Интервали на доверба. Интервал на доверба
И други.Сите тие се проценки на нивните теоретски колеги, кои би можеле да се добијат доколку не постоеше примерок, туку општата популација. Но, за жал, општата популација е многу скапа и често недостапна.
Концептот на проценка на интервалот
Секоја проценка на примерокот има одредено расфрлање, бидејќи е случајна променлива во зависност од вредностите во одреден примерок. Затоа, за поверодостојни статистички заклучоци, треба да се знае не само проценката на поени, туку и интервалот, кој со голема веројатност γ (гама) го опфаќа проценетиот индикатор θ (тета).
Формално, ова се две такви вредности (статистички податоци) T1 (X)и T2 (X), што Т1< T 2 , за што на дадено ниво на веројатност γ е исполнет условот:
Накратко, веројатно е γ или повеќе вистинската вредност е помеѓу точките T1 (X)и T2 (X), кои се нарекуваат долна и горна граница интервал на доверба.
Еден од условите за конструирање на интервали на доверба е неговата максимална стеснетост, т.е. треба да биде што е можно пократко. Желбата е сосема природна, бидејќи. истражувачот се обидува попрецизно да го локализира наодот на саканиот параметар.
Следи дека интервалот на доверба треба да ги покрие максималните веројатности на распределбата. а самиот резултат да биде во центарот.
![]()
Односно, веројатноста за отстапување (на вистинскиот индикатор од проценката) нагоре е еднаква на веројатноста за отстапување надолу. Исто така, треба да се забележи дека за искривени распределби, интервалот десно не е еднаков на интервалот лево.
Сликата погоре јасно покажува дека колку е поголемо нивото на доверба, толку е поширок интервалот - директна врска.
Ова беше мал вовед во теоријата на интервална проценка на непознати параметри. Ајде да продолжиме кон наоѓање граници на доверба за математичкото очекување.
Интервал на доверба за математичко очекување
Ако оригиналните податоци се дистрибуираат преку , тогаш просекот ќе биде нормална вредност. Ова произлегува од правилото дека линеарната комбинација на нормални вредности има и нормална дистрибуција. Затоа, за да ги пресметаме веројатностите, би можеле да го искористиме математичкиот апарат на законот за нормална распределба.
Сепак, ова ќе бара познавање на два параметри - очекуваната вредност и варијансата, кои обично не се познати. Можете, се разбира, да користите проценки наместо параметри (аритметичка средина и ), но тогаш распределбата на средната вредност нема да биде сосема нормална, таа ќе биде малку срамнета со земја. Граѓанинот Вилијам Госет од Ирска вешто го забележал овој факт кога го објавил своето откритие во изданието на Биометрика од март 1908 година. За тајност, Госет потпиша со Студент. Вака се појави Студентската т-распределба.
Меѓутоа, нормалната дистрибуција на податоците, користена од К. Затоа, најдобро е да се отфрли претпоставката за нормалност и да се користат методи кои не зависат од дистрибуцијата на оригиналните податоци.
Се поставува прашањето: каква е распределбата на аритметичката средина ако се пресметува од податоците на непозната распределба? Одговорот го дава добро познатата во теоријата на веројатност Теорема на централна граница(CPT). Во математиката, постојат неколку негови верзии (формулациите се рафинирани со текот на годините), но сите тие, грубо кажано, се сведуваат на изјавата дека збирот на голем број независни случајни променливи го почитува законот за нормална распределба.
При пресметување на аритметичката средина се користи збирот на случајни променливи. Од ова излегува дека аритметичката средина има нормална распределба, во која очекуваната вредност е очекуваната вредност на оригиналниот податок, а варијансата е .
Паметните луѓе знаат како да го докажат CLT, но ние ќе го потврдиме тоа со помош на експеримент спроведен во Excel. Ајде да симулираме примерок од 50 рамномерно распределени случајни променливи (со користење на функцијата Excel RANDOMBETWEEN). Потоа ќе направиме 1000 такви примероци и ќе ја пресметаме аритметичката средина за секој. Да ја погледнеме нивната дистрибуција.

Се гледа дека распределбата на просекот е блиску до нормалниот закон. Ако обемот на примероците и нивниот број се направат уште поголеми, тогаш сличноста ќе биде уште подобра.
Сега кога самите ја видовме валидноста на CLT, можеме, користејќи , да ги пресметаме интервалите на доверба за аритметичката средина, кои ја покриваат вистинската средина или математичкото очекување со дадена веројатност.
За да се утврдат горните и долните граници, потребно е да се знаат параметрите на нормалната дистрибуција. Како по правило, тие не се, затоа се користат проценки: аритметичко значењеи варијанса на примерокот. Повторно, овој метод дава добра апроксимација само за големи примероци. Кога примероците се мали, често се препорачува да се користи Студентска дистрибуција. Не верувај! Студентската распределба за средната вредност се јавува само кога оригиналните податоци имаат нормална дистрибуција, односно речиси никогаш. Затоа, подобро е веднаш да се постави минималната лента за количината на потребните податоци и да се користат асимптотички точни методи. Велат доволни се 30 набљудувања. Земете 50 - не можете да погрешите.
![]()
Т 1.2се долните и горните граници на интервалот на доверба
– примерок аритметичка средина
s0– стандардна девијација на примерокот (непристрасно)
n - големина на примерокот
γ – ниво на доверба (обично еднакво на 0,9, 0,95 или 0,99)
c γ =Φ -1 ((1+γ)/2)е реципроцитет на стандардната нормална функција на дистрибуција. Во едноставни термини, ова е бројот на стандардни грешки од аритметичката средина до долната или горната граница (наведените три веројатности одговараат на вредностите од 1,64, 1,96 и 2,58).
Суштината на формулата е дека се зема аритметичката средина и потоа се издвојува одредена количина од неа ( со γ) стандардни грешки ( s 0 /√n). Се се знае, земете и сметајте.
Пред масовната употреба на персоналните компјутери, за да се добијат вредностите на функцијата за нормална дистрибуција и нејзината инверзна, користеле . Тие сè уште се користат, но поефикасно е да се свртиме кон готови формули на Excel. Сите елементи од формулата погоре ( , и ) може лесно да се пресметаат во Excel. Но, постои и готова формула за пресметување на интервалот на доверба - НОРМА НА ДОВЕРБА. Неговата синтакса е следна.
НОРМА НА ДОВЕРБА (алфа, стандардно_dev, големина)
алфа– ниво на значајност или ниво на доверба, кое во горната нотација е еднакво на 1-γ, т.е. веројатноста дека математичкатаочекувањето ќе биде надвор од интервалот на доверба. Со ниво на доверба од 0,95, алфата е 0,05, итн.
стандардно_исклученое стандардното отстапување на податоците од примерокот. Не треба да ја пресметувате стандардната грешка, Excel ќе се подели со коренот на n.
големината– големина на примерокот (n).
Резултатот од функцијата CONFIDENCE.NORM е вториот член од формулата за пресметување на интервалот на доверба, т.е. полу-интервал. Според тоа, долните и горните точки се просечната ± добиената вредност.
Така, можно е да се изгради универзален алгоритам за пресметување на интервали на доверба за аритметичката средина, што не зависи од распределбата на почетните податоци. Цената за универзалноста е нејзината асимптотична природа, т.е. потребата да се користат релативно големи примероци. Меѓутоа, во ерата на модерната технологија, собирањето на точниот износ на податоци обично не е тешко.
Тестирање на статистички хипотези користејќи интервал на доверба
(модул 111)
Еден од главните проблеми што се решаваат во статистиката е. Накратко, неговата суштина е ова. Се прави претпоставка, на пример, дека очекувањата на општата популација се еднакви на некоја вредност. Потоа се конструира дистрибуција на примероци средства, што може да се набљудува со дадено очекување. Следно, гледаме каде во оваа условна распределба се наоѓа реалниот просек. Ако ги надмине дозволените граници, тогаш појавата на таков просек е многу малку веројатна, а со едно повторување на експериментот е речиси невозможно, што е во спротивност со поставената хипотеза, која е успешно отфрлена. Ако просекот не оди подалеку од критичното ниво, тогаш хипотезата не се отфрла (но и не се докажува!).
Значи, со помош на интервали на доверба, во нашиот случај за очекување, можете да тестирате и некои хипотези. Тоа е многу лесно да се направи. Да претпоставиме дека аритметичката средина за некој примерок е 100. Се тестира хипотезата дека очекуваната вредност е, да речеме, 90. Односно, ако го поставиме прашањето примитивно, тоа звучи вака: дали со вистинската вредност на просек еднаков на 90, забележаниот просек беше 100?
За да се одговори на ова прашање, ќе бидат потребни дополнителни информации за стандардното отстапување и големината на примерокот. Да речеме дека стандардното отстапување е 30, а бројот на набљудувања е 64 (за лесно да се извлече коренот). Тогаш стандардната грешка на средната вредност е 30/8 или 3,75. За да го пресметате интервалот на доверливост од 95%, ќе треба да издвоите две стандардни грешки од двете страни на средната вредност (поточно, 1,96). Интервалот на доверба ќе биде приближно 100 ± 7,5, или од 92,5 до 107,5.
Понатамошното размислување е како што следува. Ако тестираната вредност паѓа во интервалот на доверба, тогаш тоа не е во спротивност со хипотезата, бидејќи се вклопува во границите на случајни флуктуации (со веројатност од 95%). Ако тестираната точка е надвор од интервалот на доверба, тогаш веројатноста за таков настан е многу мала, во секој случај под прифатливото ниво. Оттука, хипотезата се отфрла како контрадикторна со набљудуваните податоци. Во нашиот случај, хипотезата за очекување е надвор од интервалот на доверливост (тестираната вредност од 90 не е вклучена во интервалот од 100±7,5), па затоа треба да се отфрли. Одговарајќи на примитивното прашање погоре, треба да се каже: не, не може, во секој случај, ова се случува исклучително ретко. Често, ова укажува на специфична веројатност за погрешно отфрлање на хипотезата (p-ниво), а не на дадено ниво, според кое е изграден интервалот на доверба, туку повеќе за тоа друг пат.
Како што можете да видите, не е тешко да се изгради интервал на доверба за средната вредност (или математичкото очекување). Главната работа е да се фати суштината, а потоа работите ќе одат. Во пракса, повеќето го користат интервалот на доверливост од 95%, што е широко околу две стандардни грешки од двете страни на средната вредност.
Тоа е се за сега. Се најдобро!
Проценка на интервали на доверба
Цели на учење
Статистиката го разгледува следново две главни задачи:
Имаме некаква проценка заснована на примерок податоци и сакаме да дадеме некоја веројатност за тоа каде е вистинската вредност на параметарот што се проценува.
Имаме специфична хипотеза која треба да се тестира врз основа на податоците од примерокот.
Во оваа тема го разгледуваме првиот проблем. Воведуваме и дефиниција за интервал на доверба.
Интервал на доверливост е интервал кој е изграден околу проценетата вредност на параметарот и покажува каде лежи вистинската вредност на проценетиот параметар со априори дадена веројатност.
По проучувањето на материјалот на оваа тема, вие:
дознајте кој е интервалот на доверливост на проценката;
да научи да ги класифицира статистичките проблеми;
совладување на техниката на конструирање интервали на доверба, и со користење на статистички формули и со користење на софтверски алатки;
научете да ги одредувате потребните големини на примероци за да постигнете одредени параметри на точноста на статистичките проценки.
Дистрибуции на карактеристиките на примерокот
Т-дистрибуција
Како што беше дискутирано погоре, распределбата на случајната променлива е блиску до стандардизирана нормална дистрибуција со параметрите 0 и 1. Бидејќи не ја знаеме вредноста на σ, ја заменуваме со некоја проценка s . Количината веќе има различна распределба, имено, или Распределба на студентите, што се одредува со параметарот n -1 (број на степени на слобода). Оваа дистрибуција е блиску до нормалната дистрибуција (колку е поголема n, толку се поблиску распределбите).
На сл. 95  Претставена е студентска распределба со 30 степени на слобода. Како што можете да видите, таа е многу блиску до нормалната дистрибуција.
Претставена е студентска распределба со 30 степени на слобода. Како што можете да видите, таа е многу блиску до нормалната дистрибуција.
Слично на функциите за работа со нормална дистрибуција NORMDIST и NORMINV, постојат функции за работа со t-дистрибуција - STUDIST (TDIST) и STUDRASPBR (TINV). Пример за употреба на овие функции може да се најде во датотеката STUDRIST.XLS (шаблон и решение) и на сл. 96  .
.
Дистрибуции на други карактеристики
Како што веќе знаеме, за да се одреди точноста на проценката на очекувањата, потребна ни е t-распределба. За да се проценат други параметри, како што е варијансата, потребни се други распределби. Две од нив се F-дистрибуцијата и x 2 -дистрибуција.
Интервал на доверба за средната вредност
Интервал на довербае интервал кој е изграден околу проценетата вредност на параметарот и покажува каде лежи вистинската вредност на проценетиот параметар со априори дадена веројатност.
Настанува изградба на интервал на доверба за средната вредност на следниот начин:
Пример
Ресторанот за брза храна планира да го прошири својот асортиман со нов вид сендвичи. За да ја процени побарувачката за него, менаџерот планира по случаен избор да избере 40 посетители од оние кои веќе го пробале и да побара од нив да го оценат својот став кон новиот производ на скала од 1 до 10. Менаџерот сака да го процени очекуваниот број на поени што ќе ги добие новиот производ и ќе изгради интервал на доверба од 95% за оваа проценка. Како да се направи тоа? (видете ја датотеката SANDWICH1.XLS (шаблон и решение).
Решение
За да го решите овој проблем, можете да го користите. Резултатите се претставени на сл. 97  .
.
Интервал на доверба за вкупната вредност
Понекогаш, според податоците од примерокот, потребно е да се процени не математичкото очекување, туку вкупниот збир на вредности. На пример, во ситуација со ревизор, може да биде од интерес да се процени не просечната вредност на фактурата, туку збирот на сите фактури.
Нека N е вкупниот број на елементи, n е големината на примерокот, T 3 е збирот на вредностите во примерокот, T" е проценката за збирот на целата популација, потоа ![]() , а интервалот на доверба се пресметува со формулата, каде што s е проценка на стандардното отстапување за примерокот, е проценка на средната вредност за примерокот.
, а интервалот на доверба се пресметува со формулата, каде што s е проценка на стандардното отстапување за примерокот, е проценка на средната вредност за примерокот.
Пример
Да речеме дека даночната канцеларија сака да го процени износот на вкупните даночни поврати за 10.000 даночни обврзници. Даночниот обврзник или добива поврат или плаќа дополнителни даноци. Најдете го интервалот на доверливост од 95% за износот на рефундирање, претпоставувајќи големина на примерок од 500 луѓе (видете ја датотеката REFUND AMOUNT.XLS (шаблон и решение).
Решение
Нема посебна процедура во StatPro за овој случај, сепак, можете да видите дека границите може да се добијат од границите за средната вредност користејќи ги горенаведените формули (сл. 98  ).
).
Интервал на доверба за пропорција
Нека p е очекување на дел од клиентите, а pv е проценка на овој удел, добиена од примерок со големина n. Може да се покаже дека за доволно големи  проценетата распределба ќе биде блиску до нормалата со средна p и стандардна девијација
проценетата распределба ќе биде блиску до нормалата со средна p и стандардна девијација ![]() . Стандардната грешка на проценката во овој случај се изразува како
. Стандардната грешка на проценката во овој случај се изразува како  , и интервалот на доверба како
, и интервалот на доверба како  .
.
Пример
Ресторанот за брза храна планира да го прошири својот асортиман со нов вид сендвичи. За да ја процени побарувачката за него, менаџерот по случаен избор избра 40 посетители од оние кои веќе го пробале и побарал од нив да го оценат својот став кон новиот производ на скала од 1 до 10. Менаџерот сака да ја процени очекуваната пропорција на клиенти кои го оценуваат новиот производ со најмалку 6 поени (тој очекува овие клиенти да бидат потрошувачи на новиот производ).
Решение
Првично, создаваме нова колона врз основа на 1 ако резултатот на клиентот е повеќе од 6 поени и 0 во спротивно (видете ја датотеката SANDWICH2.XLS (шаблон и решение).
Метод 1
Броејќи го износот од 1, го проценуваме учеството, а потоа ги користиме формулите.
Вредноста на z cr се зема од специјални табели за нормална дистрибуција (на пример, 1,96 за 95% интервал на доверба).
Користејќи го овој пристап и конкретни податоци за да се изгради интервал од 95%, ги добиваме следните резултати (сл. 99  ). Критичната вредност на параметарот z cr е 1,96. Стандардната грешка на проценката е 0,077. Долната граница на интервалот на доверба е 0,475. Горната граница на интервалот на доверба е 0,775. Така, менаџерот може со сигурност од 95% да претпостави дека процентот на клиенти кои го оценуваат новиот производ со 6 поени или повеќе ќе биде помеѓу 47,5 и 77,5.
). Критичната вредност на параметарот z cr е 1,96. Стандардната грешка на проценката е 0,077. Долната граница на интервалот на доверба е 0,475. Горната граница на интервалот на доверба е 0,775. Така, менаџерот може со сигурност од 95% да претпостави дека процентот на клиенти кои го оценуваат новиот производ со 6 поени или повеќе ќе биде помеѓу 47,5 и 77,5.
Метод 2
Овој проблем може да се реши со користење на стандардни StatPro алатки. За да го направите ова, доволно е да се забележи дека уделот во овој случај се совпаѓа со просечната вредност на колоната Тип. Следно аплицирајте StatPro/Статистички заклучок/анализа со еден примерокда се изгради интервал на доверба за средната вредност (проценка на очекувањата) за колоната Тип. Добиените резултати во овој случај ќе бидат многу блиску до резултатот од 1-виот метод (сл. 99).
Интервал на доверба за стандардно отстапување
s се користи како проценка на стандардното отстапување (формулата е дадена во Дел 1). Функцијата за густина на проценката s е функцијата хи-квадрат, која, како и t-распределбата, има n-1 степени на слобода. Постојат специјални функции за работа со оваа дистрибуција CHI2DIST (CHIDIST) и CHI2OBR (CHIINV) .
Интервалот на доверба во овој случај повеќе нема да биде симетричен. Условната шема на границите е прикажана на сл. Сто .
Пример
Машината треба да произведува делови со пречник од 10 см.Но, поради различни околности се појавуваат грешки. Контролорот за квалитет е загрижен за две работи: прво, просечната вредност треба да биде 10 см; второ, дури и во овој случај, ако отстапувањата се големи, тогаш многу детали ќе бидат отфрлени. Секој ден прави примерок од 50 делови (види датотека QUALITY CONTROL.XLS (шаблон и решение) Какви заклучоци може да даде таков примерок?
Решение
Ние конструираме 95% интервали на доверба за средната вредност и за стандардното отстапување користејќи StatPro/Статистички заклучоци/ Анализа со еден примерок(Сл. 101  ).
).
Понатаму, користејќи ја претпоставката за нормална дистрибуција на дијаметри, го пресметуваме процентот на неисправни производи, поставувајќи максимално отстапување од 0,065. Користејќи ги можностите на табелата за пребарување (случајот на два параметри), ја конструираме зависноста на процентот на одбиени од средната вредност и стандардното отстапување (сл. 102  ).
).
Интервал на доверба за разлика од две средства
Ова е една од најважните примени на статистичките методи. Примери за состојби.
Менаџерот на продавница за облека би сакал да знае колку повеќе или помалку просечниот женски купувач троши во продавницата отколку маж.
Двете авиокомпании летаат на слични линии. Една организација на потрошувачи би сакала да ја спореди разликата помеѓу просечното очекувано време на одложување на летот за двете авиокомпании.
Компанијата испраќа купони за одредени видови стоки во еден град, а не испраќа во друг. Менаџерите сакаат да ги споредат просечните набавки на овие артикли во следните два месеци.
Дилер на автомобили често се занимава со брачни парови на презентации. За да се разберат нивните лични реакции на презентацијата, паровите честопати се интервјуирани одделно. Менаџерот сака да ја оцени разликата во оценките дадени од мажи и жени.
Случај на независни примероци
Средната разлика ќе има t-распределба со n 1 + n 2 - 2 степени на слобода. Интервалот на доверба за μ 1 - μ 2 се изразува со односот:

Овој проблем може да се реши не само со горенаведените формули, туку и со стандардните StatPro алатки. За да го направите ова, доволно е да аплицирате
Интервал на доверба за разлика помеѓу пропорциите
Нека биде математичкото очекување на акциите. Нека се нивните примероци проценки изградени на примероци со големина n 1 и n 2, соодветно. Потоа е проценка за разликата. Затоа, интервалот на доверба за оваа разлика се изразува како:
Овде z cr е вредноста добиена од нормалната распределба на специјални табели (на пример, 1,96 за 95% интервал на доверба).
Стандардната грешка на проценката во овој случај се изразува со релацијата:
 .
.
Пример
Продавницата, подготвувајќи се за големата распродажба, го презеде следното маркетинг истражување. Најдобрите 300 купувачи беа избрани и по случаен избор поделени во две групи од по 150 членови. На сите избрани купувачи им беа испратени покани за учество во распродажбата, но само за членовите од првата група беше прикачен купон со право на попуст од 5%. При продажбата евидентирани се набавките на сите 300 избрани купувачи. Како може менаџерот да ги протолкува резултатите и да донесе пресуда за ефективноста на купонирањето? (Видете ја датотеката COUPONS.XLS (шаблон и решение)).
Решение
За нашиот конкретен случај, од 150 клиенти кои добиле купон за попуст, 55 купиле на распродажба, а меѓу 150 кои не добиле купон, само 35 купиле (сл. 103  ). Тогаш вредностите на пропорциите на примерокот се 0,3667 и 0,2333, соодветно. И разликата во примерокот меѓу нив е еднаква на 0,1333, соодветно. Претпоставувајќи интервал на доверба од 95%, наоѓаме од табелата за нормална дистрибуција z cr = 1,96. Пресметката на стандардната грешка на разликата во примерокот е 0,0524. Конечно, добиваме дека долната граница на интервалот на доверба од 95% е 0,0307, а горната граница е 0,2359, соодветно. Добиените резултати може да се толкуваат на тој начин што на секои 100 клиенти кои добиле купон за попуст, можеме да очекуваме од 3 до 23 нови клиенти. Сепак, треба да се има предвид дека овој заклучок сам по себе не значи ефикасност на користење на купони (бидејќи со обезбедување на попуст губиме во добивка!). Ајде да го покажеме ова на конкретни податоци. Да претпоставиме дека просечниот износ за купување е 400 рубли, од кои 50 рубли. има профит од продавницата. Тогаш очекуваниот профит на 100 клиенти кои не добиле купон е еднаков на:
). Тогаш вредностите на пропорциите на примерокот се 0,3667 и 0,2333, соодветно. И разликата во примерокот меѓу нив е еднаква на 0,1333, соодветно. Претпоставувајќи интервал на доверба од 95%, наоѓаме од табелата за нормална дистрибуција z cr = 1,96. Пресметката на стандардната грешка на разликата во примерокот е 0,0524. Конечно, добиваме дека долната граница на интервалот на доверба од 95% е 0,0307, а горната граница е 0,2359, соодветно. Добиените резултати може да се толкуваат на тој начин што на секои 100 клиенти кои добиле купон за попуст, можеме да очекуваме од 3 до 23 нови клиенти. Сепак, треба да се има предвид дека овој заклучок сам по себе не значи ефикасност на користење на купони (бидејќи со обезбедување на попуст губиме во добивка!). Ајде да го покажеме ова на конкретни податоци. Да претпоставиме дека просечниот износ за купување е 400 рубли, од кои 50 рубли. има профит од продавницата. Тогаш очекуваниот профит на 100 клиенти кои не добиле купон е еднаков на:
50 0,2333 100 \u003d 1166,50 рубли.
Слични пресметки за 100 купувачи кои добиле купон даваат:
30 0,3667 100 \u003d 1100,10 рубли.
Намалувањето на просечната добивка на 30 се објаснува со фактот дека, користејќи го попустот, купувачите кои добиле купон, во просек, ќе купат за 380 рубли.
Така, конечниот заклучок укажува на неефикасноста на користењето на вакви купони во оваа конкретна ситуација.
Коментар. Овој проблем може да се реши со користење на стандардни StatPro алатки. За да го направите ова, доволно е овој проблем да се сведе на проблемот на проценување на разликата од два просеци со методот, а потоа да се примени StatPro/Статистички заклучок/Анализа со два примероцида се изгради интервал на доверба за разликата помеѓу две средни вредности.
Контрола на интервал на доверба
Должината на интервалот на доверба зависи од следните услови:
директно податоци (стандардна девијација);
ниво на значајност;
големина на примерокот.
Големина на примерок за проценка на средната вредност
Ајде прво да го разгледаме проблемот во општиот случај. Дозволете ни да ја означиме вредноста на половина од должината на интервалот на доверба што ни е даден како B (сл. 104  ). Знаеме дека интервалот на доверба за средната вредност на некоја случајна променлива X се изразува како
). Знаеме дека интервалот на доверба за средната вредност на некоја случајна променлива X се изразува како ![]() , каде
, каде ![]() . Претпоставувајќи:
. Претпоставувајќи:
![]() и изразувајќи n , добиваме .
и изразувајќи n , добиваме .
За жал, не ја знаеме точната вредност на варијансата на случајната променлива X. Дополнително, не ја знаеме вредноста на t cr бидејќи зависи од n преку бројот на степени на слобода. Во оваа ситуација, можеме да го направиме следново. Наместо варијансата s, ние користиме одредена проценка на варијансата за некои достапни остварувања на случајната променлива што се проучува. Наместо вредноста t cr, ја користиме вредноста z cr за нормална распределба. Ова е сосема прифатливо, бидејќи функциите на густина за нормалната и t-распределбата се многу блиски (освен за случајот со мало n ). Така, саканата формула ја добива формата:
 .
.
Бидејќи формулата дава, општо земено, нецелобројни резултати, заокружувањето со вишок од резултатот се зема како саканата големина на примерокот.
Пример
Ресторанот за брза храна планира да го прошири својот асортиман со нов вид сендвичи. За да ја процени побарувачката за него, менаџерот по случаен избор планира да избере одреден број посетители од оние кои веќе го пробале и да побара од нив да го оценат својот став кон новиот производ на скала од 1 до 10. Менаџерот сака да се процени очекуваниот број на поени што ќе ги добие новиот производ.производ и да го нацртате интервалот на доверливост од 95% на таа проценка. Сепак, тој сака половина од ширината на интервалот на доверба да не надминува 0,3. Колку посетители му требаат за да анкетира?
како што следи:

Еве р отсе проценка на дропот p, а B е дадена половина од должината на интервалот на доверба. Надуена вредност за n може да се добие со помош на вредноста р отс= 0,5. Во овој случај, должината на интервалот на доверба нема да ја надмине дадената вредност B за која било вистинска вредност на стр.
Пример
Нека менаџерот од претходниот пример планира да го процени процентот на клиенти кои претпочитаат нов тип на производ. Тој сака да изгради интервал на доверба од 90%, чија половина должина е помала или еднаква на 0,05. Колку клиенти треба да бидат земени по случаен избор?
Решение
Во нашиот случај, вредноста на z cr = 1,645. Затоа, потребната количина се пресметува како  .
.
Ако менаџерот има причина да верува дека саканата вредност на p е, на пример, околу 0,3, тогаш со замена на оваа вредност во горната формула, ќе добиеме помала вредност на случајниот примерок, имено 228.
Формула за одредување случајни големини на примерокот во случај на разлика помеѓу две средстванапишано како:
 .
.
Пример
Некои компјутерски компании имаат центар за услуги на клиентите. Во последно време се зголеми бројот на поплаки на клиентите за лошиот квалитет на услугата. Сервисниот центар главно вработува два вида вработени: оние со мало искуство, но кои имаат завршено специјални курсеви за обука и оние со долгогодишно практично искуство, но кои немаат завршено посебни курсеви. Компанијата сака да ги анализира поплаките на клиентите во изминатите шест месеци и да го спореди нивниот просечен број по секоја од двете групи вработени. Се претпоставува дека бројките во примероците за двете групи ќе бидат исти. Колку вработени мора да бидат вклучени во примерокот за да се добие интервал од 95% со половина должина не повеќе од 2?
Решение
Овде σ ots е проценка на стандардното отстапување на двете случајни променливи под претпоставка дека тие се блиски. Така, во нашата задача, треба некако да ја добиеме оваа проценка. Ова може да се направи, на пример, на следниов начин. Гледајќи ги податоците за поплаките на клиентите во изминатите шест месеци, менаџерот може да забележи дека генерално има помеѓу 6 и 36 поплаки по вработен. Знаејќи дека за нормална дистрибуција, практично сите вредности не се повеќе од три стандардни отстапувања од средната вредност, тој разумно може да верува дека:
![]() , од каде σ ots = 5.
, од каде σ ots = 5.
Заменувајќи ја оваа вредност во формулата, добиваме  .
.
Формула за одредување големината на случаен примерок во случај на проценка на разликата помеѓу акциитеизгледа како:

Пример
Некоја компанија има две фабрики за производство на слични производи. Менаџерот на една компанија сака да ги спореди стапките на дефекти на двете фабрики. Според достапните информации, стапката на отфрлање во двете фабрики е од 3 до 5%. Се претпоставува дека ќе изгради интервал на доверба од 99% со половина должина од не повеќе од 0,005 (или 0,5%). Колку производи треба да се изберат од секоја фабрика?
Решение
Овде p 1ot и p 2ot се проценки на две непознати фракции на отфрлања во 1-та и 2-та фабрика. Ако ставиме p 1ots \u003d p 2ots \u003d 0,5, тогаш ќе добиеме преценета вредност за n. Но бидејќи во нашиот случај имаме некои априори информации за овие акции, ја земаме горната проценка на овие акции, имено 0,05. Добиваме
Кога се проценуваат некои параметри на популацијата од податоците од примерокот, корисно е да се обезбеди не само точка проценка на параметарот, туку и интервал на доверба што покажува каде може да лежи точната вредност на параметарот што се проценува.
Во ова поглавје се запознавме и со квантитативните односи кои ни овозможуваат да изградиме такви интервали за различни параметри; научил начини за контрола на должината на интервалот на доверба.
Исто така, забележуваме дека проблемот со проценката на големината на примерокот (проблемот за планирање на експериментот) може да се реши со користење на стандардни StatPro алатки, имено StatPro/Статистички заклучок/Избор на големина на примерок.
ИНТЕРВАЛИ НА ДОВЕРБА ЗА ФРЕКЕНЦИИ И ДЕЛОВИ
© 2008 година
Национален институт за јавно здравје, Осло, Норвешка
Статијата го опишува и дискутира пресметувањето на интервалите на доверливост за фреквенции и пропорции со помош на методите Wald, Wilson, Klopper-Pearson, користејќи ја аголната трансформација и методот Wald со Agresti-Cowll корекција. Презентираниот материјал дава општи информации за методите за пресметување интервали на доверливост за фреквенции и пропорции и е наменет да го разбуди интересот на читателите на списанието не само за користење интервали на доверба при презентирање на резултатите од сопственото истражување, туку и за читање специјализирана литература пред започнување со работа на идни публикации.
Клучни зборови: интервал на доверба, фреквенција, пропорција
Во една од претходните публикации, описот на квалитативните податоци беше накратко споменат и беше објавено дека нивната проценка на интервалот се претпочита од точкеста проценка за опишување на зачестеноста на појавата на проучуваната карактеристика кај општата популација. Навистина, бидејќи студиите се спроведуваат со користење на податоци од примерокот, проекцијата на резултатите на општата популација мора да содржи елемент на неточност во проценката на примерокот. Интервалот на доверба е мерка за точноста на проценетиот параметар. Интересно е што во некои медицински учебници за основна статистика, темата за интервалите на доверливост за фреквенциите е целосно игнорирана. Во оваа статија, ќе разгледаме неколку начини за пресметување на интервалите на доверливост за фреквенциите, претпоставувајќи ги карактеристиките на примерокот како што се неповторливоста и репрезентативноста, како и независноста на набљудувањата едни од други. Фреквенцијата во оваа статија не се подразбира како апсолутна бројка што покажува колку пати оваа или онаа вредност се јавува во збирот, туку релативна вредност што го одредува процентот на учесници во студијата кои ја имаат особината што се проучува.
Во биомедицинските истражувања најчесто се користат 95% интервали на доверба. Овој интервал на доверба е регионот во кој вистинската пропорција паѓа 95% од времето. Со други зборови, може да се каже со 95% сигурност дека вистинската вредност на фреквенцијата на појава на особина кај општата популација ќе биде во рамките на интервалот на доверба од 95%.
Повеќето статистички учебници за медицински истражувачи известуваат дека грешката на фреквенцијата се пресметува со помош на формулата
каде што p е фреквенцијата на појавување на карактеристиката во примерокот (вредност од 0 до 1). Во повеќето домашни научни написи е означена вредноста на фреквенцијата на појава на карактеристика во примерокот (p), како и нејзината грешка (и) во форма на p ± s. Сепак, поцелисходно е да се прикаже интервал на доверливост од 95% за зачестеноста на појавата на некоја карактеристика кај општата популација, што ќе вклучува вредности од
 |
 пред.
пред.
Во некои учебници, за мали примероци, се препорачува да се замени вредноста од 1,96 со вредност од t за N - 1 степени на слобода, каде што N е бројот на набљудувања во примерокот. Вредноста на t се наоѓа во табелите за т-дистрибуција, кои се достапни во скоро сите учебници по статистика. Употребата на дистрибуција на t за методот Wald не дава видливи предности во однос на другите методи дискутирани подолу, и затоа не е добредојдена од некои автори.
Горенаведениот метод за пресметување интервали на доверливост за фреквенции или фракции е именуван по Абрахам Валд (Абрахам Валд, 1902–1950), бидејќи почнал да се користи нашироко по објавувањето на Волд и Волфовиц во 1939 година. Сепак, самиот метод бил предложен од Пјер Симон Лаплас (1749–1827) уште во 1812 година.
Методот Wald е многу популарен, но неговата примена е поврзана со значителни проблеми. Методот не се препорачува за мали големини на примероци, како и во случаи кога фреквенцијата на појава на карактеристика се стреми кон 0 или 1 (0% или 100%) и едноставно не е возможна за фреквенции од 0 и 1. Дополнително, приближувањето на нормалната дистрибуција, што се користи при пресметување на грешката, „не работи“ во случаи кога n p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Бидејќи новата променлива е нормално распределена, долните и горните граници на 95% интервалот на доверба за променлива φ ќе бидат φ-1,96 и φ+1,96лево">


Наместо 1,96 за мали примероци, се препорачува вредноста на t да се замени со N - 1 степени на слобода. Овој метод не дава негативни вредности и ви овозможува попрецизно да ги процените интервалите на доверба за фреквенциите од методот Wald. Покрај тоа, тој е опишан во многу домашни референтни книги за медицинска статистика, што, сепак, не доведе до негова широка употреба во медицинските истражувања. Пресметувањето интервали на доверба со помош на аголна трансформација не се препорачува за фреквенции кои се приближуваат до 0 или 1.
Овде обично завршува описот на методите за проценка на интервалите на доверба во повеќето книги за основите на статистиката за медицинските истражувачи, а овој проблем е типичен не само за домашната, туку и за странската литература. Двата методи се засноваат на централната гранична теорема, што подразбира голем примерок.
Земајќи ги предвид недостатоците во проценувањето на интервалите на доверба со помош на горенаведените методи, Клопер (Клопер) и Пирсон (Пирсон) во 1934 година предложиле метод за пресметување на таканаречениот точен интервал на доверба, земајќи ја предвид биномната распределба на проучуваната особина. Овој метод е достапен во многу онлајн калкулатори, меѓутоа, интервалите на доверба добиени на овој начин во повеќето случаи се премногу широки. Во исто време, овој метод се препорачува за употреба во случаи кога е потребна конзервативна проценка. Степенот на конзервативност на методот се зголемува како што се намалува големината на примерокот, особено за Н< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
Според многу статистичари, најоптималната проценка на интервалите на доверба за фреквенциите се врши со методот Вилсон, предложен уште во 1927 година, но практично не се користи во домашните биомедицински истражувања. Овој метод не само што овозможува да се проценат интервалите на доверба и за многу мали и за многу високи фреквенции, туку е применлив и за мал број на набљудувања. Општо земено, интервалот на доверба според формулата Вилсон ја има формата од
 |
 |
каде што ја зема вредноста 1,96 при пресметување на интервалот на доверба од 95%, N е бројот на набљудувања, а p е фреквенцијата на карактеристиката во примерокот. Овој метод е достапен во онлајн калкулаторите, така што неговата примена не е проблематична. и не препорачуваме користење на овој метод за n стр< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Покрај методот Вилсон, се верува дека и методот на Валд, коригиран со Agresti–Caull, обезбедува оптимална проценка на интервалот на доверба за фреквенциите. Agresti-Coulle корекцијата е замена во формулата Wald на фреквенцијата на појава на особина во примерокот (p) со p`, кога се пресметува која 2 се додава на броителот, а 4 се додава на именителот, т.е. , p` = (X + 2) / (N + 4), каде што X е бројот на учесници во студијата кои ја имаат карактеристиката што се испитува, а N е големината на примерокот. Оваа модификација дава резултати многу слични на оние од формулата Вилсон, освен кога стапката на настан се приближува до 0% или 100%, а примерокот е мал. Покрај горенаведените методи за пресметување на интервалите на доверба за фреквенциите, предложени се корекции за континуитет и за методот Wald и за методот Wilson за мали примероци, но студиите покажаа дека нивната употреба е несоодветна.
Размислете за примената на горенаведените методи за пресметување на интервали на доверба користејќи два примери. Во првиот случај, проучуваме голем примерок од 1.000 случајно избрани учесници во студијата, од кои 450 ја имаат карактеристиката што се испитува (тоа може да биде фактор на ризик, исход или која било друга карактеристика), што е фреквенција од 0,45 или 45%. Во вториот случај, студијата се спроведува со користење на мал примерок, да речеме, само 20 луѓе, а само 1 учесник во студијата (5%) ја има особина што се испитува. Интервалите на доверба за методот Wald, за методот Wald со Agresti-Coll корекција, за методот Wilson беа пресметани со помош на онлајн калкулатор развиен од Џеф Сауро (http://www./wald.htm). Доверливите интервали на Вилсон, корегирани со континуитет, беа пресметани со помош на калкулаторот обезбеден од Wassar Stats: Web Site for Statistical Computation (http://faculty.vassar.edu/lowry/prop1.html). Пресметките со помош на аголната трансформација на Фишер беа извршени „рачно“ со користење на критичната вредност на t за 19 и 999 степени на слобода, соодветно. Резултатите од пресметката се претставени во табелата за двата примери.
Интервали на доверба пресметани на шест различни начини за двата примери опишани во текстот
Метод за пресметување на интервал на доверба |
P=0,0500, или 5% | 95% CI за X=450, N=1000, P=0,4500 или 45% |
–0,0455–0,2541 | ||
Валда со корекција на Agresti-Coll | <,0001–0,2541 | |
Вилсон со корекција на континуитет | ||
„Точниот метод“ на Клопер-Пирсон | ||
Аголна трансформација | <0,0001–0,1967 |
Како што може да се види од табелата, за првиот пример, интервалот на доверба пресметан со „општо прифатениот“ Wald метод оди во негативниот регион, што не може да биде случај за фреквенциите. За жал, ваквите инциденти не се невообичаени во руската литература. Традиционалниот начин на претставување на податоците како фреквенција и нивната грешка делумно го маскира овој проблем. На пример, ако фреквенцијата на појава на особина (во проценти) е претставена како 2,1 ± 1,4, тогаш тоа не е „иритирачко“ како 2,1% (95% CI: -0,7; 4,9), иако и значи истото. Валдовиот метод со корекција на Agresti-Coll и пресметката со помош на аголната трансформација даваат долна граница која се стреми кон нула. Вилсоновиот метод со корекција на континуитет и „точниот метод“ даваат пошироки интервали на доверба од методот Вилсон. За вториот пример, сите методи даваат приближно исти интервали на доверба (разликите се појавуваат само во илјадити), што не е изненадувачки, бидејќи фреквенцијата на настанот во овој пример не се разликува многу од 50%, а големината на примерокот е прилично голема .
За читателите кои се заинтересирани за овој проблем, можеме да ги препорачаме делата на Р. Од домашните прирачници се препорачува книгата и во која покрај деталниот опис на теоријата се претставени методите на Валд и Вилсон, како и метод за пресметување на интервали на доверба, земајќи ја предвид биномната фреквентна дистрибуција. Покрај бесплатните онлајн калкулатори (http://www./wald.htm и http://faculty.vassar.edu/lowry/prop1.html), интервалите на доверба за фреквенциите (и не само!) може да се пресметаат со помош на Програма на ЦИА ( Анализа на интервали на доверба), која може да се преземе од http://www. медицинско училиште. сотон. ак. uk/cia/.
Следната статија ќе ги разгледа униваријантните начини за споредување на квалитативните податоци.
Библиографија
Банерџи А.Медицинска статистика на едноставен јазик: воведен курс / А. Банержи. - М.: Практична медицина, 2007. - 287 стр. Медицинска статистика / . - М.: Агенција за медицински информации, 2007. - 475 стр. Гланц С.Медико-биолошка статистика / S. Glants. - М.: Пракса, 1998 година. Типови на податоци, проверка на дистрибуција и описна статистика / // Човечка екологија - 2008. - бр. 1. - стр. 52–58. Жижин К.С.. Медицинска статистика: учебник / . - Ростов n / D: Феникс, 2007. - 160 стр. Применета медицинска статистика / , . - Санкт Петербург. : Фолио, 2003. - 428 стр. Лакин Г. Ф. Биометрика / . - М. : Високо училиште, 1990. - 350 стр. Медицина В.А. Математичка статистика во медицината / , . - М.: Финансии и статистика, 2007. - 798 стр. Математичка статистика во клиничките истражувања / , . - М.: ГЕОТАР-МЕД, 2001. - 256 стр. Јункеров В. И. Медицинско-статистичка обработка на податоци од медицински истражувања /,. - Санкт Петербург. : VmedA, 2002. - 266 стр. Агрести А.Приближното е подобро од точното за интервална проценка на биномните пропорции / А. Агрести, Б. Коул // Американски статистичар. - 1998. - N 52. - S. 119-126. Алтман Д.Статистика со доверба // D. Altman, D. Machin, T. Bryant, M. J. Gardner. - Лондон: BMJ Books, 2000. - 240 стр. Браун Л.Д.Проценка на интервал за биномна пропорција / L. D. Brown, T. T. Cai, A. Dasgupta // Статистичка наука. - 2001. - N 2. - P. 101-133. Клопер Ц.Ј.Употребата на доверливост или фидуцијални граници илустрирани во случајот со биномот / C. J. Clopper, E. S. Pearson // Biometrika. - 1934. - N 26. - P. 404-413. Гарсија-Перез М.А. За интервалот на доверба за биномниот параметар / M. A. Garcia-Perez // Квалитет и квантитет. - 2005. - N 39. - P. 467-481. Мотулски Х.Интуитивна биостатистика // H. Motulsky. - Oxford: Oxford University Press, 1995. - 386 стр. Њукомб Р.Г.Двострани интервали на доверба за единствената пропорција: споредба на седум методи / R. G. Newcombe // Статистика во медицината. - 1998. - N. 17. - P. 857–872. Сауро Ј.Проценка на стапките на завршување од мали примероци користејќи интервали на биномна доверба: споредби и препораки / Ј. Сауро, Ј. Р. Луис // Годишен состанок на здружението за човечки фактори и ергономија. - Орландо, Флорида, 2005 година. Валд А.Ограничувања на доверба за функциите на континуирана дистрибуција // А. Валд, Ј. Волфовиц // Анали на математичка статистика. - 1939. - N 10. - P. 105–118. Вилсон Е.Б. Веројатно заклучување, закон за сукцесија и статистичко заклучување / Е. Б. Вилсон // Весник на Американската статистичка асоцијација. - 1927. - N 22. - P. 209-212.ИНТЕРВАЛИ НА ДОВЕРБА ЗА ПРОПОРЦИИ
А. М.Грибовски
Национален институт за јавно здравје, Осло, Норвешка
Во написот се претставени неколку методи за пресметување на доверливи интервали за биномни пропорции, имено, методите Wald, Wilson, arcsine, Agresti-Coull и точните Clopper-Pearson. Трудот дава само општ вовед во проблемот на проценка на интервалот на доверливост на биномна пропорција и неговата цел е не само да ги стимулира читателите да користат интервали на доверба при презентирање на резултатите од сопствените емпириски истражувања, туку и да ги поттикне да се консултираат со статистички книги пред анализа на сопствени податоци и подготовка на ракописи.
клучни зборови: интервал на доверба, пропорција
Контакт информации:
– Виш советник, Национален институт за јавно здравје, Осло, Норвешка
Секој примерок дава само приближна идеја за општата популација, а сите статистички карактеристики на примерокот (средна вредност, режим, варијанса...) се некаква апроксимација или да речеме проценка на општите параметри, кои во повеќето случаи не можат да се пресметаат поради непристапноста на општата популација (Слика 20) .
Слика 20. Грешка при земање мостри
Но, можете да го одредите интервалот во кој, со одреден степен на веројатност, лежи вистинската (општата) вредност на статистичката карактеристика. Овој интервал се нарекува г интервал на доверба (CI).
Значи општиот просек со веројатност од 95% лежи внатре
од до, (20)
каде т - табеларна вредност на Студентскиот критериум за α =0,05 и ѓ= n-1
Може да се најде и 99% CI, во овој случај т избран за α =0,01.
Кое е практичното значење на интервалот на доверба?
Широк интервал на доверба покажува дека средната вредност на примерокот не ја одразува точно просечната популација. Ова обично се должи на недоволната големина на примерокот, или на нејзината хетерогеност, т.е. голема дисперзија. И двете даваат голема грешка во средната вредност и, соодветно, поширок CI. И ова е причината да се вратиме во фазата на планирање на истражувањето.
Горните и долните граници на CI проценуваат дали резултатите ќе бидат клинички значајни
Дозволете ни да се задржиме подетално на прашањето за статистичкото и клиничкото значење на резултатите од проучувањето на групните својства. Потсетиме дека задачата на статистиката е да открие барем некои разлики во општите популации, врз основа на податоците од примерокот. Задачата на клиничарот е да најде такви (не какви било) разлики што ќе помогнат во дијагнозата или лекувањето. И не секогаш статистичките заклучоци се основа за клинички заклучоци. Така, статистички значајното намалување на хемоглобинот за 3 g/l не е причина за загриженост. И, обратно, ако некој проблем во човечкото тело нема масовен карактер на ниво на целата популација, тоа не е причина да не се занимаваме со овој проблем.
|
Оваа позиција ќе ја разгледаме во пример. Истражувачите се прашуваа дали момчињата кои имаат некаква заразна болест заостануваат по растот зад своите врсници. За таа цел е спроведена селективна студија во која учествувале 10 момчиња кои ја имале оваа болест. Резултатите се прикажани во табела 23. Табела 23. Статистички резултати
Од овие пресметки произлегува дека селективната просечна висина на 10-годишните момчиња кои имале некаква заразна болест е блиску до нормалата (132,5 см). Сепак, долната граница на интервалот на доверба (126,6 см) укажува на тоа дека постои 95% веројатност вистинската просечна висина на овие деца да одговара на концептот на „низок раст“, т.е. овие деца се закржлавени. Во овој пример, резултатите од пресметките на интервалот на доверба се клинички значајни. |
|||||||||||||||||||
Цел– да ги научи учениците алгоритми за пресметување интервали на доверливост на статистичките параметри.
При статистичката обработка на податоците, пресметаната аритметичка средина, коефициентот на варијација, коефициентот на корелација, критериумите за разлика и другите точки статистики треба да добијат квантитативни граници на доверба, кои укажуваат на можни флуктуации на индикаторот нагоре и надолу во рамките на интервалот на доверба.
Пример 3.1
.
Распределбата на калциумот во крвниот серум на мајмуните, како што е претходно утврдено, се карактеризира со следните селективни индикатори: = 11,94 mg%;  = 0,127 mg%; n= 100. Потребно е да се одреди интервалот на доверба за општиот просек (
= 0,127 mg%; n= 100. Потребно е да се одреди интервалот на доверба за општиот просек (  ) со веројатност за доверба П
= 0,95.
) со веројатност за доверба П
= 0,95.
Општиот просек е со одредена веројатност во интервалот:
 , каде
, каде  – примерок аритметичка средина; т- студентски критериум;
– примерок аритметичка средина; т- студентски критериум;  е грешката на аритметичката средина.
е грешката на аритметичката средина.
Според табелата „Вредности на студентскиот критериум“ ја наоѓаме вредноста
 со ниво на доверба од 0,95 и број на степени на слобода к\u003d 100-1 \u003d 99. Тоа е еднакво на 1,982. Заедно со вредностите на аритметичката средина и статистичката грешка, ја заменуваме во формулата:
со ниво на доверба од 0,95 и број на степени на слобода к\u003d 100-1 \u003d 99. Тоа е еднакво на 1,982. Заедно со вредностите на аритметичката средина и статистичката грешка, ја заменуваме во формулата:
или 11,69  12,19
12,19
Така, со веројатност од 95%, може да се тврди дека општиот просек на оваа нормална распределба е помеѓу 11,69 и 12,19 mg%.
Пример 3.2
. Определете ги границите на 95% интервал на доверба за општата варијанса (  ) дистрибуција на калциум во крвта на мајмуните, ако се знае дека
) дистрибуција на калциум во крвта на мајмуните, ако се знае дека  = 1,60, со n
= 100.
= 1,60, со n
= 100.
За да го решите проблемот, можете да ја користите следнава формула:
Каде  е статистичката грешка на варијансата.
е статистичката грешка на варијансата.
Најдете ја грешката на варијансата на примерокот користејќи ја формулата:  . Тоа е еднакво на 0,11. Значење т- критериум со веројатност на доверба од 0,95 и број на степени на слобода к= 100–1 = 99 е познато од претходниот пример.
. Тоа е еднакво на 0,11. Значење т- критериум со веројатност на доверба од 0,95 и број на степени на слобода к= 100–1 = 99 е познато од претходниот пример.
Ајде да ја искористиме формулата и да добиеме:
или 1,38  1,82
1,82
Попрецизен интервал на доверба за општата варијанса може да се конструира со користење  (хи-квадрат) - Пирсоновиот тест. Критичните точки за овој критериум се дадени во посебна табела. При користење на критериумот
(хи-квадрат) - Пирсоновиот тест. Критичните точки за овој критериум се дадени во посебна табела. При користење на критериумот  се користи двострано ниво на значајност за да се конструира интервал на доверба. За долната граница, нивото на значајност се пресметува со формулата
се користи двострано ниво на значајност за да се конструира интервал на доверба. За долната граница, нивото на значајност се пресметува со формулата  , за горниот дел
, за горниот дел  . На пример, за ниво на доверба
. На пример, за ниво на доверба  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Според тоа, според табелата на распределба на критичните вредности
= 0,990. Според тоа, според табелата на распределба на критичните вредности  , со пресметаните нивоа на доверба и бројот на степени на слобода к= 100 – 1= 99, најдете ги вредностите
, со пресметаните нивоа на доверба и бројот на степени на слобода к= 100 – 1= 99, најдете ги вредностите  и
и  . Добиваме
. Добиваме  е еднакво на 135,80 и
е еднакво на 135,80 и  изнесува 70,06.
изнесува 70,06.
Да се најдат границите на доверба на општата варијанса користејќи  ги користиме формулите: за долната граница
ги користиме формулите: за долната граница  , за горната граница
, за горната граница  . Заменете ги податоците за задачата за пронајдените вредности
. Заменете ги податоците за задачата за пронајдените вредности  во формули:
во формули:  =
1,17;
=
1,17; = 2,26. Така, со ниво на доверба П= 0,99 или 99% општата варијанса ќе лежи во опсегот од 1,17 до 2,26 mg% вклучително.
= 2,26. Така, со ниво на доверба П= 0,99 или 99% општата варијанса ќе лежи во опсегот од 1,17 до 2,26 mg% вклучително.
Пример 3.3 . Меѓу 1000 семки пченица од парцелата што пристигнаа во лифтот, пронајдени се 120 семиња заразени со ергот. Неопходно е да се утврдат веројатните граници на вкупниот дел на заразени семиња во дадена серија пченица.
Ограничувањата на довербата за општата акција за сите нејзини можни вредности треба да се утврдат со формулата:
 ,
,
Каде n е бројот на набљудувања; ме апсолутен број на една од групите; те нормализираното отстапување.
Примерокот за фракција на заразени семиња е еднаков на  или 12%. Со ниво на самодоверба Р= 95% нормализирано отстапување ( т-Студентски критериум за к
=
или 12%. Со ниво на самодоверба Р= 95% нормализирано отстапување ( т-Студентски критериум за к
=
 )т
= 1,960.
)т
= 1,960.
Достапните податоци ги заменуваме во формулата:
Оттука, границите на интервалот на доверба се  = 0,122-0,041 = 0,081, или 8,1%;
= 0,122-0,041 = 0,081, или 8,1%;  = 0,122 + 0,041 = 0,163, или 16,3%.
= 0,122 + 0,041 = 0,163, или 16,3%.
Така, со ниво на доверба од 95%, може да се каже дека вкупниот процент на заразени семиња е помеѓу 8,1 и 16,3%.
Пример 3.4 . Коефициентот на варијација, кој ја карактеризира варијацијата на калциум (mg%) во крвниот серум на мајмуните, беше еднаков на 10,6%. Големина на примерокот n= 100. Потребно е да се одредат границите на 95% интервал на доверба за општиот параметар CV.
Граници на доверба за општиот коефициент на варијација CV се одредуваат со следните формули:
 и
и  , каде К
средна вредност пресметана со формулата
, каде К
средна вредност пресметана со формулата  .
.
Знаејќи го тоа со ниво на самодоверба Р= 95% нормализирано отстапување (студентски т-тест за к
=
 )т
= 1,960, однапред пресметајте ја вредноста ДО:
)т
= 1,960, однапред пресметајте ја вредноста ДО:
 .
.
 или 9,3%
или 9,3%
 или 12,3%
или 12,3%
Така, општиот коефициент на варијација со веројатност на доверба од 95% се наоѓа во опсег од 9,3 до 12,3%. Со повторени примероци, коефициентот на варијација нема да надмине 12,3% и нема да падне под 9,3% во 95 случаи од 100.
Прашања за самоконтрола:

Задачи за самостојно решение.
1. Просечниот процент на маснотии во млекото за лактација на кравите на холмогорските крстови беше како што следува: 3,4; 3.6; 3.2; 3.1; 2,9; 3,7; 3.2; 3.6; 4.0; 3.4; 4.1; 3,8; 3.4; 4.0; 3.3; 3,7; 3,5; 3.6; 3.4; 3.8. Поставете интервали на доверба за вкупната средна вредност на ниво на доверба од 95% (20 поени).
2. На 400 растенија хибридна 'рж првите цветови се појавувале во просек 70,5 дена по сеидбата. Стандардната девијација беше 6,9 дена. Одредете ја грешката на средната вредност и интервалите на доверба за популациската средина и варијанса на ниво на значајност В= 0,05 и В= 0,01 (25 поени).
3. При проучување на должината на листовите на 502 примероци градинарски јагоди, добиени се следните податоци:
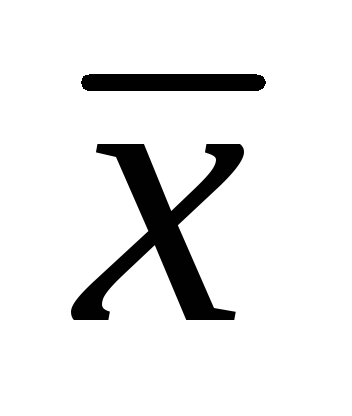 = 7,86 см; σ = 1,32 cm,
= 7,86 см; σ = 1,32 cm,  \u003d ± 0,06 cm Определете ги интервалите на доверба за аритметичката средина на популацијата со нивоа на значајност од 0,01; 0,02; 0,05. (25 поени).
\u003d ± 0,06 cm Определете ги интервалите на доверба за аритметичката средина на популацијата со нивоа на значајност од 0,01; 0,02; 0,05. (25 поени).
4. При испитување на 150 возрасни мажи просечната висина била 167 см, а σ \u003d 6 cm Кои се границите на општиот просек и општата варијанса со веројатност на доверба од 0,99 и 0,95? (25 поени).
5. Распределбата на калциумот во крвниот серум на мајмуните се карактеризира со следните селективни индикатори:
 = 11,94 mg%, σ
= 1,27, n
= 100. Нацртајте интервал на доверба од 95% за популациската средина на оваа дистрибуција. Пресметај го коефициентот на варијација (25 поени).
= 11,94 mg%, σ
= 1,27, n
= 100. Нацртајте интервал на доверба од 95% за популациската средина на оваа дистрибуција. Пресметај го коефициентот на варијација (25 поени).
6. Проучена е вкупната содржина на азот во крвната плазма на албино стаорци на возраст од 37 и 180 дена. Резултатите се изразени во грамови на 100 cm 3 плазма. На возраст од 37 дена, 9 стаорци имале: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. На возраст од 180 дена, 8 стаорци имале: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1.13; 1.12. Поставете интервали на доверба за разликата со ниво на доверба од 0,95 (50 поени).
7. Определете ги границите на интервалот на доверба од 95% за општата варијанса на дистрибуцијата на калциум (mg%) во крвниот серум на мајмуните, ако за оваа дистрибуција големината на примерокот е n = 100, статистичката грешка на варијансата на примерокот с σ 2 = 1,60 (40 поени).
8. Определете ги границите на интервалот на доверба од 95% за општата варијанса на распоредот на 40 шипки пченица по должината (σ 2 = 40,87 mm 2). (25 поени).
9. Пушењето се смета за главен фактор кој предиспонира за опструктивна белодробна болест. Пасивното пушење не се смета за таков фактор. Научниците се сомневаа во безбедноста на пасивното пушење и ги испитуваа дишните патишта кај непушачите, пасивните и активните пушачи. За да ја карактеризираме состојбата на респираторниот тракт, зедовме еден од индикаторите за функцијата на надворешното дишење - максималната волуметриска брзина на средината на издишувањето. Намалувањето на овој индикатор е знак за нарушена проодност на дишните патишта. Податоците од анкетата се прикажани во табелата.
|
Број на испитани |
Максимална стапка на средно-експираторен проток, l/s |
||
|
Стандардна девијација |
|||
|
Непушачи |
|||
|
работа во простор за непушачи | |||
|
работа во просторија исполнета со чад | |||
|
пушачи |
|||
|
пушење мал број цигари | |||
|
просечен број пушачи на цигари | |||
|
пушење голем број цигари | |||
Од табелата пронајдете ги интервалите на доверба од 95% за општата средина и општата варијанса за секоја од групите. Кои се разликите помеѓу групите? Презентирајте ги резултатите графички (25 поени).
10. Определете ги границите на интервалите на доверба од 95% и 99% за општата варијанса на бројот на прасиња во 64 родови, доколку статистичката грешка на варијансата на примерокот с σ 2 = 8,25 (30 поени).
11. Познато е дека просечната тежина на зајаците е 2,1 кг. Определете ги границите на интервалите на доверба од 95% и 99% за општата средина и варијансата кога n= 30, σ = 0,56 кг (25 поени).
12. Во 100 класје била измерена содржината на зрното во увото ( X), должина на шип ( Y) и масата на жито во увото ( З). Најдете интервали на доверба за општата средина и варијанса за П 1
= 0,95, П 2
= 0,99, П 3
= 0,999 ако
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 поени).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 поени).
13. Во случајно избрани 100 класови зимска пченица се брои бројот на шипки. Комплетот примерок се карактеризираше со следниве индикатори:
 = 15 шипки и σ = 2,28 парчиња. Одреди ја точноста со која се добива просечниот резултат (
= 15 шипки и σ = 2,28 парчиња. Одреди ја точноста со која се добива просечниот резултат (  ) и нацртајте го интервалот на доверба за вкупната средна вредност и варијанса на нивоа на значајност од 95% и 99% (30 поени).
) и нацртајте го интервалот на доверба за вкупната средна вредност и варијанса на нивоа на значајност од 95% и 99% (30 поени).
14. Бројот на ребра на лушпите на фосилниот мекотел Ортамбонити калиграма:
Познато е дека n = 19, σ = 4,25. Определете ги границите на интервалот на доверба за општата средина и општата варијанса на ниво на значајност В = 0,01 (25 поени).
15. За да се одредат приносите на млеко на комерцијална млечна фарма, дневно се одредуваше продуктивноста на 15 крави. Според податоците за годината, секоја крава во просек ја давала следната количина млеко дневно (л): 22; деветнаесет; 25; дваесет; 27; 17; триесет; 21; осумнаесет; 24; 26; 23; 25; дваесет; 24. Нацртај интервали на доверба за општата варијанса и аритметичката средина. Можеме ли да очекуваме просечниот годишен принос на млеко по крава да биде 10.000 литри? (50 поени).
16. За да се одреди просечниот принос на пченица за фармата, се изврши косење на парцели за примерок од 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 и 2 ha. Приносот (c/ha) од парцелите беше 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 соодветно. Зацртај интервали на доверба за општата варијанса и аритметичката средина. Дали може да се очекува дека просечниот принос за земјоделското претпријатие ќе биде 42 c/ha? (50 поени).