.
To si však bude vyžadovať poznať dva parametre – očakávanie a rozptyl, ktoré sú zvyčajne neznáme. Namiesto parametrov môžete samozrejme použiť odhady (aritmetický priemer a ), ale potom rozdelenie priemeru nebude úplne normálne, bude mierne sploštené smerom nadol. Túto skutočnosť si šikovne všimol občan William Gosset z Írska, ktorý svoj objav zverejnil v marci 1908 v časopise Biometrica. Pre účely utajenia sa Gosset podpísal ako Študent. Takto sa objavilo Studentovo t-rozdelenie.
Normálna distribúcia údajov, ktorú používa K. Gauss pri analýze chýb v astronomických pozorovaniach, je však v pozemskom živote extrémne vzácna a je dosť ťažké ju stanoviť (na vysokú presnosť je potrebných asi 2 000 pozorovaní). Preto je najlepšie zahodiť predpoklad normality a použiť metódy, ktoré nezávisia od distribúcie pôvodných údajov.
Vzniká otázka: aké je rozdelenie aritmetického priemeru, ak sa vypočítava z údajov neznámeho rozdelenia? Odpoveď dáva dobre známe z teórie pravdepodobnosti Centrálna limitná veta(CPT). V matematike existuje niekoľko jeho variantov (formulácie sa v priebehu rokov zdokonaľovali), ale všetky sa, zhruba povedané, scvrkávali na konštatovanie, že súčet veľkého počtu nezávislých náhodných premenných sa riadi zákonom normálneho rozdelenia.
Pri výpočte aritmetického priemeru sa používa súčet náhodných premenných. Odtiaľto sa ukazuje, že aritmetický priemer má normálne rozdelenie, v ktorom je očakávanie očakávaním pôvodných údajov a rozptyl je .
Chytrí ľudia vedia dokázať CLT, ale my si to overíme pomocou experimentu v Exceli. Simulujme vzorku 50 rovnomerne rozdelených náhodných premenných (pomocou excelovej funkcie RANDBETWEEN). Potom urobíme 1000 takýchto vzoriek a pre každú vypočítame aritmetický priemer. Pozrime sa na ich distribúciu.

Je vidieť, že rozdelenie priemeru sa blíži normálnemu zákonu. Ak sa veľkosť a počet vzorky ešte zväčšia, podobnosť bude ešte lepšia.
Teraz, keď sme na vlastné oči videli platnosť CLT, môžeme pomocou , vypočítať intervaly spoľahlivosti pre aritmetický priemer, ktoré pokrývajú skutočný priemer alebo matematické očakávania s danou pravdepodobnosťou.
Na stanovenie hornej a dolnej hranice potrebujete poznať parametre normálneho rozdelenia. Spravidla neexistujú žiadne, preto sa používajú odhady: aritmetický priemer A rozptyl vzorky. Opakujem, táto metóda poskytuje dobrú aproximáciu iba pri veľkých vzorkách. Keď sú vzorky malé, často sa odporúča použiť študentskú distribúciu. Neverte tomu! Študentská distribúcia pre priemer sa vyskytuje iba vtedy, keď sú pôvodné údaje normálne rozdelené, teda takmer nikdy. Preto je lepšie okamžite nastaviť minimálnu hranicu pre množstvo požadovaných údajov a použiť asymptoticky správne metódy. Hovorí sa, že stačí 30 pozorovaní. Vezmite 50 - nič nepokazíte.
![]()
T 1.2– spodná a horná hranica intervalu spoľahlivosti
– vzorový aritmetický priemer
s 0– štandardná odchýlka vzorky (nezaujatá)
n - veľkosť vzorky
γ – pravdepodobnosť spoľahlivosti (zvyčajne sa rovná 0,9, 0,95 alebo 0,99)
c γ =Φ -1 ((1+γ)/2)– prevrátená hodnota funkcie štandardného normálneho rozdelenia. Jednoducho povedané, ide o počet štandardných chýb od aritmetického priemeru po dolnú alebo hornú hranicu (tieto tri pravdepodobnosti zodpovedajú hodnotám 1,64, 1,96 a 2,58).
Podstatou vzorca je, že sa vezme aritmetický priemer a potom sa z neho vyčlení určitá čiastka ( s γ) štandardné chyby ( s 0 /√n). Všetko je známe, vezmite si to a zvážte to.
Pred rozšírením osobných počítačov sa používali na získavanie hodnôt normálnej distribučnej funkcie a jej inverznej funkcie. Používajú sa dodnes, ale efektívnejšie je použiť hotové vzorce Excelu. Všetky prvky z vyššie uvedeného vzorca ( , a ) možno jednoducho vypočítať v Exceli. Existuje však pripravený vzorec na výpočet intervalu spoľahlivosti - DÔVERUJTE.NORM. Jeho syntax je nasledovná.
CONFIDENCE.NORM(alfa;štandardné_vyp;veľkosť)
alfa– hladina významnosti alebo hladina spoľahlivosti, ktorá sa vo vyššie prijatom zápise rovná 1- γ, t.j. pravdepodobnosť, že matematickáočakávanie bude mimo intervalu spoľahlivosti. S úrovňou spoľahlivosti 0,95 je alfa 0,05 atď.
štandardné vypnutie– štandardná odchýlka údajov vzorky. Nie je potrebné počítať štandardnú chybu, samotný Excel bude deliť odmocninou z n.
veľkosť– veľkosť vzorky (n).
Výsledkom funkcie CONFIDENCE NORM je druhý člen zo vzorca na výpočet intervalu spoľahlivosti, t.j. polovičný interval V súlade s tým sú dolné a horné body priemer ± získaná hodnota.
Je teda možné skonštruovať univerzálny algoritmus na výpočet intervalov spoľahlivosti pre aritmetický priemer, ktorý nezávisí od distribúcie pôvodných údajov. Cenou za univerzálnosť je jej asymptotická povaha, t.j. nutnosť použiť relatívne veľké vzorky. V dobe moderných technológií však zhromaždenie potrebného množstva dát zvyčajne nie je zložité.
Testovanie štatistických hypotéz pomocou intervalov spoľahlivosti
(modul 111)
Jedným z hlavných problémov riešených v štatistike je. Jeho podstata je stručne nasledovná. Vychádza sa napríklad z predpokladu, že očakávanie bežnej populácie sa rovná nejakej hodnote. Potom sa skonštruuje distribúcia výberových prostriedkov, ktoré možno pozorovať pre dané očakávanie. Ďalej sa pozerajú na to, kde sa v tomto podmienenom rozdelení nachádza skutočný priemer. Ak to presiahne prijateľné hranice, potom je výskyt takéhoto priemeru veľmi nepravdepodobný a ak sa experiment zopakuje raz, je to takmer nemožné, čo je v rozpore s predloženou hypotézou, ktorá sa úspešne zamieta. Ak priemer neprekročí kritickú úroveň, hypotéza nie je zamietnutá (ale ani dokázaná!).
Takže pomocou intervalov spoľahlivosti, v našom prípade pre očakávanie, môžete otestovať aj niektoré hypotézy. Je to veľmi jednoduché. Povedzme, že aritmetický priemer pre určitú vzorku je rovný 100. Testuje sa hypotéza, že očakávaná hodnota je, povedzme, 90. To znamená, že ak otázku položíme primitívne, znie to takto: môže to byť pravda? hodnota priemeru rovná 90, zistený priemer sa ukázal byť 100?
Na zodpovedanie tejto otázky budete navyše potrebovať informácie o štandardnej odchýlke a veľkosti vzorky. Predpokladajme, že štandardná odchýlka je 30 a počet pozorovaní je 64 (aby sa ľahko extrahoval koreň). Potom je štandardná chyba priemeru 30/8 alebo 3,75. Na výpočet 95 % intervalu spoľahlivosti budete musieť pridať dve štandardné chyby na každú stranu priemeru (presnejšie 1,96). Interval spoľahlivosti bude približne 100±7,5 alebo od 92,5 do 107,5.
Ďalšie zdôvodnenie je nasledovné. Ak testovaná hodnota spadá do intervalu spoľahlivosti, potom to nie je v rozpore s hypotézou, pretože spadá do hraníc náhodných výkyvov (s pravdepodobnosťou 95 %). Ak sa kontrolovaný bod nachádza mimo intervalu spoľahlivosti, potom je pravdepodobnosť takejto udalosti veľmi malá, v každom prípade pod prijateľnou úrovňou. To znamená, že hypotéza je zamietnutá ako odporujúca pozorovaným údajom. V našom prípade je hypotéza o očakávanej hodnote mimo intervalu spoľahlivosti (testovaná hodnota 90 nie je zahrnutá v intervale 100±7,5), preto ju treba zamietnuť. Pri odpovedi na vyššie uvedenú primitívnu otázku by sa malo povedať: nie, nemôže, v žiadnom prípade sa to stáva veľmi zriedka. Často označujú špecifickú pravdepodobnosť chybného zamietnutia hypotézy (úroveň p), a nie špecifikovanú úroveň, na ktorej bol interval spoľahlivosti skonštruovaný, ale o tom inokedy.
Ako vidíte, zostavenie intervalu spoľahlivosti pre priemer (alebo matematické očakávania) nie je ťažké. Hlavná vec je pochopiť podstatu a potom sa veci pohnú ďalej. V praxi sa vo väčšine prípadov používa 95 % interval spoľahlivosti, čo je šírka približne dvoch štandardných chýb na oboch stranách priemeru.
To je zatiaľ všetko. Všetko najlepšie!