Konfidensintervall for å estimere gjennomsnittet (spredning er kjent) i MS EXCEL. Konfidensintervall
Ethvert utvalg gir bare en omtrentlig idé om den generelle populasjonen, og alle statistiske kjennetegn (gjennomsnitt, modus, varians ...) er en tilnærming eller for eksempel et estimat av de generelle parameterne, som i de fleste tilfeller ikke kan beregnes pga. utilgjengelighet for befolkningen generelt (Figur 20) .
Figur 20. Prøvetakingsfeil
Men du kan spesifisere intervallet der, med en viss grad av sannsynlighet, ligger den sanne (generelle) verdien av den statistiske egenskapen. Dette intervallet kalles d konfidensintervall (CI).
Så det generelle gjennomsnittet med en sannsynlighet på 95% ligger innenfor
fra til, (20)
Hvor t - tabellverdi av Students kriterium for α =0,05 og f= n-1
Kan bli funnet og 99% CI, i dette tilfellet t valgt for α =0,01.
Hva er den praktiske betydningen av et konfidensintervall?
Et bredt konfidensintervall indikerer at utvalgets gjennomsnitt ikke reflekterer populasjonsgjennomsnittet nøyaktig. Dette skyldes vanligvis en utilstrekkelig prøvestørrelse, eller dens heterogenitet, dvs. stor spredning. Begge gir en stor feil i gjennomsnittet og følgelig en bredere CI. Og dette er grunnen til å gå tilbake til forskningsplanleggingsstadiet.
Øvre og nedre CI-grenser vurderer om resultatene vil være klinisk signifikante
La oss dvele mer detaljert på spørsmålet om den statistiske og kliniske betydningen av resultatene fra studiet av gruppeegenskaper. Husk at oppgaven med statistikk er å oppdage minst noen forskjeller i generelle populasjoner, basert på utvalgsdata. Det er klinikerens oppgave å finne slike (ikke noen) forskjeller som vil hjelpe diagnostisering eller behandling. Og ikke alltid statistiske konklusjoner er grunnlaget for kliniske konklusjoner. En statistisk signifikant reduksjon i hemoglobin med 3 g/l er derfor ikke grunn til bekymring. Og omvendt, hvis et problem i menneskekroppen ikke har en massekarakter på nivået av hele befolkningen, er dette ikke en grunn til ikke å håndtere dette problemet.
|
Vi vil vurdere denne stillingen i eksempel. Forskerne lurte på om gutter som hadde en eller annen form for infeksjonssykdom lå bak jevnaldrende i veksten. For dette formålet ble det utført en selektiv studie der 10 gutter som hadde denne sykdommen deltok. Resultatene er presentert i tabell 23. Tabell 23. Statistiske resultater
Av disse beregningene følger det at den selektive gjennomsnittshøyden til 10 år gamle gutter som har hatt en eller annen form for infeksjonssykdom er nær normalen (132,5 cm). Den nedre grensen for konfidensintervallet (126,6 cm) indikerer imidlertid at det er 95 % sannsynlighet for at den sanne gjennomsnittshøyden til disse barna tilsvarer begrepet «kort statur», dvs. disse barna er forkrøplet. I dette eksemplet er resultatene av konfidensintervallberegningene klinisk signifikante. |
|||||||||||||||||||
I de foregående underavsnittene vurderte vi spørsmålet om å estimere den ukjente parameteren EN ett tall. En slik vurdering kalles «poeng». I en rekke oppgaver kreves det ikke bare å finne for parameteren EN passende numerisk verdi, men også vurdere nøyaktigheten og påliteligheten. Det kreves å vite hvilke feil parametererstatningen kan føre til EN sitt punktestimat EN og med hvilken grad av sikkerhet kan vi forvente at disse feilene ikke vil gå utover kjente grenser?
Problemer av denne typen er spesielt relevante for et lite antall observasjoner, når punktanslaget og i er stort sett tilfeldig og en omtrentlig erstatning av a med a kan føre til alvorlige feil.
For å gi en ide om nøyaktigheten og påliteligheten til estimatet EN,
i matematisk statistikk brukes såkalte konfidensintervaller og konfidenssannsynligheter.
La for parameteren EN utledet fra erfaring objektivt estimat EN. Vi ønsker å anslå mulig feil i dette tilfellet. La oss tilordne en tilstrekkelig stor sannsynlighet p (for eksempel p = 0,9, 0,95 eller 0,99) slik at en hendelse med sannsynlighet p kan anses som praktisk talt sikker, og finne en verdi på s som
Deretter rekkevidden av praktisk mulige verdier for feilen som oppstår ved utskifting EN på EN, vil være ± s; store absolutte feil vises bare med liten sannsynlighet a = 1 - p. La oss omskrive (14.3.1) som:
Likhet (14.3.2) betyr at med sannsynlighet p den ukjente verdien av parameteren EN faller innenfor intervallet
I dette tilfellet bør en omstendighet bemerkes. Tidligere har vi gjentatte ganger vurdert sannsynligheten for at en tilfeldig variabel faller inn i et gitt ikke-tilfeldig intervall. Her er situasjonen annerledes: EN ikke tilfeldig, men tilfeldig intervall / r. Tilfeldig dens posisjon på x-aksen, bestemt av sentrum EN; generelt er lengden på intervallet 2s også tilfeldig, siden verdien av s beregnes som regel fra eksperimentelle data. Derfor, i dette tilfellet, ville det være bedre å tolke verdien av p ikke som sannsynligheten for å "treffe" punktet EN inn i intervallet / p, men som sannsynligheten for at et tilfeldig intervall / p vil dekke punktet EN(Fig. 14.3.1).

Ris. 14.3.1
Sannsynligheten p kalles selvtillitsnivå, og intervallet / p - konfidensintervall. Intervallgrenser hvis. a x \u003d a- s og a 2 = a + og blir kalt tillitsgrenser.
La oss gi enda en tolkning til konseptet med et konfidensintervall: det kan betraktes som et intervall av parameterverdier EN, kompatibel med eksperimentelle data og ikke motsier dem. Faktisk, hvis vi er enige om å vurdere en hendelse med en sannsynlighet a = 1-p praktisk talt umulig, vil de verdiene til parameteren a som a - a> s må gjenkjennes som motstridende eksperimentelle data, og de som |a - EN a t na 2.
La for parameteren EN det er et objektivt estimat EN. Hvis vi kjente loven om fordeling av mengden EN, ville problemet med å finne konfidensintervallet være ganske enkelt: det ville være nok å finne en verdi på s som
![]()
Vanskeligheten ligger i det faktum at fordelingen lov av estimatet EN avhenger av loven om fordeling av mengde X og følgelig på dets ukjente parametere (spesielt på selve parameteren EN).
For å omgå denne vanskeligheten kan man bruke følgende omtrentlige triks: Bytt ut de ukjente parameterne i uttrykket for s med deres punktanslag. Med et relativt stort antall eksperimenter P(ca. 20 ... 30) denne teknikken gir vanligvis tilfredsstillende resultater når det gjelder nøyaktighet.
Som et eksempel kan du vurdere problemet med konfidensintervallet for den matematiske forventningen.
La produsert P x, hvis egenskaper er den matematiske forventningen T og varians D- ukjent. For disse parameterne ble følgende estimater oppnådd:

Det kreves å bygge et konfidensintervall / р, tilsvarende konfidenssannsynligheten р, for den matematiske forventningen T mengder x.
For å løse dette problemet bruker vi det faktum at mengden T er summen P uavhengige identisk fordelte stokastiske variabler X h og i henhold til sentralgrensesetningen for tilstrekkelig stor P distribusjonsloven er nær normalen. I praksis, selv med et relativt lite antall ledd (i størrelsesorden 10 ... 20), kan fordelingsloven for summen anses tilnærmet normal. Vi vil anta at verdien T fordelt etter normalloven. Egenskapene til denne loven - den matematiske forventningen og variansen - er henholdsvis like T Og
(se kapittel 13 underpunkt 13.3). La oss anta at verdien D vi vet og finner en verdi Ep som
Ved å bruke formel (6.3.5) i kapittel 6 uttrykker vi sannsynligheten på venstre side av (14.3.5) i form av normalfordelingsfunksjonen
hvor er standardavviket til estimatet T.
Fra ligningen

finn Sp-verdien: 
der arg Ф* (x) er den inverse funksjonen til Ф* (X), de. en slik verdi av argumentet som normalfordelingsfunksjonen er lik for X.
Spredning D, som verdien uttrykkes gjennom EN 1P, vi vet ikke nøyaktig; som omtrentlig verdi kan du bruke anslaget D(14.3.4) og sett omtrent:

Dermed er problemet med å konstruere et konfidensintervall omtrent løst, som er lik:
hvor gp er definert av formel (14.3.7).
For å unngå omvendt interpolasjon i tabellene til funksjonen Ф * (l) ved beregning av s p, er det praktisk å kompilere en spesiell tabell (tabell 14.3.1), som viser verdiene til mengden
avhengig av r. Verdien (p bestemmer for normalloven antall standardavvik som må settes til side til høyre og venstre for spredningssenteret slik at sannsynligheten for å falle inn i det resulterende området er lik p.
Gjennom verdien på 7 p uttrykkes konfidensintervallet som:

Tabell 14.3.1
Eksempel 1. Det ble utført 20 forsøk på verdien x; resultatene er vist i tabell. 14.3.2.
Tabell 14.3.2
Det kreves å finne et estimat for den matematiske forventningen til mengden X og konstruer et konfidensintervall som tilsvarer et konfidensnivå p = 0,8.
Løsning. Vi har:

Ved å velge for origo n: = 10, i henhold til den tredje formelen (14.2.14) finner vi det objektive estimatet D :

I følge tabellen 14.3.1 finner vi ![]()
![]()
Konfidensgrenser:

Konfidensintervall:
![]()
Parameterverdier T, som ligger i dette intervallet er kompatible med de eksperimentelle dataene gitt i tabellen. 14.3.2.
På lignende måte kan et konfidensintervall konstrueres for variansen.
La produsert P uavhengige eksperimenter på en tilfeldig variabel X med ukjente parametere fra og A, og for variansen D det objektive estimatet oppnås:


Det kreves tilnærmet å bygge et konfidensintervall for variansen.
Fra formel (14.3.11) kan man se at verdien D representerer
beløp P tilfeldige variabler av formen. Disse verdiene er ikke det
uavhengig, siden noen av dem inkluderer mengden T, avhengig av alle andre. Det kan imidlertid vises at som P fordelingsloven for summen deres er også nær normalen. Nesten kl P= 20...30 kan det allerede anses som normalt.
La oss anta at det er slik, og finne egenskapene til denne loven: den matematiske forventningen og variansen. Siden poengsummen D- upartisk, altså M[D] = D.
Variansberegning D D er assosiert med relativt komplekse beregninger, så vi gir uttrykket uten avledning:
hvor c 4 - det fjerde sentrale øyeblikket av kvantumet x.
For å bruke dette uttrykket, må du erstatte verdiene av 4 og D(minst omtrentlig). I stedet for D du kan bruke evalueringen D. I prinsippet kan det fjerde sentrale øyeblikket også erstattes av dets estimat, for eksempel med en verdi av formen:

men en slik erstatning vil gi en ekstremt lav nøyaktighet, siden generelt, med et begrenset antall eksperimenter, bestemmes øyeblikk av høy orden med store feil. Men i praksis skjer det ofte at formen for distribusjonsloven av kvantumet X kjent på forhånd: bare parametrene er ukjente. Da kan vi prøve å uttrykke u4 mht D.
La oss ta det vanligste tilfellet, når verdien X fordelt etter normalloven. Deretter uttrykkes dets fjerde sentrale moment i form av variansen (se kapittel 6 underavsnitt 6.2);
![]()
og formel (14.3.12) gir  eller
eller
Erstatter i (14.3.14) det ukjente D hans vurdering D, vi får: hvorfra 
Momentet u 4 kan uttrykkes i form av D også i enkelte andre tilfeller, når fordelingen av kvantumet X er ikke normalt, men utseendet er kjent. For loven om enhetlig tetthet (se kapittel 5) har vi for eksempel: 
hvor (a, P) er intervallet som loven er gitt.
Derfor,
![]()
I henhold til formelen (14.3.12) får vi:  fra der vi finner ca
fra der vi finner ca
I tilfeller hvor formen på loven om fordeling av verdien av 26 er ukjent, anbefales det likevel ved estimering av verdien av en /) å bruke formelen (14.3.16), dersom det ikke er spesielle grunner til å tro at dette loven er veldig forskjellig fra den normale (har en merkbar positiv eller negativ kurtose) .
Hvis den omtrentlige verdien av a /) oppnås på en eller annen måte, så er det mulig å konstruere et konfidensintervall for variansen på samme måte som vi bygde det for den matematiske forventningen:
hvor verdien avhengig av gitt sannsynlighet p finnes i Tabell. 14.3.1.
Eksempel 2. Finn et konfidensintervall på omtrent 80 % for variansen til en tilfeldig variabel X under betingelsene i eksempel 1, hvis det er kjent at verdien X fordelt etter en lov nær normalen.
Løsning. Verdien forblir den samme som i tabellen. 14.3.1:
![]()
I henhold til formelen (14.3.16)

I henhold til formelen (14.3.18) finner vi konfidensintervallet:
![]()
Det tilsvarende verdiområdet for standardavviket: (0,21; 0,29).
14.4. Nøyaktige metoder for å konstruere konfidensintervaller for parametrene til en tilfeldig variabel fordelt i henhold til normalloven
I forrige underavsnitt vurderte vi omtrentlige metoder for å konstruere konfidensintervaller for gjennomsnittet og variansen. Her gir vi en ide om de nøyaktige metodene for å løse det samme problemet. Vi understreker at for å finne konfidensintervallene nøyaktig, er det helt nødvendig å vite på forhånd formen til loven om distribusjon av mengden x, mens dette ikke er nødvendig for å bruke omtrentlige metoder.
Ideen om nøyaktige metoder for å konstruere konfidensintervaller er som følger. Ethvert konfidensintervall er funnet fra en tilstand som uttrykker sannsynligheten for oppfyllelse av visse ulikheter, som inkluderer estimatet av interesse for oss EN. Karakterfordelingslov EN i det generelle tilfellet avhenger av de ukjente parametrene for mengden x. Noen ganger er det imidlertid mulig å overføre ulikheter fra en tilfeldig variabel EN til en annen funksjon av observerte verdier X p X 2, ..., X p. hvis distribusjonslov ikke avhenger av ukjente parametere, men bare avhenger av antall eksperimenter og formen til distribusjonsloven for mengden x. Tilfeldige variabler av denne typen spiller en stor rolle i matematisk statistikk; de har blitt studert mest detaljert for tilfellet med en normalfordeling av mengden x.
For eksempel er det bevist at under en normal fordeling av mengden X tilfeldig verdi

underlagt den såkalte Elevens distribusjonslov Med P- 1 frihetsgrad; tettheten av denne loven har formen

hvor G(x) er den kjente gammafunksjonen:

Det er også bevist at den tilfeldige variabelen
har "distribusjon % 2 " med P- 1 frihetsgrad (se kapittel 7), hvis tetthet er uttrykt med formelen

Uten å dvele ved utledningene av fordelinger (14.4.2) og (14.4.4), vil vi vise hvordan de kan brukes ved konstruksjon av konfidensintervaller for parameterne Ty D.
La produsert P uavhengige eksperimenter på en tilfeldig variabel x, fordelt etter normalloven med ukjente parametere TIO. For disse parameterne, estimater

Det er nødvendig å konstruere konfidensintervaller for begge parametere som tilsvarer konfidenssannsynligheten s.
La oss først konstruere et konfidensintervall for den matematiske forventningen. Det er naturlig å ta dette intervallet symmetrisk mht T; angi med s p halve lengden av intervallet. Verdien av sp må velges slik at tilstanden
La oss prøve å passere på venstre side av likhet (14.4.5) fra en tilfeldig variabel T til en tilfeldig variabel T, fordelt etter studentens lov. For å gjøre dette multipliserer vi begge deler av ulikheten |m-w?|
til en positiv verdi:  eller ved å bruke notasjonen (14.4.1),
eller ved å bruke notasjonen (14.4.1),

La oss finne et tall / p slik at verdien / p kan finnes fra betingelsen

Det kan sees av formel (14.4.2) at (1) er en jevn funksjon, så (14.4.8) gir 
Likhet (14.4.9) bestemmer verdien / p avhengig av p. Hvis du har en tabell med integrerte verdier til din disposisjon

da kan verdien / p bli funnet ved omvendt interpolasjon i tabellen. Imidlertid er det mer praktisk å kompilere en verditabell / p på forhånd. En slik tabell er gitt i vedlegget (tabell 5). Denne tabellen viser verdiene avhengig av konfidenssannsynligheten p og antall frihetsgrader P- 1. Etter å ha bestemt / p i henhold til tabellen. 5 og forutsatt 
finner vi halve bredden av konfidensintervallet / p og selve intervallet
Eksempel 1. 5 uavhengige eksperimenter ble utført på en tilfeldig variabel x, normalt fordelt med ukjente parametere T og om. Resultatene av forsøkene er gitt i tabell. 14.4.1.
Tabell 14.4.1
Finn et anslag T for den matematiske forventningen og konstruer et 90 % konfidensintervall / p for den (dvs. intervallet som tilsvarer konfidenssannsynligheten p \u003d 0,9).
Løsning. Vi har:
![]()
I henhold til tabell 5 i søknaden for P - 1 = 4 og p = 0,9 finner vi ![]() hvor
hvor 
Konfidensintervallet vil være
Eksempel 2. For betingelsene i eksempel 1 i underavsnitt 14.3, antar verdien X normalfordelt, finn det nøyaktige konfidensintervallet.
Løsning. I følge tabell 5 i søknaden finner vi kl P - 1 = 19ir =
0,8/p = 1,328; herfra 
Sammenligner vi med løsningen i eksempel 1 i underavsnitt 14.3 (e p \u003d 0,072), ser vi at avviket er veldig lite. Hvis vi holder nøyaktigheten til andre desimal, så er konfidensintervallene funnet med de nøyaktige og omtrentlige metodene de samme:
![]()
La oss gå videre til å konstruere et konfidensintervall for variansen. Vurder det objektive variansestimatet

og uttrykke den tilfeldige variabelen D gjennom verdien V(14.4.3) med fordeling x 2 (14.4.4):

Kjenne til distribusjonsloven for mengden V, det er mulig å finne intervallet / (1) det faller i med en gitt sannsynlighet p.
distribusjonsloven k n _ x (v) verdien av I 7 har formen vist i fig. 14.4.1.

Ris. 14.4.1
Spørsmålet oppstår: hvordan velge intervallet / p? Hvis distribusjonsloven av mengden V var symmetrisk (som en normallov eller Students fordeling), ville det være naturlig å ta intervallet /p symmetrisk med hensyn til den matematiske forventningen. I dette tilfellet loven k n _ x (v) asymmetrisk. La oss bli enige om å velge intervallet /p slik at sannsynlighetene for utgang av mengden V utenfor intervallet til høyre og venstre (skraverte områder i fig. 14.4.1) var like og like

For å konstruere et intervall / p med denne egenskapen bruker vi Table. 4 applikasjoner: den inneholder tall y) slik at
![]()
for mengden V, ha x 2 -fordeling med r frihetsgrader. I vårt tilfelle r = n- 1. Fiks r = n- 1 og finn i den tilsvarende linjen i tabellen. 4 to verdier x 2 - den ene tilsvarer en sannsynlighet den andre - sannsynligheter La oss betegne disse
verdier kl 2 Og xl? Intervallet har y 2, med venstre, og y ~ høyre ende.
Nå finner vi det nødvendige konfidensintervallet /| for variansen med grensene D, og D2, som dekker poenget D med sannsynlighet p: ![]()
La oss konstruere et slikt intervall / (, = (?> b A), som dekker punktet D hvis og bare hvis verdien V faller inn i intervallet / r. La oss vise at intervallet

tilfredsstiller denne betingelsen. Faktisk ulikhetene  tilsvarer ulikhetene
tilsvarer ulikhetene
![]()
og disse ulikhetene holder med sannsynlighet s. Dermed er konfidensintervallet for dispersjonen funnet og uttrykkes med formelen (14.4.13).
Eksempel 3. Finn konfidensintervallet for variansen under betingelsene i eksempel 2 i underavsnitt 14.3, hvis det er kjent at verdien X fordelt normalt.
Løsning. Vi har ![]() . I henhold til tabell 4 i søknaden
. I henhold til tabell 4 i søknaden
finner vi kl r = n - 1 = 19

I følge formelen (14.4.13) finner vi konfidensintervallet for dispersjonen ![]()
Tilsvarende intervall for standardavvik: (0,21; 0,32). Dette intervallet overskrider bare litt intervallet (0,21; 0,29) oppnådd i eksempel 2 i underseksjon 14.3 ved den omtrentlige metoden.
- Figur 14.3.1 tar for seg et konfidensintervall som er symmetrisk om a. Generelt, som vi vil se senere, er dette ikke nødvendig.
Mål– å lære elevene algoritmer for å beregne konfidensintervaller for statistiske parametere.
Under statistisk databehandling bør beregnet aritmetisk gjennomsnitt, variasjonskoeffisient, korrelasjonskoeffisient, differansekriterier og annen punktstatistikk motta kvantitative konfidensgrenser, som indikerer mulige fluktuasjoner av indikatoren opp og ned innenfor konfidensintervallet.
Eksempel 3.1
.
Fordelingen av kalsium i blodserumet til aper, som tidligere etablert, er preget av følgende selektive indikatorer: = 11,94 mg%;  = 0,127 mg%; n= 100. Det er nødvendig å bestemme konfidensintervallet for det generelle gjennomsnittet (
= 0,127 mg%; n= 100. Det er nødvendig å bestemme konfidensintervallet for det generelle gjennomsnittet (  ) med sikkerhet sannsynlighet P
= 0,95.
) med sikkerhet sannsynlighet P
= 0,95.
Det generelle gjennomsnittet er med en viss sannsynlighet i intervallet:
 , Hvor
, Hvor 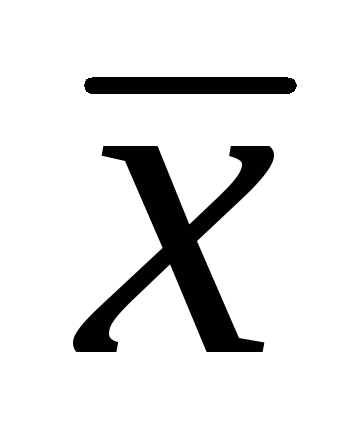 – prøve aritmetisk gjennomsnitt; t- Studentens kriterium;
– prøve aritmetisk gjennomsnitt; t- Studentens kriterium;  er feilen til det aritmetiske gjennomsnittet.
er feilen til det aritmetiske gjennomsnittet.
I henhold til tabellen "Verdier av studentens kriterium" finner vi verdien
 med et konfidensnivå på 0,95 og antall frihetsgrader k\u003d 100-1 \u003d 99. Det er lik 1,982. Sammen med verdiene til det aritmetiske gjennomsnittet og statistisk feil, erstatter vi det i formelen:
med et konfidensnivå på 0,95 og antall frihetsgrader k\u003d 100-1 \u003d 99. Det er lik 1,982. Sammen med verdiene til det aritmetiske gjennomsnittet og statistisk feil, erstatter vi det i formelen:
eller 11,69  12,19
12,19
Med en sannsynlighet på 95 % kan det således hevdes at det generelle gjennomsnittet av denne normalfordelingen er mellom 11,69 og 12,19 mg %.
Eksempel 3.2
. Bestem grensene for 95 % konfidensintervallet for den generelle variansen (  ) distribusjon av kalsium i blodet til aper, hvis det er kjent at
) distribusjon av kalsium i blodet til aper, hvis det er kjent at  = 1,60, med n
= 100.
= 1,60, med n
= 100.
For å løse problemet kan du bruke følgende formel:
Hvor  er den statistiske feilen til variansen.
er den statistiske feilen til variansen.
Finn prøvevariansfeilen ved å bruke formelen:  . Det er lik 0,11. Betydning t- kriterium med en konfidenssannsynlighet på 0,95 og antall frihetsgrader k= 100–1 = 99 er kjent fra forrige eksempel.
. Det er lik 0,11. Betydning t- kriterium med en konfidenssannsynlighet på 0,95 og antall frihetsgrader k= 100–1 = 99 er kjent fra forrige eksempel.
La oss bruke formelen og få:
eller 1,38  1,82
1,82
Et mer nøyaktig konfidensintervall for den generelle variansen kan konstrueres ved hjelp av  (chi-square) - Pearsons test. Kritiske poeng for dette kriteriet er gitt i en spesiell tabell. Ved bruk av kriteriet
(chi-square) - Pearsons test. Kritiske poeng for dette kriteriet er gitt i en spesiell tabell. Ved bruk av kriteriet  et tosidig signifikansnivå brukes til å konstruere et konfidensintervall. For den nedre grensen beregnes signifikansnivået av formelen
et tosidig signifikansnivå brukes til å konstruere et konfidensintervall. For den nedre grensen beregnes signifikansnivået av formelen  , for den øvre
, for den øvre  . For eksempel for et konfidensnivå
. For eksempel for et konfidensnivå  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Følgelig, i henhold til tabellen over distribusjon av kritiske verdier
= 0,990. Følgelig, i henhold til tabellen over distribusjon av kritiske verdier  , med de beregnede konfidensnivåene og antall frihetsgrader k= 100 – 1= 99, finn verdiene
, med de beregnede konfidensnivåene og antall frihetsgrader k= 100 – 1= 99, finn verdiene  Og
Og  . Vi får
. Vi får  tilsvarer 135,80, og
tilsvarer 135,80, og  tilsvarer 70,06.
tilsvarer 70,06.
For å finne konfidensgrensene for den generelle variansen ved å bruke  vi bruker formlene: for nedre grense
vi bruker formlene: for nedre grense 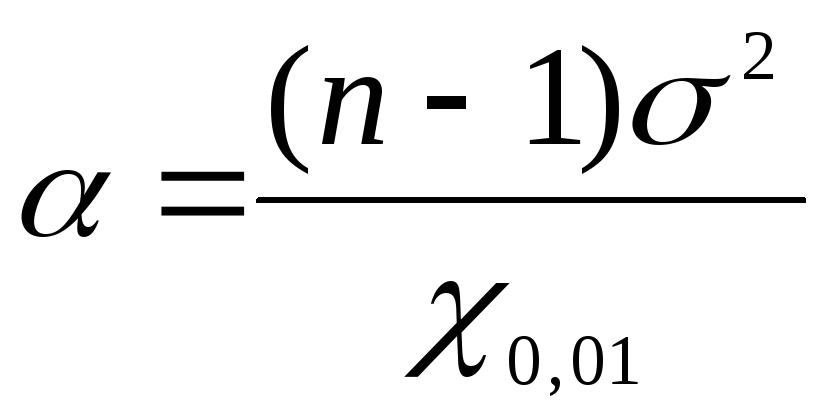 , for den øvre grensen
, for den øvre grensen  . Erstatt oppgavedataene med de funnet verdiene
. Erstatt oppgavedataene med de funnet verdiene  inn i formler:
inn i formler:  =
1,17;
=
1,17; = 2,26. Altså med et konfidensnivå P= 0,99 eller 99 % vil den generelle variansen ligge i området fra 1,17 til og med 2,26 mg %.
= 2,26. Altså med et konfidensnivå P= 0,99 eller 99 % vil den generelle variansen ligge i området fra 1,17 til og med 2,26 mg %.
Eksempel 3.3 . Blant de 1000 hvetefrøene fra partiet mottatt i heisen, ble det funnet 120 frø infisert med ergot. Det er nødvendig å bestemme de sannsynlige grensene for den totale andelen infiserte frø i et gitt parti hvete.
Konfidensgrenser for den generelle aksjen for alle mulige verdier bør bestemmes av formelen:
 ,
,
Hvor n er antall observasjoner; m er det absolutte tallet for en av gruppene; t er det normaliserte avviket.
Prøvefraksjonen av infiserte frø er lik  eller 12 %. Med et selvtillitsnivå R= 95 % normalisert avvik ( t-Elevens kriterium for k
=
eller 12 %. Med et selvtillitsnivå R= 95 % normalisert avvik ( t-Elevens kriterium for k
=
 )t
= 1,960.
)t
= 1,960.
Vi erstatter de tilgjengelige dataene i formelen:
Derfor er grensene for konfidensintervallet  = 0,122–0,041 = 0,081, eller 8,1 %;
= 0,122–0,041 = 0,081, eller 8,1 %;  = 0,122 + 0,041 = 0,163, eller 16,3 %.
= 0,122 + 0,041 = 0,163, eller 16,3 %.
Dermed kan man med et konfidensnivå på 95 % konstatere at den totale andelen infiserte frø er mellom 8,1 og 16,3 %.
Eksempel 3.4 . Variasjonskoeffisienten, som karakteriserer variasjonen av kalsium (mg%) i blodserumet til aper, var lik 10,6%. Prøvestørrelse n= 100. Det er nødvendig å bestemme grensene for 95 % konfidensintervallet for den generelle parameteren CV.
Konfidensgrenser for den generelle variasjonskoeffisienten CV bestemmes av følgende formler:
 Og
Og  , Hvor K
mellomverdi beregnet av formelen
, Hvor K
mellomverdi beregnet av formelen  .
.
Å vite det med et selvtillitsnivå R= 95 % normalisert avvik (Elevens t-test for k
=
 )t
= 1.960, forhåndsberegn verdien TIL:
)t
= 1.960, forhåndsberegn verdien TIL:
 .
.
 eller 9,3 %
eller 9,3 %
 eller 12,3 %
eller 12,3 %
Dermed ligger den generelle variasjonskoeffisienten med en konfidenssannsynlighet på 95 % i området fra 9,3 til 12,3 %. Ved gjentatte prøver vil variasjonskoeffisienten ikke overstige 12,3 % og ikke falle under 9,3 % i 95 tilfeller av 100.
Spørsmål for selvkontroll:

Oppgaver for selvstendig løsning.
1. Gjennomsnittlig prosentandel av fett i melk for laktasjon av kyr av Kholmogory-kryss var som følger: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Sett konfidensintervaller for det totale gjennomsnittet på et 95 % konfidensnivå (20 poeng).
2. På 400 planter av hybridrug kom de første blomstene i gjennomsnitt 70,5 dager etter såing. Standardavviket var 6,9 dager. Bestem feilen til gjennomsnittet og konfidensintervallene for populasjonsgjennomsnittet og variansen på et signifikansnivå W= 0,05 og W= 0,01 (25 poeng).
3. Når du studerer lengden på bladene til 502 eksemplarer av hagejordbær, ble følgende data oppnådd:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm Bestem konfidensintervallene for det aritmetiske gjennomsnittet av populasjonen med signifikansnivåer på 0,01; 0,02; 0,05. (25 poeng).
\u003d ± 0,06 cm Bestem konfidensintervallene for det aritmetiske gjennomsnittet av populasjonen med signifikansnivåer på 0,01; 0,02; 0,05. (25 poeng).
4. Ved undersøkelse av 150 voksne menn var gjennomsnittshøyden 167 cm, og σ \u003d 6 cm Hva er grensene for det generelle gjennomsnittet og den generelle variansen med en konfidenssannsynlighet på 0,99 og 0,95? (25 poeng).
5. Fordelingen av kalsium i blodserumet til aper er preget av følgende selektive indikatorer:
 = 11,94 mg%, σ
= 1,27, n
= 100. Plott et 95 % konfidensintervall for populasjonsgjennomsnittet for denne fordelingen. Regn ut variasjonskoeffisienten (25 poeng).
= 11,94 mg%, σ
= 1,27, n
= 100. Plott et 95 % konfidensintervall for populasjonsgjennomsnittet for denne fordelingen. Regn ut variasjonskoeffisienten (25 poeng).
6. Det totale nitrogeninnholdet i blodplasmaet til albinorotter i en alder av 37 og 180 dager ble studert. Resultatene er uttrykt i gram per 100 cm 3 plasma. I en alder av 37 dager hadde 9 rotter: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. I en alder av 180 dager hadde 8 rotter: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Sett konfidensintervaller for forskjellen med et konfidensnivå på 0,95 (50 poeng).
7. Bestem grensene for 95 % konfidensintervallet for den generelle variansen av fordelingen av kalsium (mg%) i blodserumet til aper, hvis for denne fordelingen prøvestørrelsen n = 100, den statistiske feilen for prøvevariansen s σ 2 = 1,60 (40 poeng).
8. Bestem grensene for 95 % konfidensintervallet for den generelle variansen av fordelingen av 40 hveteaks langs lengden (σ 2 = 40,87 mm 2). (25 poeng).
9. Røyking anses som hovedfaktoren som disponerer for obstruktiv lungesykdom. Passiv røyking regnes ikke som en slik faktor. Forskere stilte spørsmål ved sikkerheten ved passiv røyking og undersøkte luftveiene hos ikke-røykere, passive og aktive røykere. For å karakterisere tilstanden til luftveiene, tok vi en av indikatorene for funksjonen til ekstern respirasjon - den maksimale volumetriske hastigheten i midten av utåndingen. En reduksjon i denne indikatoren er et tegn på nedsatt luftveis åpenhet. Undersøkelsesdata er vist i tabellen.
|
Antall undersøkte |
Maksimal midekspiratorisk strømningshastighet, l/s |
||
|
Standardavvik |
|||
|
Ikke-røykere |
|||
|
arbeid i et røykfritt område | |||
|
arbeid i et røykfylt rom | |||
|
røykere |
|||
|
røyke et lite antall sigaretter | |||
|
gjennomsnittlig antall sigarettrøykere | |||
|
røyke et stort antall sigaretter | |||
Fra tabellen finner du 95 % konfidensintervaller for det generelle gjennomsnittet og den generelle variansen for hver av gruppene. Hva er forskjellene mellom gruppene? Presenter resultatene grafisk (25 poeng).
10. Bestem grensene for 95 % og 99 % konfidensintervaller for den generelle variasjonen av antall smågriser i 64 grisinger, hvis den statistiske feilen til prøvevariasjonen s σ 2 = 8,25 (30 poeng).
11. Det er kjent at gjennomsnittsvekten til kaniner er 2,1 kg. Bestem grensene for 95 % og 99 % konfidensintervaller for det generelle gjennomsnittet og variansen når n= 30, σ = 0,56 kg (25 poeng).
12. I 100 ører ble korninnholdet i øret målt ( X), pigglengde ( Y) og massen av korn i øret ( Z). Finn konfidensintervaller for det generelle gjennomsnittet og variansen for P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 hvis
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064. (25 poeng).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064. (25 poeng).
13. I tilfeldig utvalgte 100 aks høsthvete ble antall aks telt. Prøvesettet ble preget av følgende indikatorer:
 = 15 spikelets og σ = 2,28 stk. Bestem nøyaktigheten som gjennomsnittsresultatet oppnås med (
= 15 spikelets og σ = 2,28 stk. Bestem nøyaktigheten som gjennomsnittsresultatet oppnås med (  ) og plott konfidensintervallet for det totale gjennomsnittet og variansen ved 95 % og 99 % signifikansnivåer (30 poeng).
) og plott konfidensintervallet for det totale gjennomsnittet og variansen ved 95 % og 99 % signifikansnivåer (30 poeng).
14. Antall ribber på skjellene til en fossil bløtdyr Orthambonitter kalligramma:
Det er kjent at n = 19, σ = 4,25. Bestem grensene for konfidensintervallet for det generelle gjennomsnittet og den generelle variansen på et signifikansnivå W = 0,01 (25 poeng).
15. For å bestemme melkeavlingen på en kommersiell melkegård ble produktiviteten til 15 kyr bestemt daglig. Ifølge dataene for året ga hver ku i gjennomsnitt følgende melkemengde per dag (l): 22; 19; 25; 20; 27; 17; tretti; 21; 18; 24; 26; 23; 25; 20; 24. Plott konfidensintervaller for den generelle variansen og det aritmetiske gjennomsnittet. Kan vi forvente at gjennomsnittlig årlig melkeytelse per ku er 10 000 liter? (50 poeng).
16. For å bestemme gjennomsnittlig hveteavling for gården ble det foretatt slått på prøveflater på 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 og 2 ha. Avlingen (c/ha) fra tomtene var 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 henholdsvis. Plott konfidensintervaller for den generelle variansen og det aritmetiske gjennomsnittet. Er det mulig å forvente at gjennomsnittsavlingen for landbruksbedriften blir 42 c/ha? (50 poeng).
I statistikk er det to typer estimater: punkt og intervall. Poengvurdering er en enkelt utvalgsstatistikk som brukes til å estimere en populasjonsparameter. For eksempel gjennomsnittet for prøven er et punktestimat av populasjonsgjennomsnittet og utvalgsvariansen S2- punktestimat av populasjonsvariasjonen σ2. det ble vist at utvalgets gjennomsnitt er et objektivt estimat av populasjonsforventningen. Utvalgsgjennomsnittet kalles upartisk fordi gjennomsnittet av alle utvalgsmidler (med samme prøvestørrelse n) er lik den matematiske forventningen til den generelle befolkningen.
For utvalgets variasjon S2 ble en objektiv estimator av populasjonsvariansen σ2, bør nevneren for utvalgsvariansen settes lik n – 1 , men ikke n. Med andre ord er populasjonsvariansen gjennomsnittet av alle mulige utvalgsvariasjoner.
Ved estimering av populasjonsparametere bør man huske på at utvalgsstatistikk som f.eks , avhenger av spesifikke prøver. For å ta hensyn til dette faktum, for å få intervall estimering den matematiske forventningen til den generelle befolkningen analyserer fordelingen av utvalgsmidler (for flere detaljer, se). Det konstruerte intervallet er preget av et visst konfidensnivå, som er sannsynligheten for at den sanne parameteren til den generelle befolkningen er estimert riktig. Lignende konfidensintervaller kan brukes til å estimere andelen av en funksjon R og den viktigste distribuerte massen av den generelle befolkningen.
Last ned notat i eller format, eksempler i format
Konstruksjon av et konfidensintervall for den matematiske forventningen til den generelle befolkningen med et kjent standardavvik
Bygge et konfidensintervall for andelen av en egenskap i den generelle befolkningen
I denne delen utvides konseptet med et konfidensintervall til kategoriske data. Dette lar deg estimere andelen av egenskapen i den generelle befolkningen R med en prøveandel RS= X/n. Som nevnt, hvis verdiene nR Og n(1 - p) over tallet 5, kan binomialfordelingen tilnærmes med normalen. Derfor å estimere andelen av en egenskap i den generelle befolkningen R det er mulig å konstruere et intervall hvis konfidensnivå er lik (1 - α)x100 %.

Hvor sS- prøveandel av funksjonen, lik X/n, dvs. antall suksesser delt på prøvestørrelsen, R- andelen av egenskapen i den generelle befolkningen, Z er den kritiske verdien av den standardiserte normalfordelingen, n- prøvestørrelse.
Eksempel 3 La oss anta at det er hentet ut en prøve fra informasjonssystemet, bestående av 100 fakturaer utfylt i løpet av den siste måneden. La oss si at 10 av disse fakturaene er feil. Dermed, R= 10/100 = 0,1. 95 % konfidensnivå tilsvarer den kritiske verdien Z = 1,96.
Dermed er det 95 % sjanse for at mellom 4,12 % og 15,88 % av fakturaene inneholder feil.
For en gitt utvalgsstørrelse ser konfidensintervallet som inneholder andelen av egenskapen i den generelle populasjonen ut til å være bredere enn for en kontinuerlig tilfeldig variabel. Dette er fordi målinger av en kontinuerlig tilfeldig variabel inneholder mer informasjon enn målinger av kategoriske data. Med andre ord, kategoriske data som bare tar to verdier inneholder utilstrekkelig informasjon til å estimere parametrene for deres distribusjon.
Iberegning av estimater hentet fra en begrenset populasjon
Estimering av matematisk forventning. Korreksjonsfaktor for den endelige populasjonen ( fpc) ble brukt for å redusere standardfeilen med en faktor på . Ved beregning av konfidensintervaller for estimater av populasjonsparametere benyttes en korreksjonsfaktor i situasjoner der utvalg trekkes uten erstatning. Dermed vil konfidensintervallet for den matematiske forventningen ha et konfidensnivå lik (1 - α)x100 %, beregnes med formelen:

Eksempel 4 For å illustrere bruken av en korreksjonsfaktor for en begrenset populasjon, la oss gå tilbake til problemet med å beregne konfidensintervallet for gjennomsnittlig antall fakturaer omtalt i eksempel 3 ovenfor. Anta at et selskap utsteder 5000 fakturaer per måned, og X̅=110,27 USD, S= $28,95 N = 5000, n = 100, α = 0,05, t99 = 1,9842. I henhold til formel (6) får vi:
Estimering av andelen av funksjonen. Når du velger ingen retur, konfidensintervallet for andelen av funksjonen som har et konfidensnivå lik (1 - α)x100 %, beregnes med formelen:

Konfidensintervaller og etiske spørsmål
Når man prøver en populasjon og formulerer statistiske slutninger, oppstår det ofte etiske problemer. Den viktigste er hvordan konfidensintervallene og punktestimatene for utvalgsstatistikk stemmer overens. Publisering av punktestimater uten å spesifisere passende konfidensintervaller (vanligvis ved 95 % konfidensnivå) og utvalgsstørrelsen de er utledet fra, kan være misvisende. Dette kan gi brukeren inntrykk av at et punktestimat er akkurat det han trenger for å forutsi egenskapene til hele populasjonen. Derfor er det nødvendig å forstå at i enhver forskning bør ikke punkt, men intervallestimater settes i forgrunnen. I tillegg bør spesiell oppmerksomhet rettes mot riktig valg av prøvestørrelser.
Oftest er gjenstandene for statistiske manipulasjoner resultatene av sosiologiske undersøkelser av befolkningen om forskjellige politiske spørsmål. Samtidig legges resultatene av undersøkelsen på forsiden av avisene, og prøvetakingsfeilen og metodikken for statistisk analyse trykkes et sted i midten. For å bevise gyldigheten av de oppnådde punktestimatene, er det nødvendig å indikere utvalgsstørrelsen de ble oppnådd på grunnlag av, grensene for konfidensintervallet og dets signifikansnivå.
Neste notat
Materiale fra boken Levin mfl. Statistikk for ledere benyttes. - M.: Williams, 2004. - s. 448–462
Sentral grensesetning sier at, gitt en tilstrekkelig stor utvalgsstørrelse, kan utvalgsfordelingen av gjennomsnitt tilnærmes ved en normalfordeling. Denne egenskapen er ikke avhengig av type befolkningsfordeling.
Og andre. Alle er estimater av deres teoretiske motstykker, som kunne oppnås hvis det ikke var et utvalg, men den generelle befolkningen. Men dessverre, den generelle befolkningen er veldig dyr og ofte utilgjengelig.
Konseptet med intervallestimering
Ethvert prøveestimat har en viss spredning, fordi er en tilfeldig variabel avhengig av verdiene i en bestemt prøve. Derfor, for mer pålitelige statistiske slutninger, bør man kjenne ikke bare punktestimatet, men også intervallet, som med stor sannsynlighet γ (gamma) dekker den estimerte indikatoren θ (theta).
Formelt sett er dette to slike verdier (statistikk) T1(X) Og T2(X), Hva T1< T 2 , for hvilket på et gitt sannsynlighetsnivå γ betingelsen er oppfylt:
Kort sagt, det er sannsynlig γ eller mer er den sanne verdien mellom punktene T1(X) Og T2(X), som kalles nedre og øvre grenser konfidensintervall.
En av betingelsene for å konstruere konfidensintervaller er dens maksimale smalhet, dvs. den skal være så kort som mulig. Ønske er ganske naturlig, fordi. forskeren prøver å mer nøyaktig lokalisere funnet av ønsket parameter.
Det følger at konfidensintervallet skal dekke de maksimale sannsynlighetene for fordelingen. og selve poengsummen være i sentrum.
![]()
Det vil si at sannsynligheten for avvik (av den sanne indikatoren fra estimatet) oppover er lik sannsynligheten for avvik nedover. Det bør også bemerkes at for skjeve fordelinger er intervallet til høyre ikke likt intervallet til venstre.
Figuren over viser tydelig at jo større konfidensnivå, desto bredere intervall - en direkte sammenheng.
Dette var en liten introduksjon til teorien om intervallestimering av ukjente parametere. La oss gå videre til å finne konfidensgrenser for den matematiske forventningen.
Konfidensintervall for matematisk forventning
Hvis de opprinnelige dataene er fordelt over , vil gjennomsnittet være en normalverdi. Dette følger av regelen om at en lineær kombinasjon av normalverdier også har en normalfordeling. Derfor, for å beregne sannsynlighetene, kunne vi bruke det matematiske apparatet til normalfordelingsloven.
Dette vil imidlertid kreve kunnskap om to parametere - forventet verdi og varians, som vanligvis ikke er kjent. Du kan selvfølgelig bruke estimater i stedet for parametere (aritmetisk gjennomsnitt og ), men da blir ikke fordelingen av gjennomsnittet helt normalt, det blir litt flatt ned. Borger William Gosset fra Irland bemerket dette faktum da han publiserte oppdagelsen sin i mars 1908-utgaven av Biometrica. Av hensyn til hemmelighold signerte Gosset med Student. Slik fremsto Studentens t-fordeling.
Normalfordelingen av data, brukt av K. Gauss i analysen av feil i astronomiske observasjoner, er imidlertid ekstremt sjelden i terrestrisk liv, og det er ganske vanskelig å fastslå dette (ca. 2 tusen observasjoner er nødvendig for høy nøyaktighet). Derfor er det best å droppe normalitetsantagelsen og bruke metoder som ikke er avhengig av distribusjonen av de originale dataene.
Spørsmålet oppstår: hva er fordelingen av det aritmetiske gjennomsnittet hvis det beregnes fra dataene til en ukjent distribusjon? Svaret er gitt av den velkjente innen sannsynlighetsteori Sentral grensesetning(CPT). I matematikk finnes det flere versjoner av det (formuleringene har blitt finpusset opp gjennom årene), men alle kommer grovt sett ned til påstanden om at summen av et stort antall uavhengige stokastiske variabler følger normalfordelingsloven.
Ved beregning av det aritmetiske gjennomsnittet brukes summen av tilfeldige variabler. Fra dette viser det seg at det aritmetiske gjennomsnittet har en normalfordeling, der forventet verdi er forventet verdi av de første dataene, og variansen er .
Smarte folk vet hvordan de skal bevise CLT, men vi vil verifisere dette ved hjelp av et eksperiment utført i Excel. La oss simulere et utvalg av 50 jevnt fordelte tilfeldige variabler (ved å bruke Excel-funksjonen TILFELDIG MELLOM). Så skal vi lage 1000 slike prøver og beregne det aritmetiske gjennomsnittet for hver. La oss se på fordelingen deres.

Man kan se at fordelingen av gjennomsnittet er nær normalloven. Hvis volumet av prøver og deres antall gjøres enda større, vil likheten bli enda bedre.
Nå som vi selv har sett gyldigheten til CLT, kan vi ved å bruke , beregne konfidensintervallene for det aritmetiske gjennomsnittet, som dekker det sanne gjennomsnittet eller den matematiske forventningen med en gitt sannsynlighet.
For å etablere øvre og nedre grenser, er det nødvendig å kjenne parametrene til normalfordelingen. Som regel er de ikke, derfor brukes estimater: aritmetisk gjennomsnitt Og prøveavvik. Igjen gir denne metoden en god tilnærming bare for store prøver. Når utvalgene er små, anbefales det ofte å bruke Students fordeling. Ikke tro! Elevens fordeling for gjennomsnittet skjer bare når de opprinnelige dataene har en normalfordeling, det vil si nesten aldri. Derfor er det bedre å umiddelbart sette minimumslinjen for mengden nødvendige data og bruke asymptotisk korrekte metoder. De sier at 30 observasjoner er nok. Ta 50 - du kan ikke gå galt.
![]()
T 1.2 er de nedre og øvre grensene for konfidensintervallet
– eksempel aritmetisk gjennomsnitt
s0– prøvestandardavvik (uhildet)
n – prøvestørrelse
γ – konfidensnivå (vanligvis lik 0,9, 0,95 eller 0,99)
c γ =Φ -1 ((1+γ)/2) er den gjensidige av standard normalfordelingsfunksjonen. Enkelt sagt er dette antallet standardfeil fra det aritmetiske gjennomsnittet til den nedre eller øvre grensen (de angitte tre sannsynlighetene tilsvarer verdiene 1,64, 1,96 og 2,58).
Essensen av formelen er at det aritmetiske gjennomsnittet tas og deretter settes en viss mengde til side fra det ( med γ) standardfeil ( s 0 /√n). Alt er kjent, ta det og tell.
Før massebruken av PC-er, for å få verdiene til normalfordelingsfunksjonen og dens inverse, brukte de . De brukes fortsatt, men det er mer effektivt å vende seg til ferdige Excel-formler. Alle elementer fra formelen ovenfor ( , og ) kan enkelt beregnes i Excel. Men det er også en ferdig formel for å beregne konfidensintervallet - TILLITSNORM. Syntaksen er som følger.
KONFIDENSNORM(alfa; standard_dev; størrelse)
alfa– signifikansnivå eller konfidensnivå, som i notasjonen ovenfor er lik 1-γ, dvs. sannsynligheten for at den matematiskeforventningen vil være utenfor konfidensintervallet. Med et konfidensnivå på 0,95 er alfa 0,05, og så videre.
standard_av er standardavviket til prøvedataene. Du trenger ikke å beregne standardfeilen, Excel deler med roten av n.
størrelse– prøvestørrelse (n).
Resultatet av KONFIDENS.NORM-funksjonen er det andre leddet fra formelen for beregning av konfidensintervallet, dvs. halvt intervall. Følgelig er de nedre og øvre punktene gjennomsnittet ± den oppnådde verdien.
Dermed er det mulig å bygge en universell algoritme for å beregne konfidensintervaller for det aritmetiske gjennomsnittet, som ikke er avhengig av fordelingen av de opprinnelige dataene. Prisen for universalitet er dens asymptotiske natur, dvs. behovet for å bruke relativt store prøver. Men i en tidsalder med moderne teknologi er det vanligvis ikke vanskelig å samle inn riktig mengde data.
Testing av statistiske hypoteser ved hjelp av et konfidensintervall
(modul 111)
Et av hovedproblemene som løses i statistikk er. I et nøtteskall er essensen dette. Det forutsettes for eksempel at forventningen til befolkningen generelt er lik en verdi. Deretter konstrueres fordelingen av utvalgsmidler, som kan observeres med en gitt forventning. Deretter ser vi på hvor i denne betingede fordelingen det reelle gjennomsnittet befinner seg. Hvis det går utover de tillatte grensene, er utseendet til et slikt gjennomsnitt svært usannsynlig, og med en enkelt repetisjon av eksperimentet er det nesten umulig, noe som er i strid med hypotesen som ble fremsatt, som ble avvist. Hvis gjennomsnittet ikke går utover det kritiske nivået, så forkastes ikke hypotesen (men den er heller ikke bevist!).
Så, ved hjelp av konfidensintervaller, i vårt tilfelle for forventningen, kan du også teste noen hypoteser. Det er veldig enkelt å gjøre. Anta at det aritmetiske gjennomsnittet for et utvalg er 100. Hypotesen testes om at forventningen for eksempel er 90. Det vil si at hvis vi setter spørsmålet primitivt, høres det slik ut: kan det være slik med den sanne verdien av gjennomsnittet lik 90, det observerte gjennomsnittet var 100?
For å svare på dette spørsmålet vil tilleggsinformasjon om standardavvik og prøvestørrelse være nødvendig. La oss si at standardavviket er 30, og antallet observasjoner er 64 (for enkelt å trekke ut roten). Da er standardfeilen til gjennomsnittet 30/8 eller 3,75. For å beregne 95 % konfidensintervall, må du sette til side to standardfeil på begge sider av gjennomsnittet (mer presist, 1,96). Konfidensintervallet vil være omtrent 100 ± 7,5, eller fra 92,5 til 107,5.
Ytterligere begrunnelse er som følger. Hvis den testede verdien faller innenfor konfidensintervallet, motsier den ikke hypotesen, siden passer innenfor grensene for tilfeldige svingninger (med en sannsynlighet på 95%). Hvis det testede punktet er utenfor konfidensintervallet, er sannsynligheten for en slik hendelse svært liten, i alle fall under det akseptable nivået. Derfor avvises hypotesen som motsier de observerte dataene. I vårt tilfelle er forventningshypotesen utenfor konfidensintervallet (den testede verdien på 90 er ikke inkludert i intervallet 100±7,5), så den bør forkastes. Ved å svare på det primitive spørsmålet ovenfor bør man si: nei, det kan ikke i alle fall, dette skjer ekstremt sjelden. Ofte indikerer dette en spesifikk sannsynlighet for feilaktig avvisning av hypotesen (p-nivå), og ikke et gitt nivå, som konfidensintervallet ble bygget etter, men mer om det en annen gang.
Som du kan se, er det ikke vanskelig å bygge et konfidensintervall for gjennomsnittet (eller den matematiske forventningen). Det viktigste er å fange essensen, og så vil ting gå. I praksis bruker de fleste 95 % konfidensintervallet, som er omtrent to standardfeil brede på hver side av gjennomsnittet.
Det er alt for nå. Beste ønsker!