Ensartet kontinuerlig distribution i MS EXCEL. Ensartede og eksponentielle love for fordeling af en kontinuert stokastisk variabel
Dette spørgsmål er længe blevet undersøgt i detaljer, og metoden med polære koordinater, foreslået af George Box, Mervyn Muller og George Marsaglia i 1958, blev mest brugt. Denne metode giver dig mulighed for at få et par uafhængige normalfordelte tilfældige variable med middelværdi 0 og varians 1 som følger:
Hvor Z 0 og Z 1 er de ønskede værdier, s \u003d u 2 + v 2, og u og v er tilfældige variable ensartet fordelt på segmentet (-1, 1), valgt på en sådan måde, at betingelsen 0< s < 1.
Mange bruger disse formler uden selv at tænke, og mange har ikke engang mistanke om deres eksistens, da de bruger færdige implementeringer. Men der er folk, der har spørgsmål: "Hvor kom denne formel fra? Og hvorfor får du et par værdier på én gang? I det følgende vil jeg forsøge at give et klart svar på disse spørgsmål.
Til at begynde med, lad mig minde dig om, hvad sandsynlighedstætheden, fordelingsfunktionen af en stokastisk variabel og den inverse funktion er. Antag, at der er en tilfældig variabel, hvis fordeling er givet af tæthedsfunktionen f(x), som har følgende form:

Dette betyder, at sandsynligheden for, at værdien af denne tilfældige variabel vil være i intervallet (A, B) er lig med arealet af det skraverede område. Og som en konsekvens skal arealet af hele det skraverede område være lig med enhed, da værdien af den tilfældige variabel under alle omstændigheder falder ind under funktionen fs domæne.
Fordelingsfunktionen af en stokastisk variabel er et integral af tæthedsfunktionen. Og i dette tilfælde vil dens omtrentlige form være som følger:

Her er meningen, at værdien af den stokastiske variabel vil være mindre end A med sandsynlighed B. Og som et resultat falder funktionen aldrig, og dens værdier ligger i intervallet .
En invers funktion er en funktion, der returnerer argumentet for den oprindelige funktion, hvis du overfører værdien af den oprindelige funktion til den. For eksempel, for funktionen x 2 vil det omvendte være rodekstraktionsfunktionen, for sin (x) er det arcsin (x) osv.
Da de fleste pseudo-tilfældige talgeneratorer kun giver en ensartet fordeling ved udgangen, bliver det ofte nødvendigt at konvertere den til en anden. I dette tilfælde til en normal gaussisk:

Grundlaget for alle metoder til at transformere en ensartet fordeling til enhver anden fordeling er den omvendte transformationsmetode. Det fungerer som følger. Der findes en funktion, der er omvendt til funktionen af den påkrævede fordeling, og en tilfældig variabel ensartet fordelt på segmentet (0, 1) sendes til den som et argument. Ved udgangen får vi en værdi med den nødvendige fordeling. For klarhedens skyld er det følgende billede.

Et ensartet segment bliver således ligesom udtværet i overensstemmelse med den nye fordeling, idet det projiceres på en anden akse gennem en omvendt funktion. Men problemet er, at integralet af tætheden af den Gaussiske fordeling ikke er let at beregne, så ovennævnte videnskabsmænd måtte snyde.
Der er en chi-kvadratfordeling (Pearson-fordeling), som er fordelingen af summen af kvadrater af k uafhængige normale stokastiske variable. Og i det tilfælde, hvor k = 2, er denne fordeling eksponentiel.

Dette betyder, at hvis et punkt i et rektangulært koordinatsystem har tilfældige X- og Y-koordinater normalfordelte, så efter konvertering af disse koordinater til det polære system (r, θ), kvadratet af radius (afstanden fra origo til punktet) vil blive fordelt eksponentielt, da kvadratet af radius er summen af kvadraterne af koordinaterne (ifølge Pythagoras lov). Fordelingstætheden af sådanne punkter på flyet vil se sådan ud:


Da den er ens i alle retninger, vil vinklen θ have en ensartet fordeling i området fra 0 til 2π. Det omvendte er også sandt: Hvis du angiver et punkt i det polære koordinatsystem ved hjælp af to uafhængige stokastiske variable (vinklen fordelt ensartet og radius fordelt eksponentielt), så vil de rektangulære koordinater for dette punkt være uafhængige normale stokastiske variable. Og det er allerede meget nemmere at opnå en eksponentiel fordeling fra en ensartet, ved at bruge den samme inverse transformationsmetode. Dette er essensen af Box-Mullers polære metode.
Lad os nu få formlerne.
![]() (1)
(1)
For at opnå r og θ er det nødvendigt at generere to stokastiske variable ensartet fordelt på segmentet (0, 1) (lad os kalde dem u og v), hvoraf fordelingen af den ene (lad os sige v) skal konverteres til eksponentiel til få radius. Den eksponentielle fordelingsfunktion ser således ud:
Dens omvendte funktion:
![]()
Da den ensartede fordeling er symmetrisk, vil transformationen fungere på samme måde med funktionen
![]()
Det følger af chi-kvadratfordelingsformlen, at λ = 0,5. Vi erstatter λ, v i denne funktion og får kvadratet af radius, og derefter radius selv:

Vi opnår vinklen ved at strække enhedssegmentet til 2π:
Nu erstatter vi r og θ i formlerne (1) og får:
 (2)
(2)
Disse formler er klar til brug. X og Y vil være uafhængige og normalfordelte med en varians på 1 og en middelværdi på 0. For at få en fordeling med andre karakteristika er det nok at gange resultatet af funktionen med standardafvigelsen og addere middelværdien.
Men det er muligt at slippe af med trigonometriske funktioner ved at specificere vinklen ikke direkte, men indirekte gennem de rektangulære koordinater af et tilfældigt punkt i en cirkel. Så vil det gennem disse koordinater være muligt at beregne længden af radiusvektoren, og derefter finde cosinus og sinus ved at dividere henholdsvis x og y med det. Hvordan og hvorfor virker det?
Vi vælger et tilfældigt punkt fra ensartet fordelt i cirklen af enhedsradius og betegner kvadratet på længden af radiusvektoren for dette punkt med bogstavet s:

Valget foretages ved at tildele tilfældige rektangulære x- og y-koordinater ensartet fordelt i intervallet (-1, 1), og kassere punkter, der ikke hører til cirklen, samt det centrale punkt, hvor vinklen på radiusvektoren er ikke defineret. Det vil sige betingelsen 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Vi får formlerne, som i begyndelsen af artiklen. Ulempen ved denne metode er afvisningen af punkter, der ikke er inkluderet i cirklen. Det vil sige kun at bruge 78,5 % af de genererede tilfældige variable. På ældre computere var manglen på trigonometriske funktioner stadig en stor fordel. Nu, når en processorinstruktion samtidig beregner sinus og cosinus på et øjeblik, tror jeg, at disse metoder stadig kan konkurrere.
Personligt har jeg to spørgsmål mere:
- Hvorfor er værdien af s jævnt fordelt?
- Hvorfor er summen af kvadrater af to normale stokastiske variable eksponentielt fordelt?

Hvis en lignende transformation udføres for en normal tilfældig variabel, vil tæthedsfunktionen af dens kvadrat vise sig at ligne en hyperbel. Og tilføjelsen af to kvadrater af normale tilfældige variable er allerede en meget mere kompleks proces forbundet med dobbelt integration. Og det faktum, at resultatet vil være en eksponentiel fordeling, personligt, er det for mig at kontrollere det med en praktisk metode eller acceptere det som et aksiom. Og for dem, der er interesserede, foreslår jeg, at du sætter dig ind i emnet nærmere ved at trække viden fra disse bøger:
- Wentzel E.S. Sandsynlighedsteori
- Knut D.E. Kunsten at programmere bind 2
Afslutningsvis vil jeg give et eksempel på implementeringen af en normalfordelt tilfældig talgenerator i JavaScript:
Funktion Gauss() ( var klar = falsk; var sekund = 0.0; this.next = funktion(middel, dev) ( middel = middel == udefineret ? 0.0: middel; dev = afv == udefineret ? 1.0: afv; hvis ( this.ready) ( this.ready = false; return this.second * dev + mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. random() - 1,0; s = u * u + v * v; ) while (s > 1,0 || s == 0,0); var r = Math.sqrt(-2,0 * Math.log(s) / s); this.second = r * u; this.ready = sand; return r * v * dev + mean; ) ); ) g = new Gauss(); // opret et objekt a = g.next(); // generer et par værdier og få den første b = g.next(); // få den anden c = g.next(); // generer et par værdier igen og få den første
Parametrene for middelværdi (matematisk forventning) og dev (standardafvigelse) er valgfri. Jeg gør opmærksom på, at logaritmen er naturlig.
Fordelingsfunktionen i dette tilfælde vil ifølge (5.7) have formen:
hvor: m er den matematiske forventning, s er standardafvigelsen.
Normalfordelingen kaldes også gaussisk efter den tyske matematiker Gauss. At en stokastisk variabel har en normalfordeling med parametre: m,, betegnes som følger: N (m, s), hvor: m =a =M ;
Ganske ofte, i formler, er den matematiske forventning betegnet med -en . Hvis en stokastisk variabel er fordelt efter N(0,1)-loven, så kaldes den en normaliseret eller standardiseret normalvariabel. Fordelingsfunktionen for det har formen:
|
|
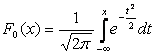 .
.Grafen over densiteten af normalfordelingen, som kaldes normalkurven eller Gauss-kurven, er vist i fig. 5.4.

Ris. 5.4. Normal fordelingstæthed
Bestemmelse af de numeriske karakteristika for en tilfældig variabel ved dens tæthed betragtes i et eksempel.
Eksempel 6.
En kontinuert stokastisk variabel er givet ved fordelingstætheden: ![]() .
.
Bestem typen af fordeling, find den matematiske forventning M(X) og variansen D(X).
Ved at sammenligne den givne fordelingstæthed med (5.16), kan vi konkludere, at normalfordelingsloven med m =4 er givet. Derfor er matematisk forventning M(X)=4, varians D(X)=9.
Standardafvigelse s=3.
Laplace-funktionen, som har formen:
|
|
 ,
,er relateret til normalfordelingsfunktionen (5.17), ved relationen:
F 0 (x) \u003d F (x) + 0,5.
Laplace-funktionen er mærkelig.
Ф(-x)=-Ф(x).
Værdierne for Laplace-funktionen Ф(х) er opstillet i tabelform og taget fra tabellen i henhold til værdien af x (se bilag 1).
Normalfordelingen af en kontinuert stokastisk variabel spiller en vigtig rolle i sandsynlighedsteorien og i beskrivelsen af virkeligheden; den er meget udbredt i tilfældige naturfænomener. I praksis er der meget ofte stokastiske variable, som er dannet netop som et resultat af summeringen af mange tilfældige led. Især analysen af målefejl viser, at de er summen af forskellige slags fejl. Praksis viser, at sandsynlighedsfordelingen for målefejl er tæt på normalloven.
Ved hjælp af Laplace-funktionen kan man løse problemer med at beregne sandsynligheden for at falde ind i et givet interval og en given afvigelse af en normal stokastisk variabel.
Overvej en ensartet kontinuerlig fordeling. Lad os beregne den matematiske forventning og varians. Lad os generere tilfældige værdier ved hjælp af MS EXCEL-funktionenRAND() og Analysepakke-tilføjelsen, vil vi evaluere middelværdien og standardafvigelsen.
jævnt fordelt på intervallet har den stokastiske variabel:
Lad os generere en matrix med 50 numre fra området )