Usaldusintervallid. Usaldusvahemik
Ja teised.Kõik need on hinnangud oma teoreetiliste vastete kohta, mida saaks saada, kui poleks valimit, vaid üldkogumit. Kuid kahjuks on üldine elanikkond väga kallis ja sageli kättesaamatu.
Intervallhinnangu mõiste
Igal valimihinnangul on hajumine, sest on juhuslik suurus, mis sõltub konkreetse valimi väärtustest. Seetõttu peaks usaldusväärsemate statistiliste järelduste tegemiseks teadma mitte ainult punkthinnangut, vaid ka intervalli, mis suure tõenäosusega γ (gamma) katab hinnangulise näitaja θ (teeta).
Formaalselt on need kaks sellist väärtust (statistika) T1(X) Ja T2(X), Mida T1< T 2 , mille puhul etteantud tõenäosuse tasemel γ tingimus on täidetud:
Lühidalt, see on tõenäoline γ või rohkem on tegelik väärtus punktide vahel T1(X) Ja T2(X), mida nimetatakse alumiseks ja ülemiseks piiriks usaldusvahemik.
Usaldusvahemike konstrueerimise üheks tingimuseks on selle maksimaalne kitsus, s.o. see peaks olema võimalikult lühike. Soov on üsna loomulik, sest. uurija püüab soovitud parameetri leidu täpsemalt lokaliseerida.
Sellest järeldub, et usaldusvahemik peaks katma jaotuse maksimaalsed tõenäosused. ja skoor ise on kesksel kohal.
![]()
See tähendab, et (tõelise näitaja hinnangust) ülespoole kõrvalekaldumise tõenäosus on võrdne allapoole kõrvalekaldumise tõenäosusega. Samuti tuleb märkida, et kallutatud jaotuste korral ei ole parempoolne intervall võrdne vasakpoolse intervalliga.
Ülaltoodud joonis näitab selgelt, et mida suurem on usaldustase, seda laiem on intervall – otsene seos.
See oli väike sissejuhatus tundmatute parameetrite intervallide hindamise teooriasse. Liigume edasi matemaatilise ootuse usalduspiiride leidmise juurde.
Matemaatilise ootuse usaldusvahemik
Kui algandmed on jaotatud , on keskmine normaalväärtus. See tuleneb reeglist, et normaalväärtuste lineaarsel kombinatsioonil on ka normaaljaotus. Seetõttu võiksime tõenäosuste arvutamiseks kasutada normaaljaotuse seaduse matemaatilist aparaati.
See eeldab aga kahe parameetri – eeldatava väärtuse ja dispersiooni – tundmist, mida tavaliselt ei teata. Parameetrite (aritmeetiline keskmine ja ) asemel võib muidugi kasutada hinnanguid, kuid siis ei ole keskmise jaotus päris normaalne, see on veidi tasandatud. Iirimaa kodanik William Gosset pani selle fakti nutikalt tähele, kui avaldas oma avastuse 1908. aasta märtsikuu ajakirjas Biometrica. Saladuslikel eesmärkidel allkirjastas Gosset Studentiga. Nii tekkis Studenti t-jaotus.
Andmete normaaljaotus, mida K. Gauss kasutab astronoomiliste vaatluste vigade analüüsimisel, on aga maapealses elus äärmiselt haruldane ja seda on üsna raske kindlaks teha (suure täpsuse jaoks on vaja umbes 2 tuhat vaatlust). Seetõttu on kõige parem loobuda normaalsuse eeldusest ja kasutada meetodeid, mis ei sõltu algandmete jaotusest.
Tekib küsimus: milline on aritmeetilise keskmise jaotus, kui see arvutatakse tundmatu jaotuse andmetest? Vastuse annab tõenäosusteoorias hästi tuntud Keskpiiri teoreem(CPT). Matemaatikas on sellest mitu versiooni (koostised on aastate jooksul viimistletud), kuid kõik need taanduvad jämedalt öeldes väitele, et suure hulga sõltumatute juhuslike suuruste summa järgib normaaljaotuse seadust.
Aritmeetilise keskmise arvutamisel kasutatakse juhuslike suuruste summat. Sellest selgub, et aritmeetiline keskmine on normaaljaotusega, milles eeldatav väärtus on algandmete eeldatav väärtus ja dispersioon on .
Targad inimesed teavad, kuidas CLT-d tõestada, kuid meie kontrollime seda Excelis tehtud katse abil. Simuleerime 50 ühtlaselt jaotatud juhusliku muutuja valimit (Exceli funktsiooni RANDOMBETWEEN abil). Seejärel teeme 1000 sellist valimit ja arvutame igaühe aritmeetilise keskmise. Vaatame nende levikut.

On näha, et keskmise jaotus on normaalseadusele lähedane. Kui proovide maht ja nende arv veelgi suuremaks teha, on sarnasus veelgi parem.
Nüüd, kui oleme ise veendunud CLT kehtivuses, saame kasutades arvutada aritmeetilise keskmise usaldusvahemikud, mis katavad tegeliku keskmise või matemaatilise ootuse antud tõenäosusega.
Ülemise ja alumise piiri määramiseks on vaja teada normaaljaotuse parameetreid. Seetõttu ei kasutata neid reeglina hinnanguid: aritmeetiline keskmine Ja valimi dispersioon. Jällegi annab see meetod hea ligikaudse hinnangu ainult suurte proovide puhul. Kui valimid on väikesed, on sageli soovitatav kasutada Studenti jaotust. Ära usu! Studenti jaotus keskmise jaoks esineb ainult siis, kui algandmetel on normaaljaotus, st peaaegu mitte kunagi. Seetõttu on parem kohe seada nõutavate andmete hulga miinimumriba ja kasutada asümptootiliselt õigeid meetodeid. Nad ütlevad, et 30 vaatlusest piisab. Võtke 50 - te ei saa eksida.
![]()
T 1.2 on usaldusvahemiku alumine ja ülemine piir
– valimi aritmeetiline keskmine
s0– valimi standardhälve (erapooletu)
n - näidissuurus
γ – usaldustase (tavaliselt 0,9, 0,95 või 0,99)
c γ = Φ -1 ((1+γ)/2) on standardse normaaljaotuse funktsiooni pöördväärtus. Lihtsamalt öeldes on see standardvigade arv aritmeetilisest keskmisest alumise või ülemise piirini (näidatud kolm tõenäosust vastavad väärtustele 1,64, 1,96 ja 2,58).
Valemi olemus seisneb selles, et võetakse aritmeetiline keskmine ja siis jäetakse sellest teatud summa kõrvale ( koos γ-ga) standardvead ( s 0 /√n). Kõik on teada, võta ja loe.
Enne personaalarvutite massilist kasutamist kasutasid nad normaaljaotuse funktsiooni ja selle pöördfunktsiooni väärtuste saamiseks . Neid kasutatakse endiselt, kuid tõhusam on pöörduda valmis Exceli valemite poole. Kõiki ülaltoodud valemi elemente ( , ja ) saab Excelis hõlpsasti arvutada. Kuid usaldusvahemiku arvutamiseks on ka valmis valem - KONFIDENTSIOON NORM. Selle süntaks on järgmine.
CONFIDENCE NORM(alfa, standard_dev, suurus)
alfa– olulisuse tase ehk usaldusnivoo, mis ülaltoodud tähistuses võrdub 1-γ, s.o. tõenäosus, et matemaatilineootus jääb väljaspool usaldusvahemikku. Usaldustasemega 0,95 on alfa 0,05 ja nii edasi.
standard_off on näidisandmete standardhälve. Standardviga pole vaja arvutada, Excel jagab n-i juurega.
suurus– valimi suurus (n).
Funktsiooni CONFIDENCE.NORM tulemus on usaldusvahemiku arvutamise valemist teine liige, s.o. poolintervall. Vastavalt sellele on alumine ja ülemine punkt keskmine ± saadud väärtus.
Seega on võimalik aritmeetilise keskmise usaldusvahemike arvutamiseks ehitada universaalne algoritm, mis ei sõltu algandmete jaotusest. Universaalsuse hind on selle asümptootilisus, s.t. vajadus kasutada suhteliselt suuri proove. Moodsa tehnoloogia ajastul pole aga õige andmemahu kogumine enamasti keeruline.
Statistiliste hüpoteeside testimine usaldusintervalli abil
(moodul 111)
Üks peamisi statistikas lahendatavaid probleeme on. Lühidalt, selle olemus on see. Eeldatakse näiteks, et üldrahvastiku ootus võrdub mingi väärtusega. Seejärel konstrueeritakse valimi keskmiste jaotus, mida saab vaadelda antud ootusega. Järgmisena vaatame, kus selles tingimuslikus jaotuses asub reaalne keskmine. Kui see ületab lubatud piire, on sellise keskmise ilmumine väga ebatõenäoline ja ühe katse kordusega on see peaaegu võimatu, mis on vastuolus püstitatud hüpoteesiga, mis lükatakse edukalt tagasi. Kui keskmine ei ületa kriitilist piiri, siis hüpoteesi ei lükata (aga ka ei tõestata!).
Seega saate usaldusvahemike abil, meie puhul ootuse jaoks, testida ka mõningaid hüpoteese. Seda on väga lihtne teha. Oletame, et mõne valimi aritmeetiline keskmine on 100. Kontrollitakse hüpoteesi, et ootus on näiteks 90. See tähendab, et kui me esitame küsimuse primitiivselt, siis kõlab see järgmiselt: kas see võib olla nii, et selle tegelik väärtus on keskmine on võrdne 90, vaadeldud keskmine oli 100?
Sellele küsimusele vastamiseks on vaja täiendavat teavet standardhälbe ja valimi suuruse kohta. Oletame, et standardhälve on 30 ja vaatluste arv on 64 (juure hõlpsaks eraldamiseks). Siis on keskmise standardviga 30/8 ehk 3,75. 95% usaldusvahemiku arvutamiseks peate kõrvale jätma kaks standardviga mõlemal pool keskmist (täpsemalt 1,96). Usaldusvahemik on ligikaudu 100 ± 7,5 või 92,5 kuni 107,5.
Edasine põhjendus on järgmine. Kui testitav väärtus jääb usaldusvahemikku, siis ei ole see hüpoteesiga vastuolus, kuna mahub juhuslike kõikumiste piiridesse (tõenäosusega 95%). Kui testitav punkt on väljaspool usaldusvahemikku, siis on sellise sündmuse tõenäosus väga väike, igal juhul alla vastuvõetava taseme. Seetõttu lükatakse hüpotees tagasi, kuna see on vaadeldud andmetega vastuolus. Meie puhul on ootushüpotees väljaspool usaldusvahemikku (testitud väärtus 90 ei sisaldu intervallis 100±7,5), mistõttu tuleks see tagasi lükata. Ülaltoodud primitiivsele küsimusele vastates tuleks öelda: ei, see ei saa, igal juhul juhtub seda äärmiselt harva. Sageli viitab see hüpoteesi eksliku tagasilükkamise konkreetsele tõenäosusele (p-tase), mitte aga etteantud tasemele, mille järgi usaldusvahemik üles ehitati, vaid sellest mõni teine kord.
Nagu näete, pole keskmise (või matemaatilise ootuse) usaldusvahemiku koostamine keeruline. Peaasi on olemus tabada ja siis asjad lähevad. Praktikas kasutavad enamik 95% usaldusvahemikku, mis on umbes kahe standardvea laius mõlemal pool keskmist.
Praeguseks kõik. Kõike paremat!
Usaldusvahemike hindamine
Õppeeesmärgid
Statistika arvestab järgmist kaks peamist ülesannet:
Meil on näidisandmetel põhinev hinnang ja me tahame teha tõenäosusliku väite selle kohta, kus on hinnatava parameetri tegelik väärtus.
Meil on konkreetne hüpotees, mida tuleb prooviandmete põhjal testida.
Selles teemas käsitleme esimest probleemi. Tutvustame ka usaldusvahemiku määratlust.
Usaldusvahemik on intervall, mis on üles ehitatud parameetri hinnangulise väärtuse ümber ja näitab, kus hinnangulise parameetri tegelik väärtus on a priori antud tõenäosusega.
Pärast selle teema materjali uurimist:
õppida, milline on hinnangu usaldusvahemik;
õppida klassifitseerima statistilisi probleeme;
valdama usaldusvahemike konstrueerimise tehnikat, kasutades nii statistilisi valemeid kui ka tarkvaratööriistu;
õppida määrama vajalikke valimi suurusi, et saavutada statistiliste hinnangute täpsuse teatud parameetrid.
Valimi tunnuste jaotused
T-jaotus
Nagu eespool mainitud, on juhusliku suuruse jaotus lähedane standardiseeritud normaaljaotusele parameetritega 0 ja 1. Kuna me ei tea σ väärtust, asendame selle mõne hinnanguga s . Kogusel on juba erinev jaotus, nimelt või Üliõpilaste jaotus, mis määratakse parameetriga n -1 (vabadusastmete arv). See jaotus on lähedane normaaljaotusele (mida suurem n, seda lähemal on jaotused).
Joonisel fig. 95  Esitatakse õpilase jaotus 30 vabadusastmega. Nagu näete, on see normaaljaotusele väga lähedal.
Esitatakse õpilase jaotus 30 vabadusastmega. Nagu näete, on see normaaljaotusele väga lähedal.
Sarnaselt normaaljaotusega NORMDIST ja NORMINV töötavatele funktsioonidele on olemas ka t-jaotusega töötamise funktsioonid - STUDIST (TDIST) ja STUDRASPBR (TINV). Nende funktsioonide kasutamise näite leiate failist STUDRIST.XLS (mall ja lahendus) ja jooniselt fig. 96  .
.
Muude tunnuste jaotused
Nagu me juba teame, on ootushinnangu täpsuse määramiseks vaja t-jaotust. Teiste parameetrite, näiteks dispersiooni, hindamiseks on vaja teisi jaotusi. Kaks neist on F-jaotus ja x 2 -jaotus.
Keskmise usaldusvahemik
Usaldusvahemik on intervall, mis on üles ehitatud parameetri hinnangulise väärtuse ümber ja näitab, kus asub hinnangulise parameetri tegelik väärtus a priori antud tõenäosusega.
Tekib keskmise väärtuse usaldusvahemiku konstrueerimine järgmisel viisil:
Näide
Kiirtoidurestoran plaanib oma sortimenti laiendada uut tüüpi võileivaga. Nõudluse hindamiseks plaanib juht valida juba proovinute hulgast juhuslikult 40 külastajat ja paluda neil hinnata oma suhtumist uude tootesse skaalal 1-10. Juht soovib hinnata eeldatav punktide arv, mille uus toode saab, ja koostage selle hinnangu jaoks 95% usaldusvahemik. Kuidas seda teha? (vt faili SANDWICH1.XLS (mall ja lahendus).
Lahendus
Selle probleemi lahendamiseks võite kasutada . Tulemused on esitatud joonisel fig. 97  .
.
Koguväärtuse usaldusvahemik
Mõnikord on näidisandmete põhjal vaja hinnata mitte matemaatilist ootust, vaid väärtuste kogusummat. Näiteks olukorras, kus on audiitor, võib olla huvitav hinnata mitte arve keskmist väärtust, vaid kõigi arvete summat.
Olgu N elementide koguarv, n valimi suurus, T 3 valimi väärtuste summa, T" kogu populatsiooni summa hinnang, siis ![]() , ja usaldusvahemik arvutatakse valemiga , kus s on valimi standardhälbe hinnang, valimi keskmise hinnang.
, ja usaldusvahemik arvutatakse valemiga , kus s on valimi standardhälbe hinnang, valimi keskmise hinnang.
Näide
Oletame, et maksuamet soovib hinnata 10 000 maksumaksja maksutagastuse kogusummat. Maksumaksja kas saab raha tagasi või maksab täiendavalt makse. Leidke tagasimakse summa 95% usaldusvahemik, eeldades, et valimi suurus on 500 inimest (vt faili REFUND AMOUNT.XLS (mall ja lahendus).
Lahendus
StatPro-s pole selle juhtumi jaoks spetsiaalset protseduuri, kuid näete, et ülaltoodud valemite abil saab keskmise piiridest saada piirid (joonis 98).  ).
).
Proportsiooni usaldusvahemik
Olgu p klientide osakaalu ootus ja pv selle osakaalu hinnang, mis on saadud n suuruse valimi põhjal. Võib näidata, et piisavalt suur  hinnanguline jaotus on keskmise p ja standardhälbega normaalsele lähedane
hinnanguline jaotus on keskmise p ja standardhälbega normaalsele lähedane ![]() . Hinnangu standardviga väljendatakse sel juhul järgmiselt
. Hinnangu standardviga väljendatakse sel juhul järgmiselt  , ja usaldusvahemik as
, ja usaldusvahemik as  .
.
Näide
Kiirtoidurestoran plaanib oma sortimenti laiendada uut tüüpi võileivaga. Nõudluse hindamiseks valis juht juhuslikult 40 külastajat juba proovinute hulgast ja palus neil hinnata oma suhtumist uude tootesse skaalal 1-10. Juht soovib hinnata eeldatavat osakaalu. klientidest, kes hindavad uut toodet vähemalt 6 punktiga (ta eeldab, et need kliendid on uue toote tarbijad).
Lahendus
Esialgu loome uue veeru 1 alusel, kui kliendi punktisumma oli üle 6 punkti ja muul juhul 0 (vt faili SANDWICH2.XLS (mall ja lahendus).
1. meetod
Arvestades summa 1, hindame osakaalu ja seejärel kasutame valemeid.
Z cr väärtus on võetud spetsiaalsetest normaaljaotuse tabelitest (näiteks 1,96 95% usaldusvahemiku korral).
Kasutades seda lähenemisviisi ja konkreetseid andmeid 95% intervalli koostamiseks, saame järgmised tulemused (joonis 99  ). Parameetri z cr kriitiline väärtus on 1,96. Hinnangu standardviga on 0,077. Usaldusvahemiku alumine piir on 0,475. Usaldusvahemiku ülempiir on 0,775. Seega võib juht 95% kindlusega eeldada, et klientide osakaal, kes hindavad uut toodet 6 punkti või rohkem, jääb vahemikku 47,5–77,5.
). Parameetri z cr kriitiline väärtus on 1,96. Hinnangu standardviga on 0,077. Usaldusvahemiku alumine piir on 0,475. Usaldusvahemiku ülempiir on 0,775. Seega võib juht 95% kindlusega eeldada, et klientide osakaal, kes hindavad uut toodet 6 punkti või rohkem, jääb vahemikku 47,5–77,5.
2. meetod
Selle probleemi saab lahendada standardsete StatPro tööriistade abil. Selleks piisab, kui märkida, et osakaal langeb sel juhul kokku veeru Tüüp keskmise väärtusega. Järgmisena kandideeri StatPro/Statistiline järeldus/Ühe proovi analüüs veeru Tüüp keskmise väärtuse (ootusehinnangu) usaldusvahemiku loomiseks. Sel juhul saadud tulemused on väga lähedased 1. meetodi tulemusele (joonis 99).
Standardhälbe usaldusvahemik
s kasutatakse standardhälbe hinnanguna (valem on toodud jaotises 1). Hinnangu s tihedusfunktsioon on hii-ruutfunktsioon, millel on sarnaselt t-jaotusele n-1 vabadusastet. Selle distributsiooniga töötamiseks on olemas erifunktsioonid CHI2DIST (CHIDIST) ja CHI2OBR (CHIINV) .
Sel juhul ei ole usaldusvahemik enam sümmeetriline. Piiride tingimuslik skeem on näidatud joonisel fig. 100 .
Näide
Masin peaks tootma 10 cm läbimõõduga detaile, kuid erinevatel asjaoludel tuleb ette vigu. Kvaliteedikontrolör on mures kahe asja pärast: esiteks peaks keskmine väärtus olema 10 cm; teiseks, isegi sel juhul, kui kõrvalekalded on suured, lükatakse paljud detailid tagasi. Iga päev teeb ta 50 osast koosneva näidise (vt faili QUALITY CONTROL.XLS (mall ja lahendus). Milliseid järeldusi selline näidis annab?
Lahendus
Me koostame 95% usaldusvahemikud keskmise ja standardhälbe jaoks, kasutades StatPro/Statistiline järeldus/Ühe proovi analüüs(Joonis 101  ).
).
Lisaks arvutame läbimõõtude normaaljaotuse eeldusel defektsete toodete osakaalu, seades maksimaalseks kõrvalekaldeks 0,065. Kasutades otsingutabeli võimalusi (kahe parameetri juhtum), konstrueerime tagasilükkamiste protsendi sõltuvuse keskmisest väärtusest ja standardhälbest (joonis 102).  ).
).
Kahe keskmise erinevuse usaldusvahemik
See on statistiliste meetodite üks olulisemaid rakendusi. Olukorra näited.
Rõivapoe juhataja tahaks teada, kui palju keskmine naissoost ostja poes rohkem või vähem kulutab kui mees.
Need kaks lennufirmat lendavad sarnastel marsruutidel. Tarbijaorganisatsioon soovib võrrelda mõlema lennufirma keskmiste eeldatavate lendude hilinemise aegade erinevust.
Ettevõte saadab teatud tüüpi kaupade kupongid välja ühes linnas ja teises linnas välja ei saada. Juhid soovivad võrrelda nende kaupade keskmisi oste järgmise kahe kuu jooksul.
Automüüja tegeleb esitlustel sageli abielupaaridega. Et mõista nende isiklikke reaktsioone esitlusele, intervjueeritakse paare sageli eraldi. Juht soovib hinnata meeste ja naiste antud hinnangute erinevust.
Sõltumatute proovide juhtum
Keskmise erinevuse t-jaotus on n 1 + n 2 - 2 vabadusastmega. Usaldusvahemikku μ 1 - μ 2 kohta väljendatakse suhtega:

Seda probleemi saab lahendada mitte ainult ülaltoodud valemitega, vaid ka standardsete StatPro tööriistadega. Selleks piisab taotlemisest
Proportsioonide erinevuse usaldusvahemik
Laskma olla aktsiate matemaatiline ootus. Olgu nende valimi hinnangud, mis on üles ehitatud vastavalt n 1 ja n 2 suurustele valimitele. Siis on erinevuse hinnang. Seetõttu väljendatakse selle erinevuse usaldusvahemikku järgmiselt:
Siin z cr on väärtus, mis saadakse eritabelite normaaljaotusest (näiteks 1,96 95% usaldusvahemiku korral).
Hinnangu standardviga väljendatakse sel juhul seosega:
 .
.
Näide
Kauplus võttis suurmüügiks valmistudes ette järgmised turundusuuringud. 300 parimat ostjat valiti välja ja jagati juhuslikult kahte 150-liikmelisse rühma. Kõikidele väljavalitud ostjatele saadeti kutsed müügil osalemiseks, kuid ainult esimese grupi liikmetele oli lisatud kupong, mis annab õiguse 5% allahindlusele. Müügi käigus fikseeriti kõigi 300 valitud ostja ostud. Kuidas saab juht tulemusi tõlgendada ja kupongide tõhususe kohta hinnanguid anda? (Vt faili COUPONS.XLS (mall ja lahendus)).
Lahendus
Meie konkreetse juhtumi puhul tegi 150 sooduskupongi saanud kliendist 55 soodusostu ja 150 kupongi mittesaanud kliendist sooritas ostu vaid 35 (joonis 103).  ). Siis on proovi proportsioonide väärtused vastavalt 0,3667 ja 0,2333. Ja nende valimi erinevus on vastavalt 0,1333. Kui eeldada, et usaldusvahemik on 95%, leiame normaaljaotuse tabelist z cr = 1,96. Valimi erinevuse standardvea arvutus on 0,0524. Lõpuks saame, et 95% usaldusvahemiku alumine piir on vastavalt 0,0307 ja ülemine piir 0,2359. Saadud tulemusi võib tõlgendada nii, et iga 100 sooduskupongi saanud kliendi kohta on meil oodata 3 kuni 23 uut klienti. Siiski tuleb meeles pidada, et see järeldus iseenesest ei tähenda kupongide kasutamise efektiivsust (sest allahindlust tehes jääme kasumist ilma!). Näitame seda konkreetsete andmetega. Oletame, et keskmine ostusumma on 400 rubla, millest 50 rubla. on poe kasum. Siis on oodatav kasum 100 kupongi mitte saanud kliendi kohta võrdne:
). Siis on proovi proportsioonide väärtused vastavalt 0,3667 ja 0,2333. Ja nende valimi erinevus on vastavalt 0,1333. Kui eeldada, et usaldusvahemik on 95%, leiame normaaljaotuse tabelist z cr = 1,96. Valimi erinevuse standardvea arvutus on 0,0524. Lõpuks saame, et 95% usaldusvahemiku alumine piir on vastavalt 0,0307 ja ülemine piir 0,2359. Saadud tulemusi võib tõlgendada nii, et iga 100 sooduskupongi saanud kliendi kohta on meil oodata 3 kuni 23 uut klienti. Siiski tuleb meeles pidada, et see järeldus iseenesest ei tähenda kupongide kasutamise efektiivsust (sest allahindlust tehes jääme kasumist ilma!). Näitame seda konkreetsete andmetega. Oletame, et keskmine ostusumma on 400 rubla, millest 50 rubla. on poe kasum. Siis on oodatav kasum 100 kupongi mitte saanud kliendi kohta võrdne:
50 0,2333 100 \u003d 1166,50 rubla.
Sarnased arvutused 100 kupongi saanud ostja kohta annavad:
30 0,3667 100 \u003d 1100,10 rubla.
Keskmise kasumi vähenemine 30-le on seletatav asjaoluga, et soodustust kasutades sooritavad kupongi saanud ostjad keskmiselt 380 rubla eest ostu.
Seega näitab lõppjäreldus selliste kupongide kasutamise ebaefektiivsust selles konkreetses olukorras.
Kommenteeri. Selle probleemi saab lahendada standardsete StatPro tööriistade abil. Selleks piisab, kui taandada see probleem kahe keskmise erinevuse hindamise probleemiks meetodi abil ja seejärel rakendada StatPro/Statistiline järeldus/Kahe proovi analüüs kahe keskmise väärtuse erinevuse usaldusvahemiku loomiseks.
Usaldusintervalli kontroll
Usaldusvahemiku pikkus sõltub järgmisi tingimusi:
otseandmed (standardhälve);
olulisuse tase;
näidissuurus.
Valimi suurus keskmise hindamiseks
Mõelgem esmalt probleemile üldiselt. Tähistame meile antud usaldusvahemiku poole pikkuse väärtuse B-ks (joon. 104  ). Teame, et mõne juhusliku suuruse X keskmise väärtuse usaldusvahemik on väljendatud kujul
). Teame, et mõne juhusliku suuruse X keskmise väärtuse usaldusvahemik on väljendatud kujul ![]() , Kus
, Kus ![]() . Eeldusel:
. Eeldusel:
![]() ja väljendades n , saame .
ja väljendades n , saame .
Kahjuks ei tea me juhusliku suuruse X dispersiooni täpset väärtust. Lisaks ei tea me t cr väärtust, kuna see sõltub vabadusastmete arvust n-st. Sellises olukorras saame teha järgmist. Dispersiooni s asemel kasutame mingit dispersiooni hinnangut uuritava juhusliku muutuja mõne olemasoleva realisatsiooni puhul. T cr väärtuse asemel kasutame normaaljaotuse jaoks z cr väärtust. See on täiesti vastuvõetav, kuna normaal- ja t-jaotuse tihedusfunktsioonid on väga lähedased (välja arvatud väikese n korral). Seega on soovitud valem järgmine:
 .
.
Kuna valem annab üldiselt mittetäisarvulisi tulemusi, võetakse soovitud valimi suuruseks ümardamine tulemuse ülejäägiga.
Näide
Kiirtoidurestoran plaanib oma sortimenti laiendada uut tüüpi võileivaga. Nõudluse hindamiseks plaanib juhataja juhuslikult valida juba proovinute hulgast külastajaid ja paluda neil hinnata oma suhtumist uude tootesse skaalal 1-10. Juht soovib et hinnata eeldatavat punktide arvu, mille uus toode saab. toode ja joonistage selle hinnangu 95% usaldusvahemik. Küll aga soovib ta, et pool usaldusvahemiku laiusest ei ületaks 0,3. Kui palju külastajaid ta küsitlemiseks vajab?
järgnevalt:

Siin r ots on murdosa p hinnang ja B on antud pool usaldusvahemiku pikkusest. Väärtuse abil saab saada n-i täispuhutud väärtuse r ots= 0,5. Sel juhul ei ületa usaldusvahemiku pikkus p ühegi tegeliku väärtuse jaoks antud väärtust B.
Näide
Laske eelmise näite juhil hinnata uut tüüpi toodet eelistavate klientide osakaalu. Ta soovib konstrueerida 90% usaldusvahemiku, mille poole pikkus on 0,05 või väiksem. Kui palju kliente tuleks juhuslikult valida?
Lahendus
Meie puhul on z cr väärtus 1,645. Seetõttu arvutatakse vajalik kogus järgmiselt  .
.
Kui juhil oleks põhjust arvata, et p soovitud väärtus on näiteks umbes 0,3, siis asendades selle väärtuse ülaltoodud valemis, saaksime juhusliku valimi väiksema väärtuse, nimelt 228.
Valem määramiseks juhuslikud valimi suurused kahe keskmise erinevuse korral kirjutatud kui:
 .
.
Näide
Mõnel arvutifirmal on klienditeeninduskeskus. Viimasel ajal on suurenenud klientide kaebuste arv teenuse halva kvaliteedi kohta. Teeninduskeskuses töötab põhiliselt kahte tüüpi töötajaid: vähese kogemusega, kuid erikoolituse läbinud ja suurte praktiliste kogemustega, kuid erikursusi läbimata. Ettevõte soovib analüüsida viimase kuue kuu klientide kaebusi ja võrrelda nende keskmist arvu kahe töötajate rühma kohta. Eeldatakse, et mõlema rühma valimite numbrid on samad. Kui palju töötajaid peab valimisse kaasama, et saada 95% intervall, mille poole pikkus ei ületa 2?
Lahendus
Siin on σ ots mõlema juhusliku suuruse standardhälbe hinnang eeldusel, et need on lähedased. Seega peame oma ülesande täitmisel selle hinnangu kuidagi saama. Seda saab teha näiteks järgmiselt. Vaadates viimase kuue kuu klientide kaebuste andmeid, võib juht märgata, et töötaja kohta on üldiselt 6–36 kaebust. Teades, et normaaljaotuse korral on praktiliselt kõik väärtused kuni kolm standardhälvet keskmisest, võib ta mõistlikult arvata, et:
![]() , kust σ ots = 5.
, kust σ ots = 5.
Asendades selle väärtuse valemis, saame  .
.
Valem määramiseks juhusliku valimi suurus aktsiate vahe hindamisel paistab nagu:

Näide
Mõnel ettevõttel on sarnaste toodete tootmiseks kaks tehast. Ettevõtte juht soovib võrrelda mõlema tehase defektide taset. Olemasoleva teabe kohaselt on tagasilükkamise määr mõlemas tehases 3–5%. See peaks koostama 99% usaldusvahemiku, mille poole pikkus ei ületa 0,005 (või 0,5%). Kui palju tooteid tuleks igast tehasest valida?
Lahendus
Siin on p 1ot ja p 2ot hinnangud kahe tundmatu praagi fraktsiooni kohta 1. ja 2. tehases. Kui paneme p 1ots \u003d p 2ots \u003d 0,5, saame n jaoks ülehinnatud väärtuse. Aga kuna meil on nende aktsiate kohta a priori info olemas, siis võtame nende aktsiate ülemise hinnangu, nimelt 0,05. Saame
Kui mõningaid üldkogumi parameetreid hinnatakse valimiandmete põhjal, on kasulik esitada mitte ainult parameetri punkthinnang, vaid ka usaldusvahemik, mis näitab, kus hinnatava parameetri täpne väärtus võib asuda.
Selles peatükis tutvusime ka kvantitatiivsete seostega, mis võimaldavad ehitada selliseid intervalle erinevate parameetrite jaoks; õppinud viise usaldusvahemiku pikkuse kontrollimiseks.
Samuti märgime, et valimi suuruse hindamise probleemi (katse planeerimise probleem) saab lahendada standardsete StatPro tööriistade abil, nimelt StatPro/statistiline järeldus/proovi suuruse valik.
SAGEDUSTE JA OSADE KINNITUSVÄLJAD
© 2008
Riiklik Rahvatervise Instituut, Oslo, Norra
Artiklis kirjeldatakse ja käsitletakse sageduste ja proportsioonide usaldusvahemike arvutamist Waldi, Wilsoni, Klopper-Pearsoni meetodite abil, kasutades nurkteisendust ja Waldi meetodit Agresti-Cowlli korrektsiooniga. Esitatud materjal annab üldist teavet sageduste ja proportsioonide usaldusvahemike arvutamise meetodite kohta ning on mõeldud äratama ajakirja lugejates huvi mitte ainult usaldusvahemike kasutamise vastu oma uurimistöö tulemuste esitamisel, vaid ka erialakirjanduse lugemise vastu enne alustamist. tööd tulevaste väljaannete kallal.
Märksõnad: usaldusvahemik, sagedus, proportsioon
Ühes varasemas publikatsioonis mainiti lühidalt kvalitatiivsete andmete kirjeldust ja teatati, et nende intervallhinnang on eelistatavam punkthinnangule, et kirjeldada uuritava tunnuse esinemissagedust üldpopulatsioonis. Tõepoolest, kuna uuringud viiakse läbi valimiandmete abil, peab tulemuste projektsioon üldkogumile sisaldama valimi hinnangus ebatäpsust. Usaldusvahemik on hinnangulise parameetri täpsuse mõõt. Huvitav on see, et mõnes arstidele mõeldud statistika põhitõdesid käsitlevas raamatus jäetakse sageduste usaldusvahemike teema täielikult tähelepanuta. Käesolevas artiklis vaatleme mitmeid viise sageduste usaldusvahemike arvutamiseks, eeldades valimi omadusi, nagu mittekordumine ja representatiivsus, samuti vaatluste sõltumatust üksteisest. Käesolevas artiklis ei mõisteta sagedust absoluutarvuna, mis näitab, mitu korda see või teine väärtus kokkuvõttes esineb, vaid suhtelist väärtust, mis määrab uuringus osalejate osakaalu, kellel on uuritav tunnus.
Biomeditsiinilistes uuringutes kasutatakse kõige sagedamini 95% usaldusvahemikke. See usaldusvahemik on piirkond, millesse tegelik osakaal langeb 95% ajast. Teisisõnu võib 95% kindlusega väita, et mingi tunnuse esinemissageduse tegelik väärtus üldpopulatsioonis jääb 95% usaldusvahemikku.
Enamik meditsiiniteadlastele mõeldud statistikaõpikuid teatab, et sagedusviga arvutatakse valemi abil
kus p on tunnuse esinemise sagedus valimis (väärtus 0 kuni 1). Enamikus kodumaistes teadusartiklites on märgitud tunnuse esinemissageduse väärtus valimis (p) ja selle viga (s) kujul p ± s. Siiski on otstarbekam esitada tunnuse esinemissageduse üldpopulatsioonis 95% usaldusvahemik, mis hõlmab väärtusi alates
 |
 enne.
enne.
Mõnes õpikus on väikeste valimite puhul soovitatav N - 1 vabadusastme puhul väärtus 1,96 asendada t väärtusega, kus N on vaatluste arv valimis. T väärtuse leiate t-jaotuse tabelitest, mis on saadaval peaaegu kõigis statistikaõpikutes. t jaotuse kasutamine Waldi meetodi jaoks ei anna nähtavaid eeliseid teiste allpool käsitletud meetodite ees ja seetõttu ei tervita seda mõned autorid.
Ülaltoodud meetod sageduste või murdude usaldusvahemike arvutamiseks on oma nime saanud Abraham Waldi järgi (Abraham Wald, 1902–1950), kuna seda hakati laialdaselt kasutama pärast Waldi ja Wolfowitzi avaldamist 1939. aastal. Meetodi enda pakkus aga välja Pierre Simon Laplace (1749–1827) juba 1812. aastal.
Waldi meetod on väga populaarne, kuid selle rakendamine on seotud märkimisväärsete probleemidega. Meetodit ei soovitata kasutada väikeste valimite puhul, samuti juhtudel, kui tunnuse esinemissagedus kipub olema 0 või 1 (0% või 100%) ning sageduste 0 ja 1 puhul pole see lihtsalt võimalik. normaaljaotuse lähendus, mida kasutatakse vea arvutamisel, "ei tööta" juhtudel, kui n p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Kuna uuel muutujal on normaaljaotus, on muutuja φ 95% usaldusvahemiku alumine ja ülemine piir φ-1,96 ja φ+1,96 vasakult">


Väikeste valimite 1,96 asemel on N - 1 vabadusastmega soovitatav asendada t väärtus. See meetod ei anna negatiivseid väärtusi ja võimaldab teil sageduste usaldusvahemikke täpsemalt hinnata kui Waldi meetod. Lisaks on seda kirjeldatud paljudes kodumaistes meditsiinistatistika teatmeteostes, mis aga ei toonud kaasa selle laialdast kasutamist meditsiiniuuringutes. Usaldusvahemike arvutamine nurgateisendusega ei ole soovitatav 0-le või 1-le lähenevate sageduste korral.
Siinkohal tavaliselt lõpeb usaldusvahemike hindamise meetodite kirjeldus enamikus arstiteadlastele mõeldud statistika aluste raamatutes ning see probleem on omane mitte ainult kodumaisele, vaid ka välismaisele kirjandusele. Mõlemad meetodid põhinevad keskpiiri teoreemil, mis tähendab suurt valimit.
Arvestades puudusi usaldusvahemike hindamisel ülaltoodud meetodite abil, pakkusid Clopper (Clopper) ja Pearson (Pearson) 1934. aastal välja meetodi nn täpse usaldusvahemiku arvutamiseks, võttes arvesse uuritava tunnuse binoomjaotust. See meetod on saadaval paljudes veebikalkulaatorites, kuid sel viisil saadud usaldusvahemikud on enamasti liiga laiad. Samal ajal on seda meetodit soovitatav kasutada juhtudel, kui on vaja konservatiivset hinnangut. Meetodi konservatiivsus suureneb valimi suuruse vähenemisel, eriti N puhul< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
Paljude statistikute sõnul tehakse sageduste usaldusvahemike optimaalseim hinnang Wilsoni meetodi abil, mis pakuti välja juba 1927. aastal, kuid mida kodumaistes biomeditsiinilistes uuringutes praktiliselt ei kasutatud. See meetod mitte ainult ei võimalda hinnata usaldusvahemikke nii väga väikeste kui ka väga kõrgete sageduste jaoks, vaid on rakendatav ka väikese arvu vaatluste jaoks. Üldiselt on usaldusvahemik Wilsoni valemi järgi kujul alates
 |
 |
kus see võtab 95% usaldusvahemiku arvutamisel väärtuse 1,96, N on vaatluste arv ja p on tunnuse sagedus valimis. See meetod on saadaval veebikalkulaatorites, seega pole selle rakendamine problemaatiline. ja ei soovita seda meetodit kasutada n p< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Lisaks Wilsoni meetodile arvatakse, et Agresti-Caulli korrigeeritud Waldi meetod annab sageduste usaldusvahemiku optimaalse hinnangu. Agresti-Coulle'i parandus on Waldi valemis valimi tunnuse esinemissageduse (p) asendamine p`-ga, mille arvutamisel lisatakse lugejale 2 ja nimetajale 4, st. , p` = (X + 2) / (N + 4), kus X on uuringus osalejate arv, kellel on uuritav tunnus, ja N on valimi suurus. See modifikatsioon annab Wilsoni valemi tulemustele väga sarnased tulemused, välja arvatud juhul, kui sündmuste määr läheneb 0% või 100% ja valim on väike. Lisaks ülaltoodud sageduste usaldusvahemike arvutamise meetoditele on väikeste valimite puhul välja pakutud pidevuse parandusi nii Waldi kui ka Wilsoni meetodi puhul, kuid uuringud on näidanud, et nende kasutamine ei ole asjakohane.
Kaaluge ülaltoodud meetodite rakendamist usaldusvahemike arvutamiseks kahe näite abil. Esimesel juhul uurime suurt valimit 1000 juhuslikult valitud uuringus osalejast, kellest 450-l on uuritav tunnus (olgu see siis riskitegur, tulemus või mõni muu tunnus), mille esinemissagedus on 0,45 või 45%. Teisel juhul viiakse uuring läbi väikese valimiga, näiteks ainult 20 inimesega, ja ainult 1 uuringus osalejal (5%) on uuritav tunnus. Usaldusvahemikud Waldi meetodi jaoks, Waldi meetodi jaoks Agresti-Colli korrektsiooniga ja Wilsoni meetodi jaoks arvutati Jeff Sauro välja töötatud veebikalkulaatori abil (http://www./wald.htm). Järjepidevuse järgi korrigeeritud Wilsoni usaldusvahemikud arvutati kalkulaatoriga, mille pakub Wassar Stats: Statistical Computation veebisait (http://faculty.vassar.edu/lowry/prop1.html). Fisheri nurkteisendust kasutavad arvutused viidi läbi "käsitsi", kasutades t kriitilist väärtust vastavalt 19 ja 999 vabadusastme jaoks. Mõlema näite arvutustulemused on toodud tabelis.
Usaldusvahemikud on arvutatud kahe tekstis kirjeldatud näite jaoks kuuel erineval viisil
Usaldusintervalli arvutamise meetod |
P=0,0500 ehk 5% | 95% CI, kui X = 450, N = 1000, P = 0,4500 või 45% |
–0,0455–0,2541 | ||
Walda Agresti-Colli korrektsiooniga | <,0001–0,2541 | |
Wilson koos järjepidevuse korrektsiooniga | ||
Klopper-Pearsoni "täpne meetod" | ||
Nurga teisendus | <0,0001–0,1967 |
Nagu tabelist näha, läheb esimese näite puhul "üldtunnustatud" Waldi meetodil arvutatud usaldusvahemik negatiivsesse piirkonda, mis ei saa sageduste puhul nii olla. Kahjuks pole sellised juhtumid vene kirjanduses haruldased. Traditsiooniline viis andmete esitamiseks sagedusena ja selle viga varjab seda probleemi osaliselt. Näiteks kui tunnuse esinemissagedus (protsentides) on esitatud kui 2,1 ± 1,4, siis see ei ole nii "ärritav" kui 2,1% (95% CI: –0,7; 4,9), kuigi ja tähendab sama. Waldi meetod Agresti-Coulle'i parandusega ja nurkteisendust kasutav arvutus annab nullile kalduva alumise piiri. Wilsoni meetod koos pidevuse korrigeerimisega ja "täpne meetod" annavad laiemad usaldusvahemikud kui Wilsoni meetod. Teise näite puhul annavad kõik meetodid ligikaudu ühesugused usaldusvahemikud (erinevused ilmnevad vaid tuhandikes), mis pole üllatav, kuna sündmuse sagedus selles näites ei erine palju 50% -st ja valimi suurus on üsna suur .
Lugejatele, keda see probleem huvitab, võib soovitada R. G. Newcombe’i ja Browni, Cai ja Dasgupta töid, mis annavad plussid ja miinused vastavalt 7 ja 10 erineva usaldusintervalli arvutamise meetodi kasutamisele. Kodumaistest käsiraamatutest on soovitatav raamat ja, milles lisaks teooria üksikasjalikule kirjeldusele on välja toodud Waldi ja Wilsoni meetodid ning meetod usaldusvahemike arvutamiseks, võttes arvesse binoomsagedusjaotust. Lisaks tasuta veebikalkulaatoritele (http://www./wald.htm ja http://faculty.vassar.edu/lowry/prop1.html) saab sageduste (ja mitte ainult!) usaldusvahemikke arvutada, kasutades CIA programm ( Confidence Intervals Analysis), mille saab alla laadida aadressilt http://www. meditsiinikool. soton. ac. uk/cia/ .
Järgmises artiklis käsitletakse kvalitatiivsete andmete võrdlemise ühemõõtmelisi viise.
Bibliograafia
Banerjee A. Lihtkeeles meditsiinistatistika: sissejuhatav kursus / A. Banerzhi. - M. : Praktiline meditsiin, 2007. - 287 lk. Meditsiinistatistika / . - M. : Meditsiiniinfo Agentuur, 2007. - 475 lk. Glanz S. Meditsiini-bioloogiline statistika / S. Glants. - M. : Praktika, 1998. Andmetüübid, leviku kontrollimine ja kirjeldav statistika / // Inimökoloogia - 2008. - Nr 1. - Lk 52–58. Zhizhin K.S.. Meditsiinistatistika: õpik / . - Rostov n / D: Phoenix, 2007. - 160 lk. Rakendusmeditsiiniline statistika / ,. - Peterburi. : Folio, 2003. - 428 lk. Lakin G.F. Biomeetria / . - M. : Kõrgkool, 1990. - 350 lk. Arst V. A. Matemaatiline statistika meditsiinis / , . - M. : Rahandus ja statistika, 2007. - 798 lk. Matemaatiline statistika kliinilistes uuringutes / , . - M. : GEOTAR-MED, 2001. - 256 lk. Junkerov V. JA. Meditsiiniuuringute andmete meditsiinilis-statistiline töötlemine /,. - Peterburi. : VmedA, 2002. - 266 lk. Agresti A. Ligikaudne on parem kui täpne binoomproportsioonide intervallide hindamiseks / A. Agresti, B. Coull // Ameerika statistik. - 1998. - N 52. - S. 119-126. Altman D. Kindel statistika // D. Altman, D. Machin, T. Bryant, M. J. Gardner. - London: BMJ Books, 2000. - 240 lk. Pruun L.D. Intervall estimation for a binomial ratio / L. D. Brown, T. T. Cai, A. Dasgupta // Statistikateadus. - 2001. - N 2. - Lk 101-133. Clopper C.J. Usaldus- või usalduspiiride kasutamine, mida illustreeritakse binoomarvu puhul / C. J. Clopper, E. S. Pearson // Biometrika. - 1934. - N 26. - Lk 404-413. Garcia-Perez M. A. Binoomparameetri usaldusvahemikust / M. A. Garcia-Perez // Kvaliteet ja kvantiteet. - 2005. - N 39. - Lk 467-481. Motulsky H. Intuitiivne biostatistika // H. Motulsky. - Oxford: Oxford University Press, 1995. - 386 lk. Newcombe R.G. Kahepoolsed usaldusintervallid ühe proportsiooni jaoks: seitsme meetodi võrdlus / R. G. Newcombe // Meditsiini statistika. - 1998. - N. 17. - Lk 857–872. Sauro J. Valmimismäärade hindamine väikestest valimitest binoomsete usaldusvahemike abil: võrdlused ja soovitused / J. Sauro, J. R. Lewis // Proceedings of the human factor and ergonomics Society aastakoosolek. – Orlando, Florida, 2005. Wald A. Pidevate jaotusfunktsioonide usalduspiirid // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. - 1939. - N 10. - Lk 105–118. Wilson E.B. Tõenäoline järeldus, pärimisseadus ja statistiline järeldus / E. B. Wilson // Journal of American Statistical Association. - 1927. - N 22. - Lk 209-212.PROPORTSIOONIDE KONFIDENTSIAALID
A. M. Grjibovski
Riiklik Rahvatervise Instituut, Oslo, Norra
Artiklis esitatakse mitmed meetodid binoomproportsioonide usaldusvahemike arvutamiseks, nimelt Waldi, Wilsoni, arcsiini, Agresti-Coulli ja täpsed Clopper-Pearsoni meetodid. Töö annab ainult üldise sissejuhatuse binoomproportsiooni usaldusintervallide hindamise probleemisse ja selle eesmärk ei ole mitte ainult ärgitada lugejaid kasutama usaldusvahemikke enda empiiriliste uurimisvahemike tulemuste esitamisel, vaid ka julgustada neid enne statistikaraamatutega tutvuma. enda andmete analüüsimiseks ja käsikirjade ettevalmistamiseks.
võtmesõnad: usaldusvahemik, proportsioon
Kontaktinfo:
– Oslo, Norra riikliku rahvatervise instituudi vanemnõunik
Iga valim annab ainult ligikaudse ettekujutuse üldkogumist ja kõik valimi statistilised karakteristikud (keskmine, moodus, dispersioon ...) on üldiste parameetrite ligikaudsed või näiteks hinnangud, mida enamikul juhtudel ei saa arvutada üldrahvastiku ligipääsmatus (joonis 20) .
Joonis 20. Valimiviga
Kuid saate määrata intervalli, milles teatud tõenäosusega asub statistilise tunnuse tegelik (üldine) väärtus. Seda intervalli nimetatakse d usaldusvahemik (CI).
Nii et üldine keskmine tõenäosusega 95% jääb sees
alates kuni, (20)
Kus t - Studenti kriteeriumi tabeliväärtus α =0,05 ja f= n-1
Võib leida ja 99% CI, antud juhul t jaoks valitud α =0,01.
Mis on usaldusvahemiku praktiline tähtsus?
Lai usaldusvahemik näitab, et valimi keskmine ei kajasta populatsiooni keskmist täpselt. Tavaliselt on selle põhjuseks valimi ebapiisav suurus või selle heterogeensus, s.t. suur dispersioon. Mõlemad annavad suure keskmise vea ja vastavalt laiema CI. Ja see on põhjus naasta uurimistöö planeerimise etappi.
CI ülemine ja alumine piir hindab, kas tulemused on kliiniliselt olulised
Peatugem üksikasjalikumalt rühmaomaduste uurimise tulemuste statistilise ja kliinilise olulisuse küsimusel. Tuletame meelde, et statistika ülesanne on avastada näidisandmete põhjal vähemalt mõningaid erinevusi üldistes populatsioonides. Arsti ülesanne on leida sellised (mitte igasugused) erinevused, mis aitavad diagnoosida või ravida. Ja mitte alati statistilised järeldused ei ole kliiniliste järelduste aluseks. Seega statistiliselt oluline hemoglobiini langus 3 g/l ei tekita muret. Ja vastupidi, kui mõnel inimkeha probleemil pole kogu elanikkonna tasandil massilist iseloomu, ei ole see põhjus selle probleemiga mitte tegeleda.
|
Me kaalume seda seisukohta näiteks. Teadlased mõtlesid, kas poisid, kellel oli mingisugune nakkushaigus, jäid kasvus oma eakaaslastest maha. Sel eesmärgil viidi läbi valikuuring, milles osales 10 seda haigust põdenud poissi. Tulemused on toodud tabelis 23. Tabel 23. Statistilised tulemused
Nendest arvutustest järeldub, et 10-aastaste poiste, kellel on mingi nakkushaigus, selektiivne keskmine pikkus on normilähedane (132,5 cm). Usaldusvahemiku alumine piir (126,6 cm) viitab aga sellele, et 95% tõenäosusega vastab nende laste tegelik keskmine pikkus mõistele "lühikest kasvu", s.o. need lapsed on kidurad. Selles näites on usaldusvahemiku arvutuste tulemused kliiniliselt olulised. |
|||||||||||||||||||
Sihtmärk– õpetada õpilastele statistiliste parameetrite usaldusvahemike arvutamise algoritme.
Statistilise andmetöötluse käigus peaks arvutatud aritmeetiline keskmine, variatsioonikordaja, korrelatsioonikordaja, erinevuse kriteeriumid ja muu punktstatistika saama kvantitatiivsed usalduspiirid, mis näitavad indikaatori võimalikke kõikumisi üles-alla usaldusvahemiku piires.
Näide 3.1
.
Kaltsiumi jaotumist ahvide vereseerumis, nagu eelnevalt kindlaks tehtud, iseloomustavad järgmised selektiivsed näitajad: = 11,94 mg%;  = 0,127 mg%; n= 100. Tuleb määrata usaldusvahemik üldkeskmise jaoks (
= 0,127 mg%; n= 100. Tuleb määrata usaldusvahemik üldkeskmise jaoks (  ) usalduse tõenäosusega P
= 0,95.
) usalduse tõenäosusega P
= 0,95.
Üldkeskmine on teatud tõenäosusega intervallis:
 , Kus
, Kus  – valimi aritmeetiline keskmine; t- Üliõpilase kriteerium;
– valimi aritmeetiline keskmine; t- Üliõpilase kriteerium;  on aritmeetilise keskmise viga.
on aritmeetilise keskmise viga.
Tabeli "Õpilase kriteeriumi väärtused" järgi leiame väärtuse
 usaldustasemega 0,95 ja vabadusastmete arvuga k\u003d 100-1 \u003d 99. See võrdub 1,982-ga. Koos aritmeetilise keskmise ja statistilise vea väärtustega asendame selle valemiga:
usaldustasemega 0,95 ja vabadusastmete arvuga k\u003d 100-1 \u003d 99. See võrdub 1,982-ga. Koos aritmeetilise keskmise ja statistilise vea väärtustega asendame selle valemiga:
või 11.69  12,19
12,19
Seega võib 95% tõenäosusega väita, et selle normaaljaotuse üldine keskmine jääb vahemikku 11,69–12,19 mg%.
Näide 3.2
. Määrake üldise dispersiooni 95% usaldusvahemiku piirid (  ) kaltsiumi jaotumine ahvide veres, kui see on teada
) kaltsiumi jaotumine ahvide veres, kui see on teada  = 1,60, koos n
= 100.
= 1,60, koos n
= 100.
Probleemi lahendamiseks võite kasutada järgmist valemit:
Kus  on dispersiooni statistiline viga.
on dispersiooni statistiline viga.
Leidke valimi dispersiooni viga järgmise valemi abil:  . See on võrdne 0,11-ga. Tähendus t- kriteerium usalduse tõenäosusega 0,95 ja vabadusastmete arv k= 100–1 = 99 on teada eelmisest näitest.
. See on võrdne 0,11-ga. Tähendus t- kriteerium usalduse tõenäosusega 0,95 ja vabadusastmete arv k= 100–1 = 99 on teada eelmisest näitest.
Kasutame valemit ja saame:
või 1.38  1,82
1,82
Üldise dispersiooni täpsema usaldusvahemiku saab konstrueerida kasutades  (hii-ruut) – Pearsoni test. Selle kriteeriumi kriitilised punktid on toodud spetsiaalses tabelis. Kriteeriumi kasutamisel
(hii-ruut) – Pearsoni test. Selle kriteeriumi kriitilised punktid on toodud spetsiaalses tabelis. Kriteeriumi kasutamisel  usaldusvahemiku koostamiseks kasutatakse kahepoolset olulisuse taset. Alumise piiri jaoks arvutatakse olulisuse tase valemiga
usaldusvahemiku koostamiseks kasutatakse kahepoolset olulisuse taset. Alumise piiri jaoks arvutatakse olulisuse tase valemiga  , pealmise jaoks
, pealmise jaoks  . Näiteks usaldustaseme jaoks
. Näiteks usaldustaseme jaoks  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Vastavalt kriitiliste väärtuste jaotuse tabelile
= 0,990. Vastavalt kriitiliste väärtuste jaotuse tabelile  , arvutatud usaldustasemete ja vabadusastmete arvuga k= 100 – 1= 99, leidke väärtused
, arvutatud usaldustasemete ja vabadusastmete arvuga k= 100 – 1= 99, leidke väärtused  Ja
Ja  . Saame
. Saame  võrdub 135,80 ja
võrdub 135,80 ja  võrdub 70,06.
võrdub 70,06.
Üldise dispersiooni usalduspiiride leidmiseks kasutades  kasutame valemeid: alumise piiri jaoks
kasutame valemeid: alumise piiri jaoks  , ülemise piiri jaoks
, ülemise piiri jaoks  . Asendage leitud väärtused ülesande andmetega
. Asendage leitud väärtused ülesande andmetega  valemitesse:
valemitesse:  =
1,17;
=
1,17; = 2,26. Seega usaldustasemega P= 0,99 või 99%, üldine dispersioon jääb vahemikku 1,17 kuni 2,26 mg% (kaasa arvatud).
= 2,26. Seega usaldustasemega P= 0,99 või 99%, üldine dispersioon jääb vahemikku 1,17 kuni 2,26 mg% (kaasa arvatud).
Näide 3.3 . Elevaatorisse saabunud partii 1000 nisuseemne hulgast leiti 120 tungalteraga nakatunud seemet. On vaja kindlaks määrata nakatunud seemnete koguosa tõenäolised piirid antud nisupartiis.
Üldaktsia usalduspiirid kõigi selle võimalike väärtuste jaoks tuleks määrata järgmise valemiga:
 ,
,
Kus n on vaatluste arv; m on ühe rühma absoluutarv; t on normaliseeritud hälve.
Nakatunud seemnete proovifraktsioon on võrdne  või 12%. Usaldustasemega R= 95% normaliseeritud hälve ( t- Üliõpilase kriteerium k
=
või 12%. Usaldustasemega R= 95% normaliseeritud hälve ( t- Üliõpilase kriteerium k
=
 )t
= 1,960.
)t
= 1,960.
Asendame saadaolevad andmed valemiga:
Seega on usaldusvahemiku piirid  = 0,122–0,041 = 0,081 ehk 8,1%;
= 0,122–0,041 = 0,081 ehk 8,1%;  = 0,122 + 0,041 = 0,163 ehk 16,3%.
= 0,122 + 0,041 = 0,163 ehk 16,3%.
Seega võib 95% usaldustasemega väita, et nakatunud seemnete osakaal on kokku vahemikus 8,1–16,3%.
Näide 3.4 . Variatsioonikoefitsient, mis iseloomustab kaltsiumi (mg%) varieerumist ahvide vereseerumis, oli 10,6%. Näidissuurus n= 100. Üldparameetri jaoks on vaja määrata 95% usaldusvahemiku piirid CV.
Üldise variatsioonikordaja usalduspiirid CV määratakse järgmiste valemitega:
 Ja
Ja  , Kus K
valemiga arvutatud vaheväärtus
, Kus K
valemiga arvutatud vaheväärtus  .
.
Teades seda usaldustasemega R= 95% normaliseeritud hälve (õpilase t-test k
=
 )t
= 1,960, arvutage väärtus eelnevalt SAADA:
)t
= 1,960, arvutage väärtus eelnevalt SAADA:
 .
.
 ehk 9,3%
ehk 9,3%
 ehk 12,3%
ehk 12,3%
Seega jääb üldine variatsioonikoefitsient usalduse tõenäosusega 95% vahemikku 9,3–12,3%. Korduvate proovide puhul ei ületa variatsioonikoefitsient 12,3% ega lange alla 9,3% 95 juhul 100-st.
Küsimused enesekontrolliks:

Ülesanded iseseisvaks lahendamiseks.
1. Kholmogory ristandite lehmade laktatsiooni keskmine rasvasisaldus piimas oli järgmine: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Seadke üldise keskmise usaldusvahemikud 95% usaldustasemele (20 punkti).
2. 400 hübriidrukki taimel ilmusid esimesed õied keskmiselt 70,5 päeva pärast külvi. Standardhälve oli 6,9 päeva. Määrake populatsiooni keskmise ja dispersiooni keskmiste ja usaldusvahemike viga olulisuse tasemel W= 0,05 ja W= 0,01 (25 punkti).
3. Aedmaasika 502 isendi lehtede pikkuse uurimisel saadi järgmised andmed:
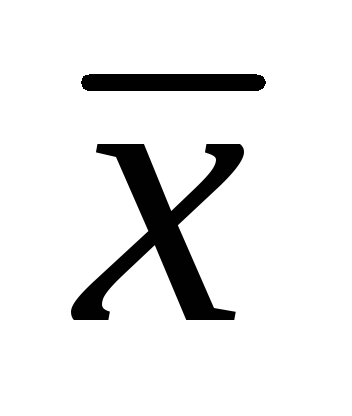 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm Määrake populatsiooni aritmeetilise keskmise usaldusvahemikud olulisuse tasemetega 0,01; 0,02; 0,05. (25 punkti).
\u003d ± 0,06 cm Määrake populatsiooni aritmeetilise keskmise usaldusvahemikud olulisuse tasemetega 0,01; 0,02; 0,05. (25 punkti).
4. 150 täiskasvanud meest uurides oli keskmine pikkus 167 cm ja σ \u003d 6 cm Mis on üldise keskmise ja üldise dispersiooni piirid usalduse tõenäosusega 0,99 ja 0,95? (25 punkti).
5. Kaltsiumi jaotumist ahvide vereseerumis iseloomustavad järgmised selektiivnäitajad:
 = 11,94 mg%, σ
= 1,27, n
= 100. Joonistage selle jaotuse populatsiooni keskmise 95% usaldusvahemik. Arvuta variatsioonikordaja (25 punkti).
= 11,94 mg%, σ
= 1,27, n
= 100. Joonistage selle jaotuse populatsiooni keskmise 95% usaldusvahemik. Arvuta variatsioonikordaja (25 punkti).
6. Uuriti üldlämmastiku sisaldust albiinorottide vereplasmas vanuses 37 ja 180 päeva. Tulemused on väljendatud grammides 100 cm3 plasma kohta. 37 päeva vanuselt oli 9 rotil: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. 180 päeva vanuselt oli 8 rotil: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Määra erinevuse usaldusvahemikud usaldustasemega 0,95 (50 punkti).
7. Määrake ahvide vereseerumis kaltsiumi (mg%) jaotuse üldise dispersiooni 95% usaldusvahemiku piirid, kui selle jaotuse korral valimi suurus n = 100, proovi dispersiooni statistiline viga s σ 2 = 1,60 (40 punkti).
8. Määrake nisu 40 teravilja pikkuse jaotuse üldise dispersiooni 95% usaldusvahemiku piirid (σ 2 = 40,87 mm 2). (25 punkti).
9. Suitsetamist peetakse peamiseks obstruktiivse kopsuhaiguse eelsoodumuse teguriks. Passiivset suitsetamist selliseks teguriks ei peeta. Teadlased seadsid kahtluse alla passiivse suitsetamise ohutuse ja uurisid mittesuitsetajate, passiivsete ja aktiivsete suitsetajate hingamisteid. Hingamisteede seisundi iseloomustamiseks võtsime ühe välise hingamise funktsiooni näitaja - väljahingamise keskpaiga maksimaalse mahulise kiiruse. Selle indikaatori vähenemine on märk hingamisteede halvenemisest. Küsitluse andmed on toodud tabelis.
|
Uuritud arv |
Maksimaalne keskmise väljahingamise voolukiirus, l/s |
||
|
Standardhälve |
|||
|
Mittesuitsetajad |
|||
|
töötada mittesuitsetajate piirkonnas | |||
|
tööd suitsu täis ruumis | |||
|
suitsetajad |
|||
|
väikese hulga sigarettide suitsetamine | |||
|
keskmine sigarettide suitsetajate arv | |||
|
suure hulga sigarettide suitsetamine | |||
Leidke tabelist iga rühma üldise keskmise ja üldise dispersiooni 95% usaldusvahemikud. Millised on rühmadevahelised erinevused? Esitage tulemused graafiliselt (25 punkti).
10. Määrake 64 poegimise põrsaste arvu üldise dispersiooni 95% ja 99% usaldusvahemike piirid, kui valimi dispersiooni statistiline viga s σ 2 = 8,25 (30 punkti).
11. Teadaolevalt on küülikute keskmine kaal 2,1 kg. Määrake üldise keskmise ja dispersiooni 95% ja 99% usaldusvahemike piirid, kui n= 30, σ = 0,56 kg (25 punkti).
12. 100 varvas mõõdeti kõrre terasisaldus ( X), teraviku pikkus ( Y) ja teravilja mass kõrvas ( Z). Leia usaldusvahemikud üldise keskmise ja dispersiooni jaoks P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 kui
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 punkti).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 punkti).
13. Juhuslikult valitud 100 talinisu kõrval loendati okkade arv. Valimikomplekti iseloomustasid järgmised näitajad:
 = 15 okast ja σ = 2,28 tk. Määrake täpsus, millega keskmine tulemus saadakse (
= 15 okast ja σ = 2,28 tk. Määrake täpsus, millega keskmine tulemus saadakse (  ) ja joonistage üldise keskmise ja dispersiooni usaldusvahemik 95% ja 99% olulisuse tasemetel (30 punkti).
) ja joonistage üldise keskmise ja dispersiooni usaldusvahemik 95% ja 99% olulisuse tasemetel (30 punkti).
14. Roiete arv fossiilse molluski kestadel Ortamboniidid kalligramma:
On teada, et n = 19, σ = 4,25. Määrake üldise keskmise ja üldise dispersiooni usaldusvahemiku piirid olulisuse tasemel W = 0,01 (25 punkti).
15. Kaubanduslikus piimafarmis piimatoodangu määramiseks määrati päevas 15 lehma produktiivsus. Aasta andmetel andis iga lehm päevas keskmiselt järgmise piimakoguse (l): 22; 19; 25; 20; 27; 17; kolmkümmend; 21; 18; 24; 26; 23; 25; 20; 24. Joonistage üldise dispersiooni ja aritmeetilise keskmise usaldusvahemikud. Kas võib eeldada, et aasta keskmine väljalüps lehma kohta on 10 000 liitrit? (50 punkti).
16. Talu keskmise nisusaagi määramiseks niideti 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 ja 2 ha suurustel proovilappidel. Saak (c/ha) proovitükkidest oli 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; vastavalt 29. Joonistage üldise dispersiooni ja aritmeetilise keskmise usaldusvahemikud. Kas on võimalik eeldada, et põllumajandusettevõtte keskmine saagikus on 42 c/ha? (50 punkti).