Konwersja wymiany danych pomiędzy rozwiązaniami aplikacyjnymi. Instrukcja wideo do konwersji
1. Wstęp.
2. Czego potrzebujesz: Konfiguracja 1C: Konwersja danych 2. * i przetwarzanie z pakietu. Jako przykład zadań bierzemy konfiguracje 1C: Trade Management 11 i 1C: BP 3.*.
Tak więc, aby opracować zasady przesyłania danych do 1C, będziesz potrzebować konfiguracji 1C: Konwersja obiektu 2, a także przetwarzania zawartego w pakiecie.
Na przykład wdrożyliśmy już bazę konwersji i ją uruchomiliśmy.
Napiszemy opracowanie zasad wymiany między konfiguracją 1C: Trade Management 11 i 1C: Enterprise Accounting 3 (reguły wymiany UT / BUH).
3. Będziemy potrzebować Przetwarzania, aby rozładować strukturę metadanych i wymianę.
Pierwszą rzeczą, którą musisz zdobyć do programowania, są pliki ze strukturą metadanych. Odbywa się to za pomocą przetwarzania rozładowującego strukturę metadanych zawartego w pakiecie konwersji obiektów.

Właściwie w rozpakowanym katalogu konfiguracyjnym dla konfiguracji na zarządzanych formularzach jesteśmy zainteresowani przetwarzaniem MD83Exp.epf. Jeśli rozładunek trzeba wykonać z konfiguracji na zwykłych formularzach, stosuje się przetwarzanie MD82Exp.epf. Dzieje się tak, jeśli na przykład potrzebujesz uzyskać strukturę z takich konfiguracji jak 1C: UT 10, 1C: Manufacturing Enterprise Management 1.3, 1C: Integrated Automation 1.1, 1C: Zup 2.5 i tak dalej.
Ponadto, aby przesyłać i pobierać dane w 1C przy użyciu naszych reguł, będziesz potrzebować przetwarzania „Uniwersalnej wymiany danych w formacie XML” V8Exchan83.epf dla konfiguracji w zarządzanych formularzach, takich jak 1C: Trade Management 11. *, 1C BP 3, 1C : ERP 2. * i tym podobne. I odpowiednio V8Exchan83.epf - dla konfiguracji na zwykłych formularzach.
4. Przesyłanie struktury metadanych konfiguracji 1C: Trade Management 11.3 i 1C: Enterprise Accounting 3.0.*
Zacznijmy od usunięcia struktury metadanych z konfiguracji 1C: Enterprise Accounting 3.
Otwórz przetwarzanie MD83Exp.epf

W formularzu przetwarzania znajdują się dodatkowe ustawienia, w których możemy włączyć lub wyłączyć opcję rozładowywania rejestrów i ruchów w 1C. Istnieje również możliwość wyboru miejsca rozładunku: na serwerze 1C lub „na kliencie”. Podaj nazwę pliku, z którego zostanie wyładowana struktura danych. Podobnie odciążamy strukturę metadanych konfiguracji Trade Management 11.
Teraz musisz załadować konfigurację do bazy danych konwersji. Do tej pozycji można dotrzeć zarówno z listy konfiguracji, jak i z listy konwersji. Po prostu uruchommy z pulpitu:

W oknie dialogowym wczytaj strukturę BP: 
I podobnie - struktura Departamentu Handlu. 
Po zakończeniu pobierania pojawi się okno dialogowe, w którym możesz określić dogodną dla siebie nazwę. 

6. Tworzenie reguł konwersji w 1C na konkretnym przykładzie zadania.
Następnie przejdź do „Ustawianie reguł obiektu”, gdzie tworzymy nowe ustawienie.
W oknie dialogowym tworzenia konwersji wybierz konfigurację „źródłową” i konfigurację „docelową” (którą wcześniej załadowałeś) i kliknij OK.

Ponieważ w tym artykule planowałem pokazać kreację „od zera” i „bez śmieci”, przypominam, że nie tworzymy niczego automatycznie. Brak prototypów.

Nic nie zrobimy w tym oknie dialogowym, wystarczy kliknąć - "Zamknij".
Stwórzmy reguły rozładowywania nie jednego dokumentu do jednego, ale jednego typu do drugiego, na przykład dokument Sprzedaż towarów i usług z UT 11 z niezbędnymi katalogami do dokumentu Przyjęcie towarów i usług w BP 3.
Tworzymy więc nowe PKO (reguła konwersji obiektów na 1C)

Wybierz źródło Realizacji Towarów Usług oraz odbiorcę Przyjęcia Towarów Usług i kliknij OK.
W takim przypadku pojawi się okno dialogowe, w którym ponownie odmówimy automatycznego tworzenia PKC (Reguły konwersji właściwości). Następnie wybieramy tylko niezbędne.

Ale na propozycję stworzenia PVD (zasad przesyłania danych) odpowiadamy „Tak”.


Tworzone są VDP, co znajdzie odzwierciedlenie w przetwarzaniu uniwersalnej wymiany XML do wyboru:

Zostaną również utworzone reguły konwersji danych z pustymi regułami konwersji właściwości.

Ponadto jasne jest, że domyślnie proponuje się wyszukiwanie FSP według wewnętrznego identyfikatora obiektu. Wskazuje na to lupa w pobliżu PKO. Zrobimy własne wyszukiwanie i zrobimy to po numerze dokumentu i dacie na początku dnia.
Usuwanie wyszukiwania UIO:

Teraz zacznijmy dopasowywać niezbędne właściwości (rekwizyty) obiektu. Aby to zrobić, kliknij „Synchronizacja właściwości” (etykieta „1” na ekranie). Usuwamy rekurencyjne tworzenie reguł („2”). Usuwamy wszystkie zaznaczone szczegóły („3”). I sami wybierzemy to, czego potrzebujemy.

Na przykład wybierz to, czego potrzebujesz:

Zwracam uwagę na to, że PKS kontrahenta uczynimy organizacją, a organizację kontrahentem, a także porównamy niektóre szczegóły, które nie pasują do nazwy, na przykład „Waluta” i „Dokument waluta".


Gdzie widzimy, że nie ma jeszcze reguł konwersji.
Zacznijmy od szczegółów, aby przejść i opisać. Najpierw ustawiamy wyszukiwanie dokumentu tak jak pisałem wcześniej, rozładujemy i szukamy dokumentu na początku daty i zmienimy numerację. Zastąpimy pierwsze trzy znaki naszym prefiksem „UTB”. A ponieważ w BP i UT numeracja ma po 11 znaków, tworzymy liczbę złożoną: nasz prefiks i 8 znaków ze źródła. Przykładowy zrzut ekranu poniżej.

Zawsze rozładowujemy dokumenty, które nie zostały wykonane i bez ruchu. Zakładamy, że dokumenty będą przechowywane w odbiorniku po sprawdzeniu przez użytkownika.
Aby to zrobić, PCS, po ustaleniu, jak nie jest wstrzymane, 0 lub 1, jest używany jako wartość logiczna.

Na przykładzie waluty tworzymy regułę konwersji obiektu na PCS. Jednocześnie uważamy, że w obu bazach znajdują się waluty i muszą być zsynchronizowane kodem. Dlatego nie stworzymy wszystkich PCS w CSP walut, a jedynie dodamy Kod do wyszukiwania. Tych. z propozycji stworzenia PCS dla obiektu - odmawiamy.

Utworzona reguła konwersji została zastąpiona w PQS dokumentu SCS. A sama reguła domyślna jest oferowana przez unikalny identyfikator. Naprawiamy to, szukamy w kodzie i ustawiamy właściwość tak, aby nie tworzyć nowego obiektu.
W rezultacie otrzymujemy opcję:

Dalej analogicznie tworzymy dla reszty szczegóły PKO i PKS. Ponadto ustalamy wyszukiwanie organizacji według kontrahenta i odwrotnie według TIN. Tak to wygląda z minimalnymi szczegółami (w razie potrzeby możesz dodać).

W przypadku Umów PKO kontrahentów wyszukujemy Kontrahenta PKS, nazwę i właściciela.

Zobaczmy, jak określić żądaną wartość w typie wyliczenia w PCS. Na przykład atrybut „Typ operacji”. Tutaj możesz użyć różnych warunków i wartości zastępczych. Na przykład potrzebujemy, aby „rodzaj operacji” zawsze był rozładowywany „Towary”, w tym przypadku wystarczy wpisać żądaną wartość w „czole” jako ciąg.

Poniżej pokazano, jak ustawić bez trudności i w większości przypadków PKS dla krotności rozliczenia, stopy rozliczenia, kont.

Dla Nomenklatury PKO pozostawiamy wyszukiwanie po wewnętrznym unikalnym identyfikatorze. Ale zwrócę uwagę na to, jak możesz przedefiniować swoją grupę. Na przykład zgadzamy się, że nowa nomenklatura zostanie usunięta z konfiguracji 1C: Trade Management 11, ale konieczne jest, aby nomenklatura była zebrana w określonej grupie „NaszaGrupa”.

Aby zrealizować to zadanie, tworzymy kolejne PKO. Nazwijmy to „Nomenklaturą nadrzędną”, którą wskażemy w PDN rodzica w regule konwersji.
Ustawiamy dwa wyszukiwania: według nazwy, gdzie nazwa naszej grupy jest zakodowana na stałe, oraz obowiązkową właściwość atrybutu „ThisGroup” na wartość true.

Ponieważ zdecydowaliśmy, że cała nomenklatura należy do naszej grupy, nie ma potrzeby wyładowywania grup z UT 11. W tym celu w Nomenklaturze PKO, w module obsługi zdarzeń „Before Unloading” umieścimy filtr, który nie ma potrzeby wyładowywania grup „Awaria = Źródło. Ta grupa;”.

W DRP (reguły przesyłania danych) Wdrażanie towarów i usług dodamy filtr, aby dokumenty oznaczone do usunięcia nie były wgrywane. W tym celu w PDP w obsłudze zdarzeń „BeforeUnloading” napiszemy filtr „Rejection = Object.DeletionMark;”.

Zapisz opracowane reguły do pliku.

7. Podsumowanie: Przesyłanie i pobieranie danych z wykorzystaniem opracowanych reguł wymiany danych.
Otwieramy w 1C: Trade Management 11 przetwarzanie „Uniwersalna wymiana danych w formacie XML” V8Exchan83.epf. 
Rozładunek minął, teraz z tym samym przetwarzaniem ładujemy do 1C: Enterprise Accounting 3.


Pobieranie zakończone. Sprawdźmy, czy jest załadowany. Czyli dokument jest wczytany tak, jak chcieliśmy - mamy Organizację wczytaną do kontrahenta, a kontrahent do organizacji. Wszystkie konta są pobierane i instalowane. Otrzymaliśmy numer dokumentu z naszym prefiksem i na początku dnia. Wszystkie dane, które zostały zarejestrowane, zostały wypełnione.

Sprawdzamy ładowanie nomenklatury. Widzimy, że wszystko potoczyło się tak, jak planowaliśmy.


Stworzyliśmy i uzupełniliśmy szczegóły zgodnie z zamierzeniami. W konwersji jest wiele subtelności i kilka prostych, ale niezbędnych rzeczy, które pomagają dokładnie napisać konwersję. A to pozwala zminimalizować błędy, nie psuć istniejących danych i pozbyć się niepotrzebnych śmieci. To jeden z najprostszych przykładów. Możesz także dokonać konwersji jednego obiektu na wiele lub odwrotnie, wielu - na jeden.
Teraz jest konwersja danych 3, rozwiązuje inne problemy. Dlatego potrzebna jest również konwersja 2. Powodzenia wszystkim w nauce i opanowaniu.
Oczywiście, jeśli jesteś programistą i to jest Twoja główna praca, możesz spróbować samodzielnie napisać konwersję. Ale jeśli nie, to powinieneś cenić swój czas w swojej dziedzinie działalności i poprosić profesjonalistów o wykonanie tego zadania.
1C:Enterprise 8. Konwersja danych: wymiana danych między aplikacjami (z aplikacją na CD-ROM) (artykuł 4601546049094)
„1C:Enterprise” to uniwersalny system do automatyzacji działań przedsiębiorstwa i może być używany do rozwiązywania różnych problemów związanych z zarządzaniem i księgowością. Obecnie na platformie 1C:Enterprise opracowano wiele standardowych i specjalistycznych rozwiązań, które mogą działać w ścisłej integracji z innymi rozwiązaniami, zarówno na tej platformie, jak i z oprogramowaniem innych firm.
Ogromne znaczenie dla efektywnej pracy ma umiejętność organizowania wymiany pomiędzy różnymi systemami informatycznymi. Platforma 1C:Enterprise zapewnia różnorodne narzędzia do wymiany danych i integracji rozwiązań aplikacyjnych.
Książka szczegółowo opisuje wymianę danych w formacie XML, który jest obecnie powszechnie akceptowanym sposobem przedstawiania danych. Opisano procedury opracowywania reguł, których zastosowanie zapewni transfer informacji z jednego systemu informacyjnego do drugiego, w tym wymianę danych między typowymi konfiguracjami 1C:Enterprise.
Do książki dołączona jest płyta CD zawierająca demonstracyjne bazy informacyjne z przykładami reguł wymiany oraz konfiguracją "1C:Enterprise. Data Conversion".
Uwaga! W pierwszym wydaniu dopuszczono techniczny mariaż na końcu książki. Poprawione strony mogą być
Obecnie resztki małżeństwa są wycofane ze sprzedaży i ukazała się poprawiona edycja.
Przepraszamy za powstałe niedogodności i jesteśmy gotowi bezpłatnie wymienić wadliwe egzemplarze dla chętnych.
Pytania dotyczące literatury wydawnictwa „1C-Publishing” można przesyłać na adres [e-mail chroniony].
Kup:
Skontaktuj się z partnerem 1C obsługującym Twoją organizację i złóż zamówienie, podając mu kod przypisany do książki (pokazany w poniższej tabeli). Możesz także kupić książkę od innych. partnerzy firmy „1C”.
- w sklepie internetowym „1C-Interest” (dostawa książek kurierem, Poczta Rosyjska, DHL, EMS)
- w księgarniach w Twoim mieście
Zobacz też:
cena książki
| Kod | Nazwa | Zalecana cena detaliczna, rub. * | Kupiec | Stały partner | Dystrybutor |
| 4601546049094 | 1C:Enterprise 8. Konwersja danych: wymiana danych między aplikacjami (z aplikacją na CD-ROM) (artykuł 4601546049094) | 240 | 150 | 135 | 120 |
struktura książki
Wstęp
Rozdział 1. Ogólne zasady ustanawiania reguł
Rozdział 2 Korzystanie z reguł
Rozdział 3 Automatyczne generowanie reguł
Rozdział 4 Struktura reguły
Rozdział 5
Rozdział 6 Programy obsługi zdarzeń
- Opcje
- Moduły obsługi „konwersji”
- Moduły obsługi „reguł przesyłania danych”
- Programy obsługi „Reguły konwersji obiektów”
- Moduły obsługi „Reguły konwersji grupy nieruchomości”
- Moduły obsługi „Reguły konwersji nieruchomości”
Rozdział 7 Pola wyszukiwania
Rozdział 8. Zasady czyszczenia danych
Rozdział 9 Algorytmy i zapytania
Rozdział 10. Typowe przykłady reguł. Obejścia
- Konwersja wyliczenia
- Konwersja katalogów
- Konwersja dokumentów
- Konwersja rejestru informacji
- Konwersja planu kont
- Konwersja planu charakterystycznych typów
- Konwersja planu typu kalkulacji
- Stała konwersja 1C: Przedsiębiorstwo 7,7
- 1C: Konwersja transakcji księgowych Enterprise 7.7
Rozdział 11 Zasady optymalizacji
- Zasady przesyłania danych
- Zasady konwersji obiektów
- Przetwarzanie "Uniwersalnej wymiany danych XML"
Konwersja danych 2.0 i 2.1 to konfiguracja technologiczna 1C zaimplementowana na wersjach platformy od 8.1 do 8.3.
Głównym zadaniem narzędzia jest pisanie reguł wymiany między rozwiązaniami aplikacyjnymi 1C 8 i 7. Obecna wersja konwersji danych to dziś 3.0.
Konwersja danych jest bardzo przydatną konfiguracją, dzięki której można rozwiązać nie tylko kwestię przenoszenia informacji z jednej infobazy do drugiej, ale także np. konwertować informacje w ramach jednej bazy danych.
Konfiguracja jest bardzo wygodna w użyciu, gdy .
Konwersja danych przyda się każdemu programiście: posiadanie umiejętności tworzenia reguł wymiany to poważny plus dla umiejętności zawodowych.
Do nauki pracy z konfiguracją najlepiej nadaje się rozwiązywanie praktycznych problemów. Spróbuj wymyślić zadania dla siebie, na przykład: przenieś dowolne informacje z jednej bazy danych do drugiej, przekształć dokument wdrożeniowy w dokument paragonu, „przenieś” bieżące salda księgowe do dokumentu „wpis salda” i inne zadania.
Bardzo przydatne będzie zrozumienie „typowych” zasad wymiany 1C 8.3, często można tam znaleźć ciekawe przykłady realizacji zadań.
Aby zrozumieć podstawy, będziesz potrzebować materiałów, rozważ je poniżej.
Instrukcja wideo do konwersji
Aby zapoznać się z podstawami konfigurowania wymiany danych w 1C przy użyciu konfiguracji „1C Data Conversion”, zobacz przykład wideo:
Materiały, podręczniki do nauki 1C Data Conversion 2.0
W sieci nie ma zbyt wielu materiałów i dokumentacji, starałem się zebrać najważniejsze i najciekawsze materiały:
0. Przede wszystkim radzę bezpłatny kurs wideo Ilyi Leontiev, jest dostępny pod adresem połączyć.
1. Radziłbym przede wszystkim skorzystać z wbudowanej pomocy w konfiguracji. Jest naprawdę dobrze napisany i dobrze zaimplementowany technicznie:

2. Drugim najważniejszym źródłem informacji jest strona http://www.mykod.info/ (strona została zamknięta), specjalizująca się właśnie w konwersji danych. Tam możesz pobrać dużą liczbę materiałów do konwersji.
3. Osobno chciałbym podkreślić podręcznik szkoleniowy podręcznika - (autor - Olga Kuznetsova).
Migracja danych między różnymi konfiguracjami nie jest prostym zadaniem. Jak zawsze rozwiązań jest kilka, ale nie wszystkie są optymalne. Spróbujmy zrozumieć niuanse przesyłania danych i wybrać uniwersalną strategię rozwiązywania takich problemów.
Problem migracji danych (dotyczy to wyłącznie produktów firmy 1C) z jednego rozwiązania do drugiego nie pojawił się wczoraj. Firma 1C doskonale zdaje sobie sprawę z trudności, z jakimi borykają się programiści podczas tworzenia migracji, dlatego stara się jak najlepiej pomóc z narzędziami.
W trakcie rozwoju platformy firma wprowadziła szereg uniwersalnych narzędzi, a także technologie ułatwiające przesyłanie danych. Są one wbudowane we wszystkie standardowe rozwiązania, a problem migracji między identycznymi konfiguracjami został generalnie rozwiązany. Zwycięstwo po raz kolejny potwierdza ścisła integracja standardowych rozwiązań.
Przy migracjach pomiędzy niestandardowymi rozwiązaniami sytuacja nieco się komplikuje. Szeroka gama technologii pozwala programistom samodzielnie wybrać najlepszy z ich punktu widzenia sposób rozwiązania problemu.
Rozważmy niektóre z nich:
- wymiana za pośrednictwem plików tekstowych;
- korzystanie z planów wymiany;
- itp.
Każdy z nich ma swoje plusy i minusy. Podsumowując, główną wadą będzie gadatliwość. Niezależna implementacja algorytmów migracji jest obarczona znacznymi kosztami czasu, a także długim procesem debugowania. Nie chcę nawet mówić o dalszym wspieraniu takich decyzji.
Złożoność i wysokie koszty utrzymania skłoniły firmę 1C do stworzenia uniwersalnego rozwiązania. Technologia, która pozwala maksymalnie uprościć rozwój i obsługę migracji. W efekcie pomysł został wdrożony w postaci osobnej konfiguracji – „Konwersja danych”.

Konwersja danych - rozwiązanie standardowe, samokonfiguracja. Każdy użytkownik posiadający subskrypcję ITS:Prof może pobrać ten pakiet całkowicie bezpłatnie ze strony wsparcia użytkownika lub z dysku ITS. Instalacja odbywa się w standardowy sposób - podobnie jak wszystkie inne standardowe rozwiązania od 1C.
Teraz trochę o zaletach rozwiązania. Zacznijmy od najważniejszego – wszechstronności. Rozwiązanie nie jest dostosowane do niektórych konfiguracji/wersji platformy. Działa równie dobrze zarówno ze standardowymi konfiguracjami, jak i samodzielnie napisanymi. Deweloperzy otrzymują uniwersalną technologię i ustandaryzowane podejście do tworzenia nowych migracji. Wszechstronność rozwiązania pozwala na przygotowanie migracji nawet na inne platformy niż 1C:Enterprise.
Drugim pogrubionym plusem są pomoce wizualne. Proste migracje są tworzone bez programowania. Tak, tak, bez jednej linijki kodu! Tylko dla tego warto poświęcić czas na nauczenie się technologii raz, a potem wielokrotnie korzystać z bezcennych umiejętności.
Trzecią zaletą, na którą chciałbym zwrócić uwagę, jest brak ograniczeń w dystrybucji danych. Deweloper sam wybiera sposób dostarczenia danych do konfiguracji odbiornika. Dostępne są dwie opcje: przesłanie do pliku xml i bezpośrednie połączenie z bazą danych (COM/OLE).
Architektura uczenia się
Wiemy już, że konwersja danych może zdziałać cuda, ale nie jest jeszcze jasne, jakie są zalety techniczne. Pierwszą rzeczą, której należy się nauczyć, jest to, że każda migracja danych (konwersja) opiera się na regułach wymiany. Reguły giełdy - zwykły plik xml z opisem struktury, do której będą wgrywane dane z IB. Przetwarzanie usługi, która dokonuje wgrywania/pobierania danych, analizuje reguły giełdy i na ich podstawie wykonuje wgrywanie. Podczas pobierania następuje proces odwrotny.
Konfiguracja „KD” to rodzaj wizualnego konstruktora, za pomocą którego programista tworzy reguły wymiany. Nie wie, jak przesłać dane. Odpowiada za to dodatkowe przetwarzanie usług zewnętrznych zawarte w pakiecie dystrybucyjnym CD. Jest ich kilka (XX w nazwie pliku to numer wersji platformy):
- MDXXExp.epf- przetwarzanie umożliwia wgranie opisu struktury infobazy do pliku xml. Opis struktury jest ładowany na CD w celu dalszej analizy i tworzenia reguł wymiany.
- V8ExchanXX.epf- wgrywa/pobiera dane z infobazy zgodnie z regulaminem giełdy. W większości typowych konfiguracji przetwarzanie jest dostępne po wyjęciu z pudełka (patrz pozycja menu „Serwis”). Przetwarzanie jest uniwersalne i nie jest związane z żadnymi konkretnymi konfiguracjami/regułami.
OK, teraz w oparciu o powyższe, zdefiniujmy etapy tworzenia nowej konwersji:
- Definicja zadania. Konieczne jest jasne zrozumienie, jakie dane należy przesłać (z jakich obiektów konfiguracyjnych) i, co najważniejsze, gdzie je przesłać.
- Przygotowanie opisu struktur konfiguracyjnych (Source/Receiver) do późniejszego załadowania na płytę CD. Zadanie rozwiązuje przetwarzanie usługi MDXXExp.epf.
- Ładowanie przygotowanych opisów konstrukcji w IS.
- Tworzenie reguł wymiany z wykorzystaniem wizualnych środków CD.
- Przesyłanie/pobieranie zgodnie z utworzonymi regułami konwersji danych przy użyciu przetwarzania V8ExchanXX.epf.
- Debugowanie reguł wymiany (jeśli to konieczne).

Najprostsza konwersja
Do demonstracji potrzebujemy dwóch wdrożonych konfiguracji. Postanowiłem poprzestać na opcji: „Zarządzanie handlem” 10. edycja i małe, własnoręcznie napisane rozwiązanie. Zadaniem będzie przeniesienie danych z typowej konfiguracji UT. Dla zwięzłości napisane rozwiązanie będziemy nazywać „Odbiorcą”, a zarządzanie handlem „Źródłem”. Zacznijmy rozwiązywanie problemu od przeniesienia elementów katalogu „Nomenklatura”.
Przede wszystkim przyjrzyjmy się schematowi konwersji danych i ponownie przeczytajmy listę czynności, które należy wykonać. Następnie uruchamiamy konfigurację „Źródło” i otwieramy w niej przetwarzanie usługi MD82Exp.epf.
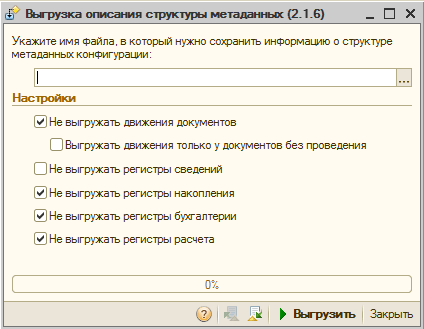
Interfejs przetwarzania nie świeci z dużą ilością ustawień. Użytkownik musi jedynie określić typy obiektów metadanych, które nie będą mieściły się w opisie struktury. W większości przypadków tych ustawień nie trzeba zmieniać, ponieważ w rejestrach akumulacyjnych nie ma szczególnego punktu w ruchach rozładunkowych (jako przykład).
Bardziej poprawne jest formowanie ruchu podczas trzymania dokumentów w odbiorniku. Wszystkie ruchy zostaną wykonane przez sam dokument po przeniesieniu. Drugim argumentem w obronie ustawień domyślnych jest zmniejszenie rozmiaru przesyłanego pliku.
Niektóre dokumenty (szczególnie w typowych konfiguracjach) tworzą ruchy w wielu rejestrach. Wyładowanie całej tej ekonomii spowoduje, że wynikowy plik XML będzie zbyt duży. Może to utrudnić późniejszy transport i załadunek do podstawy odbiornika. Im większy plik danych, tym więcej pamięci RAM jest potrzebne do jego przetworzenia. Podczas mojej praktyki zdarzyło mi się napotkać nieprzyzwoicie duże pliki do przesyłania. Takie pliki całkowicie odmówiły przeanalizowania standardowymi środkami.
Pozostawiamy więc wszystkie ustawienia domyślne i wgrywamy opis konfiguracji do pliku. Tę samą procedurę powtarzamy dla drugiej bazy.

Otwórz płytę CD i wybierz z menu głównego „Katalogi” -> „Konfiguracje”. Katalog przechowuje opisy struktur wszystkich konfiguracji, których można użyć do tworzenia konwersji. Opis konfiguracji ładujemy raz, a następnie możemy go wielokrotnie używać do tworzenia różnych konwersji.

W oknie katalogu naciśnij przycisk „ Dodać” iw wyświetlonym oknie wybierz plik z opisem konfiguracji. Zaznacz pole „Prześlij do nowej konfiguracji” i kliknij przycisk „Przeprowadź przesyłanie”. Podobne czynności wykonujemy z opisem struktury drugiej konfiguracji.

Teraz wszystko jest gotowe do stworzenia reguł wymiany. W menu głównym CD wybierz „Referencje” -> „Konwersje”. Dodanie nowego elementu. W oknie tworzenia nowej konwersji należy określić: konfigurację źródła (wybierz UT) i konfigurację odbiornika (wybierz „Odbiornik”). Następnie otwórz zakładkę „Zaawansowane” i wypełnij następujące pola:
- nazwa pliku reguł wymiany - utworzone reguły wymiany zostaną zapisane pod tą nazwą. Nazwę pliku można zmienić w dowolnym momencie, ale najlepiej ustawić ją teraz. Pozwoli to zaoszczędzić czas w przyszłości. Reguły demo nazwałem: „rules-ut-to-priemnik.xml”.
- name - nazwa konwersji. Nazwa może być absolutnie dowolna, ograniczyłem się do „Demo. UT do odbiornika”.

To wszystko, kliknij "OK". Natychmiast pojawia się przed nami okno z prośbą o automatyczne utworzenie wszystkich reguł. Zgoda na tak kuszącą ofertę da mistrzowi polecenie automatycznego przeanalizowania opisu wybranych konfiguracji i samodzielnego wygenerowania reguł wymiany.

Postawmy od razu „i”. Mistrz nie będzie w stanie wygenerować niczego poważnego. Nie należy jednak pomijać tej możliwości. Jeśli potrzebujesz nawiązać wymianę między identycznymi konfiguracjami, bardzo pomocne będą usługi kreatora. W naszym przykładzie preferowany jest tryb ręczny.

Przyjrzyjmy się bliżej oknie „Ustawienia reguł wymiany”. Interfejs może wydawać się nieco mylący - duża liczba zakładek wypełnionych kontrolkami. W zasadzie wszystko nie jest takie trudne, zaczynasz przyzwyczajać się do tego szaleństwa po kilku godzinach pracy z aplikacją.
Na tym etapie interesują nas dwie zakładki: „Reguły konwersji obiektów” oraz „Reguły przesyłania danych”. Na pierwszym musimy ustawić pasujące reguły, czyli porównaj obiekty o dwóch konfiguracjach. Na drugim określ możliwe obiekty, które będą dostępne dla użytkownika do rozładunku.
W drugiej połowie zakładki „Reguły konwersji obiektów” znajduje się dodatkowy panel z dwiema zakładkami: „Konwersja nieruchomości” i „ Konwersja wartości”. Pierwszy z nich wybierze właściwości (rekwizyty) wybranego obiektu, a drugi jest niezbędny do pracy z predefiniowanymi wartościami (na przykład predefiniowanymi elementami słownika lub elementami wyliczenia).
Świetnie, teraz stwórzmy reguły konwersji dla katalogów. Możesz wykonać tę akcję na dwa sposoby: użyj kreatora synchronizacji obiektów (kliknij „”) lub dodaj dopasowania dla każdego obiektu ręcznie.
Aby zaoszczędzić miejsce, skorzystamy z pierwszej opcji. W oknie kreatora odznacz pole „ Dokumenty”(interesują nas tylko katalogi) i poszerzyć grupę” Leksykony”. Uważnie przewijamy listę i patrzymy na nazwy katalogów, które można porównać.

W moim przypadku istnieją trzy takie katalogi: Nomenklatura, Organizacje i Magazyny. Istnieje również katalog Clients, który wykonuje to samo ładowanie semantyczne, co „ Kontrahenci” z konfiguracji” UT”. To prawda, że mistrz nie mógł ich porównać ze względu na ich doskonałe imiona.
Możemy sami naprawić tę usterkę. Znajdź w oknie Mapowania obiektów» podręcznik « Klienci”, aw kolumnie „Źródło” wybierz książkę informacyjną „Kontrahenci”. Następnie zaznacz pole w kolumnie „Typ” i kliknij przycisk „OK”.
Kreator synchronizacji obiektów wyświetli monit o automatyczne utworzenie reguł konwersji właściwości wszystkich wybranych obiektów. Właściwości zostaną dopasowane według nazwy i dla naszej demonstracji to wystarczy, zgadzamy się. Kolejnym pytaniem będzie propozycja stworzenia reguł przesyłania. Zgódźmy się na to.

Podstawa regulaminu giełdy jest gotowa. Wybraliśmy obiekty do synchronizacji, a reguły konwersji właściwości i reguły przesyłania zostały utworzone automatycznie. Zapiszmy reguły wymiany do pliku, a następnie otwórzmy „Źródło” IB (w moim przypadku jest to UT) i rozpocznijmy w nim przetwarzanie usługi V8Exchan82.epf.

Przede wszystkim w oknie przetwarzania wybierz utworzone przez nas reguły wymiany. Na pytanie o ładowanie reguł odpowiadamy twierdząco. Przetwarzanie przeanalizuje reguły wymiany i zbuduje drzewo o tej samej nazwie dla obiektów dostępnych do rozładunku. W tym drzewie możemy ustawić wszelkiego rodzaju filtry lub węzły wymiany, zmieniając potrzebne nam dane. Chcemy wgrać absolutnie wszystkie dane, więc nie ma potrzeby instalowania filtrów.
Po zakończeniu procesu wgrywania danych do pliku przejdź do IB” Odbiorca”. Otwieramy w nim również przetwarzanie V8Exchan82.epf, tylko tym razem przechodzimy do zakładki „Wczytywanie danych”. Wybierz plik danych i kliknij przycisk „Prześlij”. Wszystko, dane zostały pomyślnie przesłane.
Zadania z prawdziwego świata
Pierwsze demo może wprowadzać w błąd. Wszystko wygląda dość prosto i logicznie. W rzeczywistości to nieprawda. W prawdziwej pracy powstają zadania trudne lub całkowicie niemożliwe do rozwiązania za pomocą samych środków wizualnych (bez programowania).
Aby nie zawieść się technologią, przygotowałem kilka realnych zadań. Na pewno spotkasz je w pracy. Nie wyglądają tak trywialnie i sprawiają, że patrzysz na konwersję danych pod nowym kątem. Uważnie rozważ przedstawione przykłady i wykorzystaj je jako fragmenty przy rozwiązywaniu rzeczywistych problemów.
Zadanie numer 1. Uzupełnij brakujące dane
Załóżmy, że musimy przenieść katalog „ Kontrahenci”. Odbiornik ma do tego podobną książkę referencyjną „Klienci”. Całkowicie nadaje się do przechowywania danych, ale ma rekwizyty” Organizacja”, umożliwiając oddzielenie kontrahentów według przynależności do organizacji. Domyślnie wszyscy kontrahenci muszą należeć do bieżącej organizacji (można to uzyskać ze stałej o tej samej nazwie).
Istnieje kilka rozwiązań tego problemu. Rozważymy możliwość wypełnienia rekwizytów” Organizacja”w samej bazie” Odbiorca", tj. w momencie ładowania danych. Obecna organizacja jest przechowywana w stałej, więc nie ma bariery w uzyskaniu tej wartości. Otwórzmy regułę konwersji obiektów (zwaną dalej FRP)” Klienci” (kliknij dwukrotnie obiekt) i w kreatorze konfiguracji reguł przejdź do sekcji „Obsługa zdarzeń”. Na liście handlerów znajdziemy „ Po załadowaniu”.
Opiszmy kod do pobrania bieżącej organizacji z późniejszym przypisaniem do atrybutu. W momencie wyzwolenia obsługi „Po załadowaniu” obiekt będzie w pełni uformowany, ale jeszcze nie zapisany do bazy danych. Nikt nie zabrania nam zmieniać według naszego uznania:
If NOT Object.ThisGroup Then Object.Organization = Constants.CurrentOrganization.Get(); EndIf;
Przed wypełnieniem rekwizytów” Organizacja» należy sprawdzić wartość atrybutu « Ta grupa”. Dla przewodnika ” Klienci» flaga hierarchiczna jest ustawiona, dlatego konieczne jest sprawdzenie grupy. Podobnie odbywa się wypełnianie wszelkich szczegółów. Koniecznie przeczytaj pomoc dotyczącą innych opcji obsługi ” Po załadowaniu”. Na przykład wśród nich jest parametr „ Odmowa”. Jeżeli zostanie mu przypisana wartość „True”, to obiekt nie zostanie zapisany do bazy danych. Dzięki temu możliwe staje się ograniczenie obiektów do zapisu w momencie ładowania.
Zadanie nr 2. Szczegóły w rejestrze informacyjnym
W podręczniku " Kontrahenci"Konfiguracja UT, są szczegóły" Kupujący" oraz " Dostawca”. Oba rekwizyty są typu „ logiczne” i służą do określenia rodzaju kontrahenta. W IB” Odbiorca”, w podręczniku „ Klienci„Nie ma podobnych szczegółów, ale istnieje rejestr informacji” Rodzaje Klientów”. Pełni podobną funkcję i może przechowywać wiele tagów dla jednego klienta. Naszym zadaniem jest przeniesienie wartości danych do odrębnych zapisów rejestru informacyjnego.
Niestety same środki wizualne też tu nie radzą sobie. Zacznijmy od małych, stwórzmy nowe PCO dla rejestru informacyjnego ” Rodzaje Klientów”. Nie podawaj niczego jako źródła. Odrzuć automatyczne tworzenie reguł przesyłania.
Następnym krokiem jest stworzenie reguł przesyłania. Przejdź do odpowiedniej zakładki i kliknij „ Dodać”. W oknie dodawania reguł przesyłania wypełnij:
- metoda próbkowania. Zmień na „Algorytm arbitralny”;
- reguła konwersji. Wybierz rejestr informacji „Typy klientów”;
- Kod (nazwa) reguły. Piszemy to jako „Przesyłanie gatunków klienta”;

Teraz musisz napisać kod do wybierania danych do przesłania. Tutaj parametr „ Próbkowanie danych”. W nim możemy umieścić kolekcję z przygotowanym zbiorem danych. Parametr " Próbkowanie danych” może przyjmować różne wartości – wynik zapytania, wybór, kolekcje wartości itp. Inicjujemy go jako tabelę wartości z dwiema kolumnami: klient i typ klienta.
Poniżej znajduje się kod obsługi zdarzeń „ Przed przetwarzaniem”. Inicjuje parametr „ Próbkowanie danych” a następnie wypełnienie danych z katalogu “ Kontrahenci”. Tutaj warto zwrócić uwagę na wypełnienie kolumny „ Typ klienta”. W „UT” mamy cechy typu „Boolean”, a w odbiorcy wyliczenie.
Na tym etapie nie możemy doprowadzić ich do pożądanego typu (nie ma go w UT), więc na razie zostawimy to w postaci sznurków. Nie musisz tego robić, ale od razu chcę pokazać, jak rzutować na brakujący typ w źródle.
Pobieranie danych = NowaTabelaWartości(); Wybór danych.Kolumny.Add("Klient"); Wybór danych.Columns.Add("TypKlienta"); Wybór danych z katalogu = Directorys.Contractors.Select(); Podczas pobierania pętli DataFromCatalog.Next() Jeśli FetchingDataFromCatalog.ThisGroup następnie kontynuuj; EndIf; Jeśli DataFetchFromCatalog.Buyer Then NewString = DataFetch.Add(); NewString.Client = PróbkowanieDanychZKatalogu.Referencja; NewString.ClientType = "Kupujący"; EndIf; Jeśli DataFetchFromCatalog.Provider Then NewString = DataFetch.Add(); NewString.Client = PróbkowanieDanychZKatalogu.Referencja; NewString.ClientType = "Dostawca"; EndIf; Zakończ cykl;
Zapisz regułę przesyłania danych i wróć do „ Zasady konwersji obiektów”. Dodajmy do rejestru informacyjnego „ Rodzaje Klientów zasady konwersji własności: klient i typ klienta. Zostawiamy źródło puste, a w obsłudze zdarzeń „Before discharge” piszemy:
//Dla właściwości „Klient” Value = Source.Client; //Dla właściwości „CustomerType” If Source.Customer = "Buyer" Then Expression = "Enumerations.CustomerTypes.Buyer" ElseIf Source.Customer = "Dostawca" Then Expression = "Enumerations.CustomerTypes.Supplier"; EndIf;
Na liście szczegóły są wypełniane na podstawie dokonanego wyboru danych. Podajemy klienta po prostu jako link i wpisujemy typ klienta w parametrze " Wyrażenie”. Dane tego parametru zostaną zinterpretowane w odbiorniku, a po wykonaniu atrybut zostanie uzupełniony poprawną wartością z wyliczenia.
To wszystko, zasady wymiany są gotowe.Rozważany przykład okazał się dość uniwersalny. Podobne podejście jest często stosowane przy przesyłaniu danych z konfiguracji utworzonych na platformie 7.7. Uderzającym tego przykładem jest transfer danych okresowych.

Zadanie nr 3. Sztuczki tabelaryczne
Często zdarzają się zadania, które wymagają publikowania wierszy jednej części tabelarycznej w kilku. Na przykład w początkowej konfiguracji usługi i towary rejestrowane są w jednej sekcji tabelarycznej, natomiast przechowywanie tych podmiotów jest wydzielone w odbiorniku. Ponownie problemu nie da się rozwiązać za pomocą środków wizualnych. Tutaj wygodnie jest przyjąć rozwiązanie drugiego problemu jako podstawę.
Tworzymy regułę przesyłania danych, określamy dowolny algorytm i piszemy zapytanie w module obsługi „Przed przesłaniem”, aby pobrać dane z sekcji tabelarycznej.
Aby zaoszczędzić miejsce, nie podam kodu (zawsze można odwołać się do kodu źródłowego) żądania - nie ma w tym nic niezwykłego. Sortujemy wynikową próbkę i umieszczamy posortowane wyniki w znanym już parametrze „ Próbkowanie danych”. Ponownie wygodnie jest użyć tabeli wartości jako kolekcji:
Pobieranie danych = NowaTabelaWartości(); //Tu będzie jeszcze jedna sekcja tabelaryczna Data Selection.Columns.Add("Produkty"); //Tutaj będzie również sekcja tabelaryczna Data Selection.Columns.Add("Usługi"); Wybór danych z.Kolumny.Dodaj(„Link”);
Zadanie nr 4. Przenoszenie danych do operacji
Jeśli organizacja korzysta z kilku systemów księgowych, prędzej czy później pojawi się potrzeba migracji danych z późniejszym tworzeniem księgowań.
W konfiguracji " BP„istnieje dokument uniwersalny” Operacja” i jest idealny do formowania większej liczby drutów. Oto tylko jeden problem - dokument jest wykonany sprytnie i nie jest tak łatwo przenieść do niego dane.
Przykład takiej konwersji można znaleźć w kodzie źródłowym artykułu. Ilość kodu okazała się dość duża, więc nie ma sensu publikować go do artykułu. Powiem tylko, że przesyłanie ponownie wykorzystuje dowolny algorytm w zasadach przesyłania danych.
Zadanie nr 5. Synchronizacja danych w wielu atrybutach
Omówiliśmy już kilka przykładów, ale do tej pory nie rozmawialiśmy o synchronizacji obiektów podczas migracji. Wyobraźmy sobie, że potrzebujemy przenieść kontrahentów i część z nich prawdopodobnie znajduje się w bazie danych odbiorcy. Jak przesyłać dane i zapobiegać duplikatom? W związku z tym CD oferuje kilka sposobów synchronizacji przesyłanych obiektów.
Pierwszy to unikalny identyfikator. Wiele obiektów ma unikalny identyfikator, który gwarantuje unikalność w obrębie tabeli. Na przykład w podręczniku „ Kontrahenci” nie może mieć dwóch elementów o tym samym identyfikatorze. Płyta CD dokonuje obliczeń w tym zakresie, a dla wszystkich utworzonych PSP wyszukiwanie według identyfikatora jest domyślnie natychmiast włączone. Podczas tworzenia PSP powinieneś zauważyć ikonę lupy obok nazwy obiektu.
Synchronizacja za pomocą unikalnego identyfikatora jest niezawodną metodą, ale nie zawsze jest odpowiednia. Podczas łączenia katalogów „ Kontrahenci” (z kilku różnych systemów) niewiele mu pomaga.
W takich przypadkach lepiej jest synchronizować obiekty według kilku kryteriów. Bardziej poprawne jest wyszukiwanie kontrahentów według NIP, KPP, Nazwy lub rozbicie wyszukiwania na kilka etapów.
Konwersja danych nie ogranicza programisty w definiowaniu kryteriów wyszukiwania. Rozważmy abstrakcyjny przykład. Załóżmy, że musimy zsynchronizować katalogi” Kontrahenci” z różnych baz informacyjnych. Przygotujmy PCP i w ustawieniach reguł konwersji obiektu zaznacz pole „ Kontynuuj wyszukiwanie w polach wyszukiwania, jeśli obiekt odbiorcy nie zostanie znaleziony według ID”. Dzięki tej akcji od razu zdefiniowaliśmy dwa kryteria wyszukiwania - według unikalnego identyfikatora i dowolnych pól.
Mamy prawo do samodzielnego wyboru pól. Po zanotowaniu numeru NIP, KPP, nazwy natychmiast wskażemy kilka kryteriów wyszukiwania. Wygodna? Całkiem, ale znowu to nie wystarczy. A co jeśli chcemy zmienić kryteria wyszukiwania? Na przykład najpierw szukamy garści TIN + KPP, a jeśli nic nie znajdziemy, to zaczynamy próbować szczęścia z nazwą.
Zaimplementowanie takiego algorytmu jest całkiem możliwe. W obsłudze zdarzeń Pola wyszukiwania” możemy określić do 10 kryteriów wyszukiwania i dla każdego z nich zdefiniować własną kompozycję pól wyszukiwania:
Jeśli SearchOptionNumber = 1, SearchPropertyNameString = „TIN, KPP”; ElseIfSearchVariantNumber = 2 ThenSearchPropertyNameString = „Nazwa”; EndIf;
Zawsze istnieje wiele rozwiązań.
Każde zadanie ma kilka rozwiązań, a przesyłanie danych między różnymi konfiguracjami nie jest wyjątkiem. Każdy programista ma prawo wybrać własną ścieżkę rozwiązania, ale jeśli stale musisz opracowywać skomplikowane migracje danych, to zdecydowanie polecam zwrócenie uwagi na konfigurację „”. Niech na początku trzeba zainwestować środki (czas) w szkolenia, ale z nawiązką zwrócą się one na pierwszym mniej lub bardziej poważnym projekcie.
Moim zdaniem firma 1C niezasłużenie omija temat korzystania z konwersji danych. Przez cały czas istnienia technologii opublikowano na jej temat tylko jedną książkę: „1C: Enterprise 8. Konwersja danych: wymiana między rozwiązaniami aplikacyjnymi”. Książka jest dość stara (2008), ale nadal warto się z nią zapoznać.
Znajomość platformy jest nadal wymagana
» jest narzędziem uniwersalnym, ale jeśli planujesz używać go do tworzenia migracji danych z konfiguracji opracowanych dla platformy 1C:Enterprise 7.7, to będziesz musiał poświęcić czas na zapoznanie się z wbudowanym językiem. Składnia i ideologia języka jest bardzo różna, więc musisz poświęcić czas na naukę. Reszta zasady pozostaje taka sama.
"1C: Przedsiębiorstwo" to uniwersalny system do automatyzacji działalności przedsiębiorstwa i może być używany do rozwiązywania różnych problemów zarządczych i księgowych. Obecnie na platformie opracowano wiele standardowych i specjalistycznych rozwiązań " 1C: Przedsiębiorstwo”, które mogą działać w ścisłej integracji z innymi rozwiązaniami, zarówno na tej platformie, jak i z oprogramowaniem innych firm.
Ogromne znaczenie dla efektywnej pracy ma umiejętność organizowania wymiany pomiędzy różnymi systemami informatycznymi. Platforma " 1C: Przedsiębiorstwo" dostarcza różnorodne narzędzia do wymiany danych i integracji rozwiązań aplikacyjnych.
Książka szczegółowo opisuje wymianę danych w formacie XML, który jest obecnie powszechnie akceptowanym sposobem przedstawiania danych. Opisano procedury tworzenia reguł, których zastosowanie zapewni transfer informacji z jednego systemu informatycznego do drugiego, w tym wymianę danych pomiędzy typowymi konfiguracjami. 1C: Przedsiębiorstwo".
Do książki dołączona jest płyta CD zawierająca demonstracyjne bazy informacyjne z przykładami zasad wymiany i konfiguracji” 1C: Przedsiębiorstwo. Konwersja danych".
struktura książki
Wstęp
Rozdział 1. Ogólne zasady ustalania zasad
Rozdział 2 Korzystanie z reguł
Rozdział 3 Automatyczne tworzenie reguł
Rozdział 4 Struktura reguły
Rozdział 5 Szczegółowe studium zasad
Rozdział 6 Obsługa zdarzeń
- Opcje
- Moduły obsługi „konwersji”
- Moduły obsługi „reguł przesyłania danych”
- Programy obsługi „Reguły konwersji obiektów”
- Moduły obsługi „Reguły konwersji grupy nieruchomości”
- Moduły obsługi „Reguły konwersji nieruchomości”
Rozdział 7 Pola wyszukiwania
Rozdział 8 Zasady czyszczenia danych
Rozdział 9 Algorytmy i zapytania
Rozdział 10 Typowe przykłady reguł. Obejścia
- Konwersja wyliczenia
- Konwersja katalogów
- Konwersja dokumentów
- Konwersja rejestru informacji
- Konwersja planu kont
- Konwersja planu charakterystycznych typów
- Konwersja planu typu kalkulacji
- Stała konwersja 1C: Przedsiębiorstwo 7,7
- 1C: Konwersja transakcji księgowych Enterprise 7.7
Rozdział 11 Optymalizacja reguł
- Zasady przesyłania danych
- Zasady konwersji obiektów
- Przetwarzanie "Uniwersalnej wymiany danych XML"