Przedział ufności dla szacowania średniej (znana jest dyspersja) w MS EXCEL. Przedział ufności
Każda próbka daje tylko przybliżone wyobrażenie o ogólnej populacji, a wszystkie cechy statystyczne próbki (średnia, moda, wariancja ...) są pewnym przybliżeniem lub powiedzmy oszacowaniem ogólnych parametrów, których w większości przypadków nie można obliczyć ze względu na niedostępność populacji ogólnej (rysunek 20) .
Rysunek 20. Błąd próbkowania
Można jednak określić przedział, w którym z pewnym prawdopodobieństwem znajduje się prawdziwa (ogólna) wartość cechy statystycznej. Ten przedział nazywa się d przedział ufności (CI).
Zatem ogólna średnia z prawdopodobieństwem 95% mieści się w granicach
od do, (20)
gdzie t - wartość tabelaryczną kryterium Studenta dla α =0,05 i f= n-1
Można znaleźć i 99% CI, w tym przypadku t wybrany do α =0,01.
Jakie jest praktyczne znaczenie przedziału ufności?
Szeroki przedział ufności wskazuje, że średnia próbki nie odzwierciedla dokładnie średniej populacji. Wynika to zwykle z niewystarczającej liczebności próby lub jej niejednorodności, tj. duża dyspersja. Oba dają duży błąd średniej i odpowiednio szerszy CI. I to jest powód do powrotu do etapu planowania badań.
Górna i dolna granica CI oceniają, czy wyniki będą istotne klinicznie
Zajmijmy się bardziej szczegółowo kwestią statystycznego i klinicznego znaczenia wyników badania właściwości grupowych. Przypomnijmy, że zadaniem statystyki jest wykrycie przynajmniej pewnych różnic w populacjach ogólnych na podstawie danych próbnych. Zadaniem klinicysty jest znalezienie takich (nie żadnych) różnic, które pomogą w diagnozie lub leczeniu. I nie zawsze wnioski statystyczne są podstawą wniosków klinicznych. Zatem statystycznie istotny spadek stężenia hemoglobiny o 3 g/l nie jest powodem do niepokoju. I odwrotnie, jeśli jakiś problem w organizmie człowieka nie ma charakteru masowego na poziomie całej populacji, to nie jest to powód, by się tym problemem nie zajmować.
|
Rozważymy to stanowisko w przykład. Naukowcy zastanawiali się, czy chłopcy, którzy cierpieli na jakąś chorobę zakaźną, pozostają w tyle za swoimi rówieśnikami we wzroście. W tym celu przeprowadzono selektywne badanie, w którym wzięło udział 10 chłopców z tą chorobą. Wyniki przedstawiono w tabeli 23. Tabela 23. Wyniki statystyczne
Z tych obliczeń wynika, że selektywny średni wzrost 10-letnich chłopców, którzy przeszli jakąś chorobę zakaźną, jest zbliżony do normalnego (132,5 cm). Jednak dolna granica przedziału ufności (126,6 cm) wskazuje, że istnieje 95% prawdopodobieństwo, że prawdziwy średni wzrost tych dzieci odpowiada pojęciu „niskiego wzrostu”, tj. te dzieci są zahamowane. W tym przykładzie wyniki obliczeń przedziału ufności są istotne klinicznie. |
|||||||||||||||||||
W poprzednich podrozdziałach rozważaliśmy kwestię szacowania nieznanego parametru a jeden numer. Taka ocena nazywana jest „punktem”. W wielu zadaniach wymagane jest nie tylko znalezienie parametru a odpowiednią wartość liczbową, ale także ocenić jej dokładność i wiarygodność. Wymagana jest wiedza, do jakich błędów może prowadzić podstawianie parametrów a jego oszacowanie punktowe a iz jakim stopniem pewności możemy oczekiwać, że błędy te nie wykroczą poza znane granice?
Tego rodzaju problemy są szczególnie istotne dla niewielkiej liczby obserwacji, gdy estymacja punktowa i w jest w dużej mierze przypadkowa, a przybliżone zastąpienie a przez a może prowadzić do poważnych błędów.
Aby dać wyobrażenie o dokładności i wiarygodności oszacowania a,
w statystyce matematycznej stosuje się tak zwane przedziały ufności i prawdopodobieństwa ufności.
Niech dla parametru a pochodzą z bezstronnych oszacowań z doświadczenia a. Chcemy oszacować możliwy błąd w tym przypadku. Przypiszmy pewne wystarczająco duże prawdopodobieństwo p (na przykład p = 0,9, 0,95 lub 0,99) takie, że zdarzenie z prawdopodobieństwem p można uznać za praktycznie pewne, i znajdźmy wartość s, dla której
Następnie zakres praktycznie możliwych wartości błędu jaki występuje przy wymianie a na a, będzie ± s; duże błędy bezwzględne pojawią się tylko z małym prawdopodobieństwem a = 1 - p. Przepiszmy (14.3.1) jako:
Równość (14.3.2) oznacza, że z prawdopodobieństwem p nieznana wartość parametru a mieści się w przedziale
W takim przypadku należy zwrócić uwagę na jedną okoliczność. Wcześniej wielokrotnie rozważaliśmy prawdopodobieństwo, że zmienna losowa znajdzie się w danym przedziale nielosowym. Tutaj sytuacja jest inna: a nie losowy, ale losowy przedział / r. Losowo jego pozycja na osi x, określona przez jego środek a; ogólnie długość przedziału 2s jest również losowa, ponieważ wartość s jest obliczana z reguły na podstawie danych eksperymentalnych. Dlatego w tym przypadku lepiej byłoby interpretować wartość p, a nie jako prawdopodobieństwo „trafienia” w punkt a do przedziału /p, ale jako prawdopodobieństwo, że losowy przedział /p pokryje punkt a(rys. 14.3.1).

Ryż. 14.3.1
Prawdopodobieństwo p nazywa się poziom zaufania, a interwał / p - przedział ufności. Granice przedziałów jeśli. a x \u003d a- s i a 2 = a + i nazywają się granice zaufania.
Podajmy jeszcze jedną interpretację pojęcia przedziału ufności: można go traktować jako przedział wartości parametrów a, zgodne z danymi eksperymentalnymi i nie zaprzeczające im. Rzeczywiście, jeśli zgodzimy się uznać zdarzenie z prawdopodobieństwem a = 1-p praktycznie niemożliwe, to te wartości parametru a, dla których a - a> s należy uznać za sprzeczne z danymi eksperymentalnymi oraz takimi, dla których |a - a w na 2 .
Niech dla parametru a istnieje bezstronna ocena a. Gdybyśmy znali prawo rozkładu ilości a, problem znalezienia przedziału ufności byłby dość prosty: wystarczyłoby znaleźć wartość s, dla której
![]()
Trudność polega na tym, że prawo rozkładu oszacowania a zależy od prawa rozkładu ilości X a w konsekwencji na jego nieznanych parametrach (w szczególności na samym parametrze) a).
Aby obejść tę trudność, można zastosować następującą z grubsza przybliżoną sztuczkę: zastąp nieznane parametry w wyrażeniu na s ich szacunkowymi punktami. Przy stosunkowo dużej liczbie eksperymentów P(około 20 ... 30) ta technika zwykle daje zadowalające wyniki pod względem dokładności.
Jako przykład rozważmy problem przedziału ufności dla oczekiwań matematycznych.
Niech wyprodukowany P x, których cechami są matematyczne oczekiwanie t i wariancja D- nieznany. Dla tych parametrów uzyskano następujące szacunki:

Wymagane jest zbudowanie przedziału ufności / р odpowiadającego prawdopodobieństwu ufności р dla oczekiwań matematycznych t wielkie ilości x.
W rozwiązaniu tego problemu wykorzystujemy fakt, że ilość t jest sumą P niezależne zmienne losowe o identycznym rozkładzie X godz i zgodnie z centralnym twierdzeniem granicznym dla wystarczająco dużego P jego prawo dystrybucji jest bliskie normalności. W praktyce, nawet przy stosunkowo niewielkiej liczbie wyrazów (rzędu 10 ... 20), prawo rozkładu sumy można w przybliżeniu uznać za normalne. Założymy, że wartość t dystrybuowane zgodnie z normalnym prawem. Cechy tego prawa — matematyczne oczekiwanie i wariancja — są odpowiednio równe t oraz
(patrz rozdział 13 podrozdział 13.3). Załóżmy, że wartość D jest nam znana i znajdziemy taką wartość Ep dla której
Stosując wzór (6.3.5) z rozdziału 6, wyrażamy prawdopodobieństwo po lewej stronie (14.3.5) w postaci funkcji rozkładu normalnego
gdzie jest odchylenie standardowe oszacowania t.
Z równania

znajdź wartość Sp: 
gdzie arg Ф* (x) jest funkcją odwrotną do Ф* (X), tych. taka wartość argumentu, dla którego rozkład normalny jest równy X.
Dyspersja D, przez który wyrażona jest wartość a 1P, nie wiemy dokładnie; jako jego przybliżoną wartość możesz użyć oszacowania D(14.3.4) i umieść w przybliżeniu:

W ten sposób problem konstrukcji przedziału ufności został w przybliżeniu rozwiązany, który jest równy:
gdzie gp jest określone wzorem (14.3.7).
Aby uniknąć odwrotnej interpolacji w tabelach funkcji Ф * (l) przy obliczaniu s p, wygodnie jest skompilować specjalną tabelę (tabela 14.3.1), która zawiera wartości ilości
w zależności od r. Wartość (p określa dla prawa normalnego liczbę odchyleń standardowych, które muszą być odłożone na prawo i lewo od środka dyspersji, aby prawdopodobieństwo wpadnięcia do wynikowego obszaru było równe p.
Poprzez wartość 7 p, przedział ufności wyraża się jako:

Tabela 14.3.1
Przykład 1. Przeprowadzono 20 eksperymentów na wartości x; wyniki przedstawiono w tabeli. 14.3.2.
Tabela 14.3.2
Wymagane jest znalezienie oszacowania matematycznego oczekiwania ilości X i skonstruuj przedział ufności odpowiadający poziomowi ufności p = 0,8.
Rozwiązanie. Mamy:

Wybierając początek n: = 10, zgodnie z trzecim wzorem (14.2.14) znajdujemy bezstronne oszacowanie D :

Zgodnie z tabelą 14.3.1 znajdujemy ![]()
![]()
Granice zaufania:

Przedział ufności:
![]()
Wartości parametrów t, leżące w tym przedziale są zgodne z danymi eksperymentalnymi podanymi w tabeli. 14.3.2.
W podobny sposób można skonstruować przedział ufności dla wariancji.
Niech wyprodukowany P niezależne eksperymenty na zmiennej losowej X o nieznanych parametrach z i A oraz dla wariancji D uzyskano obiektywne oszacowanie:


Wymagane jest w przybliżeniu zbudowanie przedziału ufności dla wariancji.
Ze wzoru (14.3.11) widać, że wartość D reprezentuje
ilość P zmienne losowe postaci . Te wartości nie są
niezależny, ponieważ każdy z nich zawiera ilość t, zależny od wszystkich innych. Można jednak wykazać, że jak P prawo podziału ich sumy jest również bliskie normalności. Prawie o godz P= 20...30 można już uważać za normalne.
Załóżmy, że tak jest i znajdźmy cechy charakterystyczne tego prawa: oczekiwanie matematyczne i wariancję. Od wyniku D- więc bezstronny M[D] = D.
Obliczanie wariancji D D wiąże się ze stosunkowo złożonymi obliczeniami, dlatego podajemy jego wyrażenie bez wyprowadzania:
gdzie c 4 - czwarty centralny moment wielkości x.
Aby użyć tego wyrażenia, musisz w nim zastąpić wartości 4 i D(przynajmniej przybliżona). Zamiast D możesz skorzystać z wyceny D. W zasadzie czwarty moment centralny można również zastąpić jego oszacowaniem, na przykład wartością postaci:

ale taka zamiana da wyjątkowo niską dokładność, ponieważ ogólnie przy ograniczonej liczbie eksperymentów momenty wyższego rzędu są określane z dużymi błędami. Jednak w praktyce często zdarza się, że postać prawa rozkładu ilości X znane z góry: nieznane są tylko jego parametry. Następnie możemy spróbować wyrazić u4 w kategoriach D.
Weźmy najczęstszy przypadek, gdy wartość X dystrybuowane zgodnie z normalnym prawem. Wtedy jego czwarty centralny moment jest wyrażony w postaci wariancji (patrz Rozdział 6, podrozdział 6.2);
![]()
a wzór (14.3.12) daje  lub
lub
Zastąpienie w (14.3.14) nieznanego D jego ocena D, otrzymujemy: skąd 
Moment u 4 można wyrazić w postaci D także w niektórych innych przypadkach, gdy rozkład ilości X nie jest normalne, ale jego wygląd jest znany. Na przykład dla prawa jednorodnej gęstości (patrz rozdział 5) mamy: 
gdzie (a, P) jest przedziałem, w którym dane prawo jest dane.
W konsekwencji,
![]()
Zgodnie ze wzorem (14.3.12) otrzymujemy:  skąd znajdujemy około
skąd znajdujemy około
W przypadkach, gdy nie jest znana postać prawa rozkładu wartości 26, przy szacowaniu wartości a/) nadal zaleca się stosowanie wzoru (14.3.16), jeśli nie ma szczególnych podstaw do przypuszczenia, że to prawo bardzo różni się od normalnego (ma zauważalną dodatnią lub ujemną kurtozę) .
Jeśli przybliżona wartość a /) zostanie uzyskana w taki czy inny sposób, to możliwe jest skonstruowanie przedziału ufności dla wariancji w taki sam sposób, jak zbudowaliśmy go dla matematycznego oczekiwania:
gdzie wartość zależną od danego prawdopodobieństwa p znajduje się w tabeli. 14.3.1.
Przykład 2. Znajdź około 80% przedział ufności dla wariancji zmiennej losowej X na warunkach z przykładu 1, jeśli wiadomo, że wartość X dystrybuowane zgodnie z prawem zbliżonym do normalnego.
Rozwiązanie. Wartość pozostaje taka sama jak w tabeli. 14.3.1:
![]()
Zgodnie ze wzorem (14.3.16)

Zgodnie ze wzorem (14.3.18) znajdujemy przedział ufności:
![]()
Odpowiedni zakres wartości odchylenia standardowego: (0,21; 0,29).
14.4. Dokładne metody konstruowania przedziałów ufności dla parametrów zmiennej losowej o rozkładzie zgodnie z prawem normalnym
W poprzednim podrozdziale rozważyliśmy z grubsza przybliżone metody konstruowania przedziałów ufności dla średniej i wariancji. Tutaj podajemy wyobrażenie o dokładnych metodach rozwiązania tego samego problemu. Podkreślamy, że w celu dokładnego wyznaczenia przedziałów ufności bezwzględnie konieczne jest wcześniejsze poznanie postaci prawa rozkładu wielkości x, natomiast nie jest to konieczne do zastosowania metod przybliżonych.
Idea dokładnych metod konstruowania przedziałów ufności jest następująca. Dowolny przedział ufności znajduje się z warunku wyrażającego prawdopodobieństwo spełnienia pewnych nierówności, które zawierają interesujące nas oszacowanie a. Prawo podziału ocen a w ogólnym przypadku zależy od nieznanych parametrów ilości x. Czasami jednak można przekazać nierówności ze zmiennej losowej a do innej funkcji obserwowanych wartości Xp X 2, ..., X s. którego prawo rozkładu nie zależy od nieznanych parametrów, ale zależy tylko od liczby eksperymentów i postaci prawa rozkładu wielkości x. Zmienne losowe tego rodzaju odgrywają dużą rolę w statystyce matematycznej; zostały one szczegółowo zbadane dla przypadku normalnego rozkładu ilości x.
Udowodniono na przykład, że przy normalnym rozkładzie ilości X wartość losowa

podlega tzw Prawo dystrybucji studenckiej Z P- 1 stopień swobody; gęstość tego prawa ma postać

gdzie G(x) jest znaną funkcją gamma:

Udowodniono również, że zmienna losowa
ma "dystrybucja % 2 " z P- 1 stopień swobody (patrz rozdział 7), którego gęstość wyraża wzór

Nie zagłębiając się w wyprowadzenia rozkładów (14.4.2) i (14.4.4), pokażemy, jak można je zastosować przy konstruowaniu przedziałów ufności dla parametrów Ty D .
Niech wyprodukowany P niezależne eksperymenty na zmiennej losowej x, rozłożone zgodnie z prawem normalnym o nieznanych parametrach TIO. Dla tych parametrów szacunki

Wymagane jest skonstruowanie przedziałów ufności dla obu parametrów odpowiadających prawdopodobieństwu ufności p.
Najpierw skonstruujmy przedział ufności dla oczekiwań matematycznych. Naturalne jest przyjęcie tego przedziału symetrycznie względem t; oznacz przez s p połowę długości przedziału. Wartość sp należy dobrać tak, aby warunek
Spróbujmy przekazać lewą stronę równości (14.4.5) ze zmiennej losowej t do zmiennej losowej T, dystrybuowane zgodnie z prawem studenckim. W tym celu mnożymy obie części nierówności |m-w?|
na wartość dodatnią:  lub używając notacji (14.4.1),
lub używając notacji (14.4.1),

Znajdźmy liczbę /p taką, że wartość /p można znaleźć z warunku

Ze wzoru (14.4.2) widać, że (1) jest funkcją parzystą, więc (14.4.8) daje 
Równość (14.4.9) określa wartość /p w zależności od p. Jeśli masz do dyspozycji tabelę wartości całkowitych

wtedy wartość /p można znaleźć przez odwrotną interpolację w tabeli. Jednak wygodniej jest wcześniej skompilować tabelę wartości / p. Taka tabela znajduje się w załączniku (tabela 5). Ta tabela pokazuje wartości w zależności od prawdopodobieństwa ufności p i liczby stopni swobody P- 1. Po ustaleniu /p zgodnie z tabelą. 5 i zakładając 
znajdujemy połowę szerokości przedziału ufności / p i sam przedział
Przykład 1. Przeprowadzono 5 niezależnych eksperymentów na zmiennej losowej x, rozkład normalny o nieznanych parametrach t i o. Wyniki eksperymentów podano w tabeli. 14.4.1.
Tabela 14.4.1
Znajdź wycenę t dla matematycznego oczekiwania i skonstruuj dla niego 90% przedział ufności / p (tj. przedział odpowiadający prawdopodobieństwu ufności p = 0,9).
Rozwiązanie. Mamy:
![]()
Zgodnie z tabelą 5 wniosku o P - 1 = 4 i p = 0,9 znajdujemy ![]() gdzie
gdzie 
Przedział ufności będzie
Przykład 2. Dla warunków z przykładu 1 podrozdziału 14.3, przyjmując wartość X rozkład normalny, znajdź dokładny przedział ufności.
Rozwiązanie. Zgodnie z tabelą 5 wniosku znajdujemy w P - 1 = 19ir =
0,8 / p = 1,328; stąd 
Porównując z rozwiązaniem z przykładu 1 z podrozdziału 14.3 (e p = 0,072) widzimy, że rozbieżność jest bardzo mała. Jeśli zachowamy dokładność do drugiego miejsca po przecinku, to przedziały ufności znalezione metodą dokładną i przybliżoną są takie same:
![]()
Przejdźmy do skonstruowania przedziału ufności dla wariancji. Rozważ bezstronne oszacowanie wariancji

i wyrazić zmienną losową D poprzez wartość V(14.4.3) o rozkładzie x 2 (14.4.4):

Znajomość prawa rozkładu ilości V, można znaleźć przedział / (1 ), w którym mieści się on z zadanym prawdopodobieństwem p.
prawo dystrybucyjne k n _ x (v) wartość I 7 ma postać pokazaną na ryc. 14.4.1.

Ryż. 14.4.1
Powstaje pytanie: jak wybrać interwał/p? Jeśli prawo dystrybucji ilości V był symetryczny (jak prawo normalne lub rozkład Studenta), naturalne byłoby przyjęcie przedziału /p symetrycznego względem oczekiwań matematycznych. W tym przypadku prawo k n _ x (v) asymetryczny. Umówmy się na taki dobór przedziału /p, aby prawdopodobieństwa wyjścia wielkości V poza przedziałem po prawej i lewej stronie (obszary zacienione na ryc. 14.4.1) były takie same i równe

Aby skonstruować interwał / p z tą właściwością, używamy tabeli. 4 aplikacje: zawiera liczby y) takie, że
![]()
za ilość V, mając x 2 -rozkład z r stopniami swobody. W naszym przypadku r = n- 1. Napraw r = n-1 i znajdź w odpowiednim wierszu tabeli. 4 dwie wartości x 2 - jedno odpowiada prawdopodobieństwu drugie - prawdopodobieństwa Wyznaczmy je
wartości o 2 oraz XL? Interwał ma r 2 , z jego lewą stroną i ja ~ prawy koniec.
Teraz znajdujemy wymagany przedział ufności /| dla wariancji z granicami D, oraz D2, który obejmuje punkt D z prawdopodobieństwem p: ![]()
Skonstruujmy taki przedział / (, = (?> b A), który obejmuje punkt D wtedy i tylko wtedy, gdy wartość V wpada w przedział / r. Pokażmy, że interwał

spełnia ten warunek. Rzeczywiście, nierówności  są równoznaczne z nierównościami
są równoznaczne z nierównościami
![]()
a te nierówności utrzymują się z prawdopodobieństwem p. W ten sposób wyznaczany jest przedział ufności dla dyspersji, który wyraża się wzorem (14.4.13).
Przykład 3. Znajdź przedział ufności dla wariancji w warunkach przykładu 2 z podrozdziału 14.3, jeśli wiadomo, że wartość X dystrybuowane normalnie.
Rozwiązanie. Mamy ![]() . Zgodnie z tabelą 4 wniosku
. Zgodnie z tabelą 4 wniosku
znajdujemy w r = n - 1 = 19

Zgodnie ze wzorem (14.4.13) znajdujemy przedział ufności dla dyspersji ![]()
Odpowiedni przedział dla odchylenia standardowego: (0,21; 0,32). Przedział ten tylko nieznacznie przekracza przedział (0,21; 0,29) uzyskany w przykładzie 2 z podrozdziału 14.3 metodą przybliżoną.
- Rysunek 14.3.1 uwzględnia przedział ufności, który jest symetryczny względem a. Ogólnie, jak zobaczymy później, nie jest to konieczne.
Cel– nauczyć studentów algorytmów obliczania przedziałów ufności parametrów statystycznych.
Podczas statystycznego przetwarzania danych obliczona średnia arytmetyczna, współczynnik zmienności, współczynnik korelacji, kryteria różnicowe i inne statystyki punktowe powinny otrzymać ilościowe granice ufności, które wskazują możliwe wahania wskaźnika w górę iw dół w przedziale ufności.
Przykład 3.1
.
Rozkład wapnia w surowicy krwi małp, jak ustalono wcześniej, charakteryzuje się następującymi wskaźnikami selektywnymi: = 11,94 mg%;  = 0,127 mg%; n= 100. Wymagane jest wyznaczenie przedziału ufności dla średniej ogólnej (
= 0,127 mg%; n= 100. Wymagane jest wyznaczenie przedziału ufności dla średniej ogólnej (  ) z prawdopodobieństwem ufności P
= 0,95.
) z prawdopodobieństwem ufności P
= 0,95.
Ogólna średnia mieści się z pewnym prawdopodobieństwem w przedziale:
 , gdzie
, gdzie 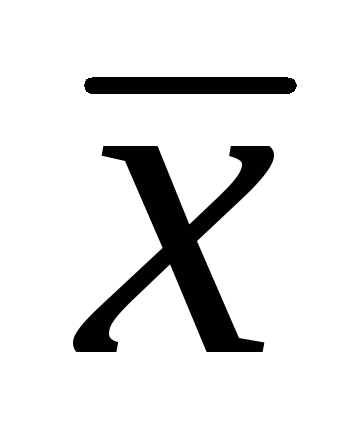 – przykładowa średnia arytmetyczna; t- Kryterium studenta;
– przykładowa średnia arytmetyczna; t- Kryterium studenta;  jest błąd średniej arytmetycznej.
jest błąd średniej arytmetycznej.
Zgodnie z tabelą „Wartości kryterium Studenta” znajdujemy wartość
 z poziomem ufności 0,95 i liczbą stopni swobody k\u003d 100-1 \u003d 99. Jest równy 1,982. Wraz z wartościami średniej arytmetycznej i błędu statystycznego podstawiamy ją do wzoru:
z poziomem ufności 0,95 i liczbą stopni swobody k\u003d 100-1 \u003d 99. Jest równy 1,982. Wraz z wartościami średniej arytmetycznej i błędu statystycznego podstawiamy ją do wzoru:
lub 11.69  12,19
12,19
Zatem z prawdopodobieństwem 95% można argumentować, że ogólna średnia tego rozkładu normalnego wynosi od 11,69 do 12,19 mg%.
Przykład 3.2
. Określ granice 95% przedziału ufności dla ogólnej wariancji (  ) dystrybucja wapnia we krwi małp, jeśli wiadomo, że
) dystrybucja wapnia we krwi małp, jeśli wiadomo, że  = 1,60, z n
= 100.
= 1,60, z n
= 100.
Aby rozwiązać problem, możesz użyć następującej formuły:
Gdzie  jest błędem statystycznym wariancji.
jest błędem statystycznym wariancji.
Znajdź przykładowy błąd wariancji za pomocą wzoru:  . Jest równy 0,11. Oznaczający t- kryterium o prawdopodobieństwie ufności 0,95 i liczbie stopni swobody k= 100–1 = 99 jest znane z poprzedniego przykładu.
. Jest równy 0,11. Oznaczający t- kryterium o prawdopodobieństwie ufności 0,95 i liczbie stopni swobody k= 100–1 = 99 jest znane z poprzedniego przykładu.
Użyjmy wzoru i uzyskajmy:
lub 1,38  1,82
1,82
Bardziej dokładny przedział ufności dla ogólnej wariancji można skonstruować za pomocą  (chi-kwadrat) - test Pearsona. Punkty krytyczne dla tego kryterium są podane w specjalnej tabeli. Korzystając z kryterium
(chi-kwadrat) - test Pearsona. Punkty krytyczne dla tego kryterium są podane w specjalnej tabeli. Korzystając z kryterium  dwustronny poziom istotności jest używany do skonstruowania przedziału ufności. Dla dolnej granicy poziom istotności oblicza się według wzoru
dwustronny poziom istotności jest używany do skonstruowania przedziału ufności. Dla dolnej granicy poziom istotności oblicza się według wzoru  , dla górnego
, dla górnego  . Na przykład dla poziomu ufności
. Na przykład dla poziomu ufności  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Zgodnie z tabelą rozkładu wartości krytycznych
= 0,990. Zgodnie z tabelą rozkładu wartości krytycznych  , z obliczonymi poziomami ufności i liczbą stopni swobody k= 100 – 1= 99, znajdź wartości
, z obliczonymi poziomami ufności i liczbą stopni swobody k= 100 – 1= 99, znajdź wartości  oraz
oraz  . dostajemy
. dostajemy  wynosi 135,80, a
wynosi 135,80, a  równa się 70,06.
równa się 70,06.
Aby znaleźć granice ufności ogólnej wariancji za pomocą  posługujemy się wzorami: na dolną granicę
posługujemy się wzorami: na dolną granicę 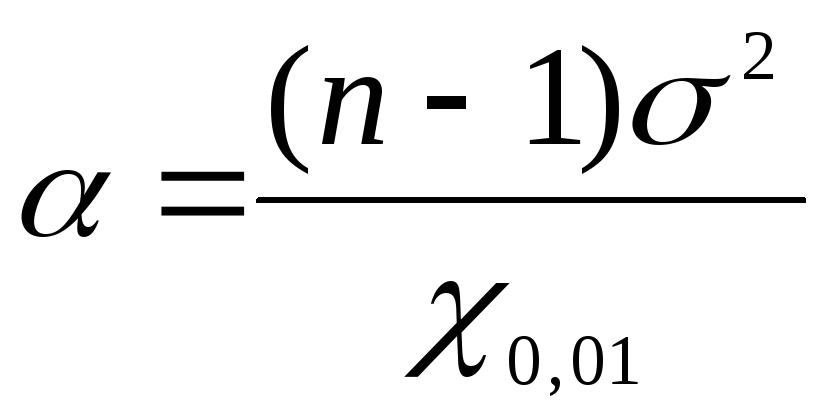 , dla górnej granicy
, dla górnej granicy  . Zastąp znalezione wartości danymi zadania
. Zastąp znalezione wartości danymi zadania  na formuły:
na formuły:  =
1,17;
=
1,17; = 2,26. Tak więc z poziomem ufności P= 0,99 lub 99% ogólna wariancja będzie mieścić się w zakresie od 1,17 do 2,26 mg% włącznie.
= 2,26. Tak więc z poziomem ufności P= 0,99 lub 99% ogólna wariancja będzie mieścić się w zakresie od 1,17 do 2,26 mg% włącznie.
Przykład 3.3 . Wśród 1000 nasion pszenicy z partii, które dotarły do elewatora, znaleziono 120 nasion zarażonych sporyszem. Konieczne jest określenie prawdopodobnych granic całkowitego udziału porażonych nasion w danej partii pszenicy.
Granice ufności dla udziału ogólnego dla wszystkich jego możliwych wartości powinny być określone wzorem:
 ,
,
Gdzie n to liczba obserwacji; m to liczba bezwzględna jednej z grup; t jest znormalizowanym odchyleniem.
Frakcja próbki porażonych nasion jest równa  lub 12%. Z poziomem ufności R= 95% znormalizowane odchylenie ( t-Kryterium studenta dla k
=
lub 12%. Z poziomem ufności R= 95% znormalizowane odchylenie ( t-Kryterium studenta dla k
=
 )t
= 1,960.
)t
= 1,960.
Dostępne dane podstawiamy do wzoru:
Stąd granice przedziału ufności to  = 0,122–0,041 = 0,081 lub 8,1%;
= 0,122–0,041 = 0,081 lub 8,1%;  = 0,122 + 0,041 = 0,163 lub 16,3%.
= 0,122 + 0,041 = 0,163 lub 16,3%.
Zatem przy poziomie ufności 95% można stwierdzić, że całkowity odsetek porażonych nasion wynosi od 8,1 do 16,3%.
Przykład 3.4 . Współczynnik zmienności charakteryzujący zmienność wapnia (mg%) w surowicy krwi małp wyniósł 10,6%. Wielkość próbki n= 100. Konieczne jest wyznaczenie granic 95% przedziału ufności dla parametru ogólnego CV.
Granice ufności dla ogólnego współczynnika zmienności CV określają następujące wzory:
 oraz
oraz  , gdzie K
wartość pośrednia obliczona według wzoru
, gdzie K
wartość pośrednia obliczona według wzoru  .
.
Wiedząc to z poziomem pewności R= 95% znormalizowane odchylenie (test t-Studenta dla k
=
 )t
= 1.960, wstępnie oblicz wartość DO:
)t
= 1.960, wstępnie oblicz wartość DO:
 .
.
 lub 9,3%
lub 9,3%
 lub 12,3%
lub 12,3%
Zatem ogólny współczynnik zmienności z prawdopodobieństwem ufności 95% mieści się w zakresie od 9,3 do 12,3%. W przypadku powtarzanych próbek współczynnik zmienności nie przekroczy 12,3% i nie spadnie poniżej 9,3% w 95 przypadkach na 100.
Pytania do samokontroli:

Zadania do samodzielnego rozwiązania.
1. Średnia zawartość tłuszczu w mleku dla laktacji krów mieszańców Kholmogory wynosiła: 3,4; 3.6; 3.2; 3.1; 2,9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3,8; 3.4; 4.0; 3.3; 3.7; 3,5; 3.6; 3.4; 3.8. Ustaw przedziały ufności dla ogólnej średniej na poziomie ufności 95% (20 punktów).
2. Na 400 roślinach żyta mieszańcowego pierwsze kwiaty pojawiły się średnio 70,5 dnia po siewie. Odchylenie standardowe wyniosło 6,9 dnia. Określ błąd średniej i przedziałów ufności dla średniej populacji i wariancji na poziomie istotności W= 0,05 i W= 0,01 (25 punktów).
3. Badając długość liści 502 okazów truskawek ogrodowych uzyskano następujące dane:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm Określ przedziały ufności dla średniej arytmetycznej populacji z poziomami istotności 0,01; 0,02; 0,05. (25 punktów).
\u003d ± 0,06 cm Określ przedziały ufności dla średniej arytmetycznej populacji z poziomami istotności 0,01; 0,02; 0,05. (25 punktów).
4. Przy badaniu 150 dorosłych mężczyzn średni wzrost wynosił 167 cm, a σ \u003d 6 cm Jakie są granice ogólnej średniej i ogólnej wariancji z prawdopodobieństwem ufności 0,99 i 0,95? (25 punktów).
5. Dystrybucja wapnia w surowicy krwi małp charakteryzuje się następującymi selektywnymi wskaźnikami:
 = 11,94 mg%, σ
= 1,27, n
= 100. Wykreśl 95% przedział ufności dla średniej populacji tego rozkładu. Oblicz współczynnik zmienności (25 punktów).
= 11,94 mg%, σ
= 1,27, n
= 100. Wykreśl 95% przedział ufności dla średniej populacji tego rozkładu. Oblicz współczynnik zmienności (25 punktów).
6. Badano zawartość azotu całkowitego w osoczu krwi szczurów albinosów w wieku 37 i 180 dni. Wyniki wyrażono w gramach na 100 cm3 osocza. W wieku 37 dni 9 szczurów miało: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. W wieku 180 dni 8 szczurów miało: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1.13; 1.12. Ustaw przedziały ufności dla różnicy z poziomem ufności 0,95 (50 punktów).
7. Wyznaczyć granice 95% przedziału ufności dla ogólnej wariancji rozkładu wapnia (mg%) w surowicy krwi małp, jeżeli dla tego rozkładu wielkość próby n = 100, błąd statystyczny wariancji próby s σ 2 = 1,60 (40 punktów).
8. Wyznacz granice 95% przedziału ufności dla ogólnej wariancji rozkładu 40 kłosków pszenicy na długości (σ 2 = 40,87 mm 2). (25 punktów).
9. Palenie jest uważane za główny czynnik predysponujący do obturacyjnej choroby płuc. Bierne palenie nie jest uważane za taki czynnik. Naukowcy kwestionowali bezpieczeństwo biernego palenia i badali drogi oddechowe u osób niepalących, biernych i aktywnych palaczy. Aby scharakteryzować stan dróg oddechowych, przyjęliśmy jeden ze wskaźników funkcji oddychania zewnętrznego - maksymalną prędkość objętościową środka wydechu. Spadek tego wskaźnika jest oznaką upośledzonej drożności dróg oddechowych. Dane ankiety są pokazane w tabeli.
|
Liczba przebadanych |
Maksymalny przepływ w połowie wydechu, l/s |
||
|
Odchylenie standardowe |
|||
|
Niepalący |
|||
|
pracować w strefie dla niepalących | |||
|
pracować w zadymionym pomieszczeniu | |||
|
palacze |
|||
|
palenie niewielkiej ilości papierosów | |||
|
średnia liczba palaczy papierosów | |||
|
palenie dużej ilości papierosów | |||
Z tabeli znajdź 95% przedziały ufności dla ogólnej średniej i ogólnej wariancji dla każdej z grup. Jakie są różnice między grupami? Przedstaw wyniki w formie graficznej (25 punktów).
10. Wyznaczyć granice przedziałów ufności 95% i 99% dla ogólnej wariancji liczby prosiąt w 64 porodach, jeśli błąd statystyczny wariancji próbki s σ 2 = 8,25 (30 punktów).
11. Wiadomo, że średnia waga królików wynosi 2,1 kg. Określ granice przedziałów ufności 95% i 99% dla ogólnej średniej i wariancji, gdy n= 30, σ = 0,56 kg (25 punktów).
12. W 100 kłosach zmierzono zawartość ziarna w kłosie ( X), długość kolca ( Tak) i masa ziarna w kłosie ( Z). Znajdź przedziały ufności dla ogólnej średniej i wariancji dla P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 jeśli
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 punktów).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 punktów).
13. W losowo wybranych 100 kłosach pszenicy ozimej policzono liczbę kłosków. Próbka charakteryzowała się następującymi wskaźnikami:
 = 15 kłosków i σ = 2,28 szt. Określ dokładność, z jaką uzyskuje się średni wynik (
= 15 kłosków i σ = 2,28 szt. Określ dokładność, z jaką uzyskuje się średni wynik (  ) i wykreślić przedział ufności dla ogólnej średniej i wariancji na poziomach istotności 95% i 99% (30 punktów).
) i wykreślić przedział ufności dla ogólnej średniej i wariancji na poziomach istotności 95% i 99% (30 punktów).
14. Liczba żeber na muszlach skamieniałych mięczaków Ortabonity kaligramma:
Wiadomo, że n = 19, σ = 4,25. Określ granice przedziału ufności dla ogólnej średniej i ogólnej wariancji na poziomie istotności W = 0,01 (25 punktów).
15. W celu określenia wydajności mleka w towarowej fermie mlecznej określano produkcyjność 15 krów dziennie. Według danych rocznych każda krowa dawała średnio następującą ilość mleka na dzień (l): 22; 19; 25; 20; 27; 17; trzydzieści; 21; osiemnaście; 24; 26; 23; 25; 20; 24. Wykreślić przedziały ufności dla ogólnej wariancji i średniej arytmetycznej. Czy możemy oczekiwać, że średnia roczna wydajność mleka na krowę wyniesie 10 000 litrów? (50 punktów).
16. W celu określenia średniego plonu pszenicy w gospodarstwie koszenie przeprowadzono na powierzchniach próbnych o powierzchni 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 i 2 ha. Plon (c/ha) z poletek wyniósł 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 odpowiednio. Wykreśl przedziały ufności dla ogólnej wariancji i średniej arytmetycznej. Czy można oczekiwać, że średni plon dla przedsiębiorstwa rolnego wyniesie 42 c/ha? (50 punktów).
W statystyce istnieją dwa rodzaje oszacowań: punktowe i interwałowe. Oszacowanie punktowe to statystyka pojedynczej próby używana do oszacowania parametru populacji. Na przykład średnia próbki jest oszacowaniem punktowym średniej populacji i wariancji próby S2- punktowe oszacowanie wariancji populacji σ2. wykazano, że średnia z próby jest bezstronnym oszacowaniem oczekiwań populacji. Średnia próbki jest nazywana nieobciążoną, ponieważ średnia wszystkich średnich próbek (przy tej samej wielkości próbki) n) jest równa matematycznym oczekiwaniom populacji ogólnej.
Aby uzyskać wariancję próbki S2 stał się bezstronnym estymatorem wariancji populacji σ2, mianownik wariancji próby powinien być równy n – 1 , ale nie n. Innymi słowy, wariancja populacji jest średnią wszystkich możliwych wariancji próby.
Szacując parametry populacji należy pamiętać, że przykładowe statystyki, takie jak , zależy od konkretnych próbek. Aby wziąć ten fakt pod uwagę, uzyskać szacowanie interwału matematyczne oczekiwanie populacji ogólnej analizuje rozkład średnich z próby (więcej szczegółów, patrz). Skonstruowany przedział charakteryzuje się pewnym poziomem ufności, czyli prawdopodobieństwem prawidłowego oszacowania prawdziwego parametru populacji ogólnej. Podobne przedziały ufności można wykorzystać do oszacowania proporcji cechy R i główna rozproszona masa populacji ogólnej.
Pobierz notatkę w formacie lub formacie, przykłady w formacie
Konstrukcja przedziału ufności dla matematycznych oczekiwań populacji ogólnej o znanym odchyleniu standardowym
Budowanie przedziału ufności dla proporcji cechy w populacji ogólnej
W tej sekcji koncepcja przedziału ufności została rozszerzona na dane kategoryczne. Pozwala to oszacować udział cechy w populacji ogólnej R z próbnym udziałem RS= X/n. Jak wspomniano, jeśli wartości nR oraz n(1 - p) przekroczyć liczbę 5, rozkład dwumianowy może być aproksymowany przez normalny. Dlatego, aby oszacować udział cechy w populacji ogólnej R możliwe jest skonstruowanie przedziału, którego poziom ufności jest równy (1 - α)x100%.

gdzie pS- przykładowy udział cechy, równy X/n, tj. liczba sukcesów podzielona przez wielkość próby, R- udział cechy w populacji ogólnej, Z jest wartością krytyczną znormalizowanego rozkładu normalnego, n- wielkość próbki.
Przykład 3 Załóżmy, że z systemu informatycznego pobierana jest próbka składająca się ze 100 faktur wypełnionych w ciągu ostatniego miesiąca. Załóżmy, że 10 z tych faktur jest nieprawidłowych. W ten sposób, R= 10/100 = 0,1. Poziom ufności 95% odpowiada wartości krytycznej Z = 1,96.
Zatem istnieje 95% szansa, że od 4,12% do 15,88% faktur zawiera błędy.
Dla danej wielkości próby przedział ufności zawierający proporcję cechy w populacji ogólnej wydaje się być szerszy niż dla ciągłej zmiennej losowej. Wynika to z faktu, że pomiary ciągłej zmiennej losowej zawierają więcej informacji niż pomiary danych kategorycznych. Innymi słowy, dane kategoryczne, które przyjmują tylko dwie wartości, zawierają niewystarczające informacje do oszacowania parametrów ich rozkładu.
Wobliczanie szacunków na podstawie skończonej populacji
Szacowanie oczekiwań matematycznych. Współczynnik korygujący dla populacji końcowej ( fpc) zastosowano do zmniejszenia błędu standardowego o współczynnik . Przy obliczaniu przedziałów ufności dla oszacowań parametrów populacji stosuje się współczynnik korygujący w sytuacjach, gdy próbki są pobierane bez wymiany. Zatem przedział ufności dla oczekiwań matematycznych, mający poziom ufności równy (1 - α)x100%, oblicza się według wzoru:

Przykład 4 Aby zilustrować zastosowanie współczynnika korygującego dla skończonej populacji, wróćmy do problemu obliczania przedziału ufności dla średniej liczby faktur omówionej w powyższym przykładzie 3. Załóżmy, że firma wystawia 5000 faktur miesięcznie, a X= 110,27 USD, S= 28,95 USD N = 5000, n = 100, α = 0,05, t99 = 1,9842. Zgodnie ze wzorem (6) otrzymujemy:
Oszacowanie udziału cechy. Wybierając brak zwrotu, przedział ufności dla części cechy, która ma poziom ufności równy (1 - α)x100%, oblicza się według wzoru:

Przedziały ufności i kwestie etyczne
Podczas próbkowania populacji i formułowania wniosków statystycznych często pojawiają się problemy etyczne. Głównym z nich jest to, jak zgadzają się przedziały ufności i oszacowania punktowe statystyk próbki. Publikowanie szacunków punktowych bez określenia odpowiednich przedziałów ufności (zwykle na poziomie ufności 95%) oraz wielkości próby, z której zostały wyprowadzone, może być mylące. Może to dać użytkownikowi wrażenie, że oszacowanie punktowe jest dokładnie tym, czego potrzebuje, aby przewidzieć właściwości całej populacji. Dlatego należy zrozumieć, że w każdym badaniu na pierwszy plan należy stawiać nie punktowe, ale przedziałowe oszacowania. Ponadto należy zwrócić szczególną uwagę na prawidłowy dobór wielkości próbek.
Najczęściej przedmiotem manipulacji statystycznych są wyniki badań socjologicznych ludności w różnych kwestiach politycznych. Jednocześnie wyniki ankiety umieszczane są na pierwszych stronach gazet, a błąd doboru próby i metodologia analizy statystycznej są drukowane gdzieś pośrodku. Aby udowodnić słuszność otrzymanych oszacowań punktowych, należy wskazać liczebność próby, na podstawie której zostały one uzyskane, granice przedziału ufności oraz jego poziom istotności.
Następna uwaga
Wykorzystano materiały z książki Levin i wsp. Wykorzystano statystyki dla menedżerów. - M.: Williams, 2004. - s. 448–462
Centralne twierdzenie graniczne stwierdza, że przy odpowiednio dużej liczebności próby rozkład średnich w próbie można aproksymować rozkładem normalnym. Właściwość ta nie zależy od rodzaju rozmieszczenia ludności.
I inne Wszystkie są oszacowaniami ich teoretycznych odpowiedników, które można by uzyskać, gdyby nie próba, ale populacja ogólna. Niestety, ogólna populacja jest bardzo droga i często niedostępna.
Pojęcie estymacji przedziałowej
Każde oszacowanie próbki ma pewien rozrzut, ponieważ jest zmienną losową zależną od wartości w konkretnej próbie. Dlatego dla bardziej wiarygodnych wnioskowań statystycznych należy znać nie tylko oszacowanie punktowe, ale także przedział, który z dużym prawdopodobieństwem γ (gamma) obejmuje szacowany wskaźnik θ (theta).
Formalnie są to dwie takie wartości (statystyki) T1(X) oraz T2(X), Co T1< T 2 , dla którego przy danym poziomie prawdopodobieństwa γ warunek jest spełniony:
Krótko mówiąc, jest to prawdopodobne γ lub więcej rzeczywista wartość znajduje się między punktami T1(X) oraz T2(X), które nazywane są dolną i górną granicą przedział ufności.
Jednym z warunków konstruowania przedziałów ufności jest ich maksymalna wąska, tj. powinien być jak najkrótszy. Pożądanie jest całkiem naturalne, ponieważ. badacz stara się dokładniej zlokalizować znalezienie pożądanego parametru.
Wynika z tego, że przedział ufności powinien obejmować maksymalne prawdopodobieństwa rozkładu. a sam wynik będzie w centrum.
![]()
Oznacza to, że prawdopodobieństwo odchylenia (prawdziwego wskaźnika od oszacowania) w górę jest równe prawdopodobieństwu odchylenia w dół. Należy również zauważyć, że dla rozkładów skośnych przedział po prawej stronie nie jest równy przedziałowi po lewej stronie.
Powyższy rysunek wyraźnie pokazuje, że im wyższy poziom ufności, tym szerszy przedział - zależność bezpośrednia.
Było to małe wprowadzenie do teorii przedziałowej estymacji nieznanych parametrów. Przejdźmy do znalezienia granic ufności dla oczekiwań matematycznych.
Przedział ufności dla oczekiwań matematycznych
Jeśli oryginalne dane są rozłożone na , średnia będzie wartością normalną. Wynika to z zasady, że liniowa kombinacja wartości normalnych ma również rozkład normalny. Dlatego do obliczenia prawdopodobieństw możemy użyć aparatu matematycznego prawa rozkładu normalnego.
Będzie to jednak wymagało znajomości dwóch parametrów – wartości oczekiwanej i wariancji, które zwykle nie są znane. Można oczywiście użyć oszacowań zamiast parametrów (średnia arytmetyczna i ), ale wtedy rozkład średniej nie będzie całkiem normalny, będzie nieco spłaszczony. Obywatel Irlandii William Gosset zręcznie zauważył ten fakt, kiedy opublikował swoje odkrycie w wydaniu Biometrica z marca 1908 roku. W celu zachowania tajemnicy Gosset podpisał umowę ze Studentem. Tak pojawił się rozkład t-Studenta.
Jednak normalny rozkład danych, stosowany przez K. Gaussa w analizie błędów w obserwacjach astronomicznych, jest niezwykle rzadki w życiu naziemnym i jest dość trudny do ustalenia (dla wysokiej dokładności potrzeba około 2 tysięcy obserwacji). Dlatego najlepiej porzucić założenie o normalności i użyć metod, które nie zależą od rozkładu pierwotnych danych.
Powstaje pytanie: jaki jest rozkład średniej arytmetycznej, jeśli oblicza się ją z danych o nieznanym rozkładzie? Odpowiedzi udziela dobrze znana teoria prawdopodobieństwa Centralne twierdzenie graniczne(CPT). W matematyce istnieje kilka jej wersji (sformułowania były przez lata udoskonalane), ale wszystkie z grubsza sprowadzają się do stwierdzenia, że suma dużej liczby niezależnych zmiennych losowych jest zgodna z prawem rozkładu normalnego.
Przy obliczaniu średniej arytmetycznej wykorzystuje się sumę zmiennych losowych. Z tego wynika, że średnia arytmetyczna ma rozkład normalny, w którym wartość oczekiwana jest wartością oczekiwaną danych początkowych, a wariancja wynosi .
Mądrzy ludzie wiedzą, jak udowodnić CLT, ale zweryfikujemy to za pomocą eksperymentu przeprowadzonego w Excelu. Zasymulujmy próbkę 50 zmiennych losowych o rozkładzie jednostajnym (za pomocą funkcji Excela RANDOMBETWEEN). Następnie zrobimy 1000 takich próbek i obliczymy dla każdej średnią arytmetyczną. Przyjrzyjmy się ich dystrybucji.

Widać, że rozkład średniej jest zbliżony do normalnego prawa. Jeśli objętość próbek i ich liczba będą jeszcze większe, podobieństwo będzie jeszcze lepsze.
Teraz, gdy sami przekonaliśmy się o poprawności CLT, możemy, używając , obliczyć przedziały ufności dla średniej arytmetycznej, które pokrywają rzeczywistą średnią lub oczekiwanie matematyczne z określonym prawdopodobieństwem.
Aby ustalić górną i dolną granicę, wymagana jest znajomość parametrów rozkładu normalnego. Z reguły nie są, dlatego stosuje się szacunki: Średnia arytmetyczna oraz wariancja próbki. Ponownie, ta metoda daje dobre przybliżenie tylko dla dużych próbek. Gdy próbki są małe, często zaleca się użycie rozkładu Studenta. Nie wierz! Rozkład Studenta dla średniej występuje tylko wtedy, gdy oryginalne dane mają rozkład normalny, czyli prawie nigdy. Dlatego lepiej od razu ustawić minimalną poprzeczkę dla ilości wymaganych danych i stosować metody asymptotycznie poprawne. Mówią, że 30 obserwacji wystarczy. Weź 50 - nie możesz się pomylić.
![]()
T 1,2 to dolna i górna granica przedziału ufności
– przykładowa średnia arytmetyczna
s0– odchylenie standardowe próbki (nieobciążone)
n - wielkość próbki
γ – poziom ufności (zwykle równy 0,9, 0,95 lub 0,99)
c γ =Φ -1 ((1+γ)/2) jest odwrotnością standardowej funkcji rozkładu normalnego. Mówiąc prościej, jest to liczba błędów standardowych od średniej arytmetycznej do dolnej lub górnej granicy (wskazane trzy prawdopodobieństwa odpowiadają wartościom 1,64, 1,96 i 2,58).
Istotą wzoru jest to, że bierze się średnią arytmetyczną, a następnie odkłada się od niej pewną kwotę ( z γ) błędy standardowe ( s 0 /√n). Wszystko wiadomo, weź to i policz.
Przed masowym użyciem komputerów PC, aby uzyskać wartości funkcji rozkładu normalnego i jego odwrotności, używano . Są nadal używane, ale bardziej efektywne jest przejście do gotowych formuł Excela. Wszystkie elementy z powyższego wzoru ( i ) można łatwo obliczyć w programie Excel. Ale jest też gotowa formuła obliczania przedziału ufności - NORMA ZAUFANIA. Jego składnia jest następująca.
NORMA UFNOŚCI (alfa, odchylenie_standardowe, rozmiar)
alfa– poziom istotności lub poziom ufności, który w powyższym zapisie jest równy 1-γ, tj. prawdopodobieństwo, że matematyczneoczekiwanie będzie poza przedziałem ufności. Przy poziomie ufności 0,95 alfa wynosi 0,05 i tak dalej.
standard_off to odchylenie standardowe danych próbki. Nie musisz obliczać błędu standardowego, Excel podzieli przez pierwiastek n.
Rozmiar– wielkość próbki (n).
Wynikiem funkcji UFNOŚĆ.NORM jest drugi wyraz ze wzoru na obliczenie przedziału ufności, tj. pół interwału. Odpowiednio dolny i górny punkt to średnia ± uzyskana wartość.
Dzięki temu możliwe jest zbudowanie uniwersalnego algorytmu obliczania przedziałów ufności dla średniej arytmetycznej, która nie zależy od rozkładu danych początkowych. Ceną za uniwersalność jest jej asymptotyczny charakter, czyli konieczność użycia stosunkowo dużych próbek. Jednak w dobie nowoczesnych technologii zebranie odpowiedniej ilości danych zwykle nie jest trudne.
Testowanie hipotez statystycznych przy użyciu przedziału ufności
(moduł 111)
Jednym z głównych problemów rozwiązywanych w statystykach jest. Krótko mówiąc, jego istotą jest to. Zakłada się na przykład, że oczekiwania ogółu populacji są równe pewnej wartości. Następnie konstruowany jest rozkład średnich z próby, który można zaobserwować przy danym oczekiwaniu. Następnie przyjrzymy się, gdzie w tym rozkładzie warunkowym znajduje się średnia rzeczywista. Jeśli przekracza dopuszczalne granice, pojawienie się takiej średniej jest bardzo mało prawdopodobne, a przy jednym powtórzeniu eksperymentu jest prawie niemożliwe, co jest sprzeczne z postawioną hipotezą, którą z powodzeniem odrzuca się. Jeżeli średnia nie przekracza poziomu krytycznego, to hipoteza nie jest odrzucana (ale też nie jest udowodniona!).
Tak więc za pomocą przedziałów ufności, w naszym przypadku dla wartości oczekiwanych, można również przetestować niektóre hipotezy. To bardzo proste. Załóżmy, że średnia arytmetyczna dla pewnej próbki wynosi 100. Testowana jest hipoteza, że oczekiwana wartość wynosi powiedzmy 90. To znaczy, jeśli postawimy pytanie prymitywnie, brzmi ono tak: czy może być tak przy prawdziwej wartości średnia równa 90, obserwowana średnia to 100?
Aby odpowiedzieć na to pytanie, wymagane będą dodatkowe informacje dotyczące odchylenia standardowego i wielkości próby. Powiedzmy, że odchylenie standardowe wynosi 30, a liczba obserwacji to 64 (aby łatwo wyodrębnić pierwiastek). Wtedy błąd standardowy średniej wynosi 30/8 lub 3,75. Aby obliczyć 95% przedział ufności, będziesz musiał odłożyć dwa błędy standardowe po obu stronach średniej (dokładniej 1,96). Przedział ufności będzie wynosił około 100 ± 7,5 lub od 92,5 do 107,5.
Dalsze rozumowanie jest następujące. Jeżeli badana wartość mieści się w przedziale ufności, to nie jest to sprzeczne z hipotezą, ponieważ mieści się w granicach wahań losowych (z prawdopodobieństwem 95%). Jeżeli badany punkt znajduje się poza przedziałem ufności, to prawdopodobieństwo takiego zdarzenia jest bardzo małe, w każdym razie poniżej akceptowalnego poziomu. Stąd hipoteza jest odrzucana jako sprzeczna z obserwowanymi danymi. W naszym przypadku hipoteza oczekiwana znajduje się poza przedziałem ufności (testowana wartość 90 nie jest zawarta w przedziale 100±7,5), dlatego należy ją odrzucić. Odpowiadając na powyższe prymitywne pytanie, należy powiedzieć: nie, nie może, w każdym razie zdarza się to niezwykle rzadko. Często wskazuje to na określone prawdopodobieństwo błędnego odrzucenia hipotezy (poziom p), a nie na dany poziom, według którego zbudowano przedział ufności, ale o tym innym razem.
Jak widać, zbudowanie przedziału ufności dla średniej (lub oczekiwań matematycznych) nie jest trudne. Najważniejsze jest, aby złapać esencję, a potem wszystko pójdzie. W praktyce większość korzysta z 95% przedziału ufności, który wynosi około dwóch błędów standardowych po obu stronach średniej.
To wszystko na teraz. Wszystkiego najlepszego!