Khoảng tin cậy để ước tính giá trị trung bình (đã biết phương sai) trong MS EXCEL. Khoảng tin cậy
Bất kỳ mẫu nào cũng chỉ đưa ra ý tưởng gần đúng về tổng thể chung và tất cả các đặc điểm thống kê mẫu (trung bình, chế độ, phương sai...) đều là một số gần đúng hoặc ước tính các tham số chung, trong hầu hết các trường hợp không thể tính toán được do đến sự khó tiếp cận của dân chúng nói chung (Hình 20) .
Hình 20. Lỗi lấy mẫu
Nhưng bạn có thể chỉ định khoảng trong đó, với một mức xác suất nhất định, giá trị thực (tổng quát) của đặc tính thống kê nằm ở đó. Khoảng này được gọi là d khoảng tin cậy (CI).
Vậy giá trị trung bình chung với xác suất 95% nằm trong
từ đến, (20)
Ở đâu t – bảng giá trị bài kiểm tra của Sinh viên cho α = 0,05 và f= N-1
CI 99% cũng có thể được tìm thấy trong trường hợp này t được chọn cho α =0,01.
Ý nghĩa thực tế của khoảng tin cậy là gì?
Khoảng tin cậy rộng cho thấy rằng giá trị trung bình của mẫu không phản ánh chính xác giá trị trung bình của tổng thể. Điều này thường là do cỡ mẫu không đủ hoặc do tính không đồng nhất của nó, tức là độ phân tán lớn. Cả hai đều đưa ra sai số trung bình lớn hơn và theo đó, CI rộng hơn. Và đây là cơ sở để quay lại giai đoạn lập kế hoạch nghiên cứu.
Giới hạn trên và giới hạn dưới của CI cung cấp ước tính xem kết quả có ý nghĩa lâm sàng hay không
Chúng ta hãy đi sâu vào chi tiết hơn về câu hỏi về ý nghĩa thống kê và lâm sàng của kết quả nghiên cứu các đặc tính của nhóm. Chúng ta hãy nhớ rằng nhiệm vụ của thống kê là phát hiện ít nhất một số khác biệt trong tổng thể dựa trên dữ liệu mẫu. Thách thức đối với các bác sĩ lâm sàng là phát hiện những khác biệt (không phải bất kỳ) nào để hỗ trợ chẩn đoán hoặc điều trị. Và kết luận thống kê không phải lúc nào cũng là cơ sở cho kết luận lâm sàng. Do đó, sự giảm đáng kể về mặt thống kê của hemoglobin khoảng 3 g/l không phải là nguyên nhân đáng lo ngại. Và ngược lại, nếu một vấn đề nào đó trong cơ thể con người không phổ biến ở cấp độ toàn dân, thì đây không phải là lý do để không giải quyết vấn đề này.
|
Chúng ta hãy nhìn vào tình huống này ví dụ. Các nhà nghiên cứu tự hỏi liệu những cậu bé mắc một loại bệnh truyền nhiễm nào đó có chậm phát triển hơn các bạn cùng lứa hay không. Với mục đích này, một nghiên cứu mẫu đã được tiến hành với sự tham gia của 10 cậu bé mắc bệnh này. Kết quả được trình bày ở Bảng 23. Bảng 23. Kết quả xử lý thống kê
Từ những tính toán này, chiều cao trung bình mẫu của các bé trai 10 tuổi mắc một số bệnh truyền nhiễm gần như bình thường (132,5 cm). Tuy nhiên, giới hạn dưới của khoảng tin cậy (126,6 cm) chỉ ra rằng có 95% khả năng chiều cao trung bình thực sự của những đứa trẻ này tương ứng với khái niệm “chiều cao thấp”, tức là. những đứa trẻ này bị còi cọc. Trong ví dụ này, kết quả tính toán khoảng tin cậy có ý nghĩa lâm sàng. |
|||||||||||||||||||
Trong các phần trước chúng ta đã xem xét vấn đề ước lượng một tham số chưa biết MỘT một số. Đây được gọi là ước tính “điểm”. Trong một số nhiệm vụ, bạn không chỉ cần tìm tham số MỘT giá trị số phù hợp mà còn để đánh giá độ chính xác và độ tin cậy của nó. Bạn cần biết việc thay thế một tham số có thể dẫn đến lỗi gì MỘTước tính điểm của nó MỘT và với mức độ tin cậy nào chúng ta có thể mong đợi rằng những sai số này sẽ không vượt quá giới hạn đã biết?
Những vấn đề thuộc loại này đặc biệt phù hợp với một số lượng nhỏ các quan sát, khi ước lượng điểm và trong phần lớn là sự thay thế ngẫu nhiên và gần đúng của a bằng a có thể dẫn đến sai sót nghiêm trọng.
Để đưa ra ý tưởng về tính chính xác và độ tin cậy của ước tính MỘT,
Trong thống kê toán học, cái gọi là khoảng tin cậy và xác suất tin cậy được sử dụng.
Cho tham số MỘTước tính khách quan thu được từ kinh nghiệm MỘT. Chúng tôi muốn ước tính lỗi có thể xảy ra trong trường hợp này. Chúng ta hãy gán một số xác suất p đủ lớn (ví dụ: p = 0,9, 0,95 hoặc 0,99) sao cho một sự kiện có xác suất p có thể được coi là đáng tin cậy trên thực tế và tìm một giá trị s sao cho
Sau đó, phạm vi giá trị thực tế có thể xảy ra của lỗi phát sinh trong quá trình thay thế MỘT TRÊN MỘT, sẽ là ± s; Các sai số lớn về giá trị tuyệt đối sẽ chỉ xuất hiện với xác suất thấp a = 1 - p. Hãy viết lại (14.3.1) thành:
Đẳng thức (14.3.2) có nghĩa là với xác suất p giá trị chưa biết của tham số MỘT rơi vào khoảng
Cần lưu ý một trường hợp. Trước đây, chúng ta đã xem xét nhiều lần xác suất của một biến ngẫu nhiên rơi vào một khoảng không ngẫu nhiên nhất định. Ở đây tình hình lại khác: độ lớn MỘT không phải là ngẫu nhiên, nhưng khoảng /p là ngẫu nhiên. Vị trí của nó trên trục x là ngẫu nhiên, được xác định bởi tâm của nó. MỘT; Nói chung, độ dài của khoảng 2s cũng là ngẫu nhiên, vì giá trị của s thường được tính từ dữ liệu thực nghiệm. Do đó, trong trường hợp này, sẽ tốt hơn nếu hiểu giá trị p không phải là xác suất “đạt” điểm MỘT trong khoảng / p và xác suất mà khoảng / p ngẫu nhiên sẽ bao trùm điểm MỘT(Hình 14.3.1).

Cơm. 14.3.1
Xác suất p thường được gọi là xác suất tin cậy và khoảng / p - khoảng tin cậy. Ranh giới khoảng Nếu như. a x = a- cát một 2 = một + và được gọi ranh giới tin cậy.
Hãy đưa ra một cách giải thích khác cho khái niệm khoảng tin cậy: nó có thể được coi là khoảng của các giá trị tham số MỘT, tương thích với dữ liệu thực nghiệm và không mâu thuẫn với chúng. Thật vậy, nếu chúng ta đồng ý xem xét một sự kiện có xác suất a = 1-p trên thực tế là không thể xảy ra, thì các giá trị của tham số a mà một - một> s phải được thừa nhận là mâu thuẫn với dữ liệu thực nghiệm và những dữ liệu |a - MỘTà t na 2 .
Cho tham số MỘT có một ước tính không thiên vị MỘT. Nếu chúng ta biết luật phân phối số lượng MỘT, nhiệm vụ tìm khoảng tin cậy sẽ rất đơn giản: chỉ cần tìm một giá trị s sao cho
![]()
Khó khăn nằm ở chỗ quy luật phân phối ước lượng MỘT phụ thuộc vào định luật phân bố đại lượng X và do đó, trên các tham số chưa biết của nó (cụ thể là trên chính tham số đó MỘT).
Để giải quyết khó khăn này, bạn có thể sử dụng kỹ thuật gần đúng sau đây: thay thế các tham số chưa biết trong biểu thức của s bằng ước tính điểm của chúng. Với số lượng thí nghiệm tương đối lớn P(khoảng 20...30) kỹ thuật này thường cho kết quả đạt yêu cầu về độ chính xác.
Ví dụ, hãy xem xét bài toán về khoảng tin cậy cho kỳ vọng toán học.
Hãy để nó được sản xuất P X, có đặc điểm là kỳ vọng toán học T và phương sai D- không xác định. Các ước tính sau đây đã thu được cho các tham số này:

Cần xây dựng khoảng tin cậy/p tương ứng với xác suất tin cậy p cho kỳ vọng toán học T số lượng X.
Khi giải bài toán này ta sẽ vận dụng tính chất đại lượng Tđại diện cho tổng P các biến ngẫu nhiên được phân phối độc lập giống hệt nhau Xh và theo định lý giới hạn trung tâm, với một số đủ lớn P luật phân phối của nó gần với chuẩn. Trong thực tế, ngay cả với số lượng số hạng tương đối nhỏ (khoảng 10...20), quy luật phân phối của tổng có thể được coi là gần đúng chuẩn. Chúng ta sẽ giả định rằng giá trị T phân bố theo quy luật thông thường. Các đặc điểm của định luật này - kỳ vọng toán học và phương sai - tương ứng là bằng nhau T Và
(xem chương 13 tiểu mục 13.3). Chúng ta hãy giả sử rằng giá trị D chúng ta biết và sẽ tìm thấy giá trị Ep mà
Sử dụng công thức (6.3.5) của Chương 6, chúng ta biểu thị xác suất ở vế trái của (14.3.5) thông qua hàm phân phối chuẩn
độ lệch chuẩn của ước tính ở đâu T.
Từ phương trình.

tìm giá trị của Sp: 
trong đó arg Ф* (х) là hàm nghịch đảo của Ф* (X), những thứ kia. giá trị của đối số mà hàm phân phối chuẩn bằng X.
phân tán D, qua đó số lượng được thể hiện MỘT 1P, chúng tôi không biết chính xác; làm giá trị gần đúng của nó, bạn có thể sử dụng ước tính D(14.3.4) và đặt xấp xỉ:

Như vậy, bài toán xây dựng khoảng tin cậy đã được giải gần đúng, bằng:
trong đó gp được xác định theo công thức (14.3.7).
Để tránh nội suy ngược trong các bảng của hàm Ф* (l) khi tính s p, nên lập một bảng đặc biệt (Bảng 14.3.1), đưa ra các giá trị của đại lượng
tùy thuộc vào r. Giá trị (p xác định theo định luật thông thường số lượng độ lệch chuẩn phải được vẽ ở bên phải và bên trái tính từ tâm phân tán sao cho xác suất đi vào vùng kết quả là bằng p.
Sử dụng giá trị 7 p, khoảng tin cậy được biểu thị bằng:

Bảng 14.3.1
Ví dụ 1. 20 thí nghiệm được thực hiện trên đại lượng X; kết quả được thể hiện trong bảng. 14.3.2.
Bảng 14.3.2
Cần phải tìm một ước tính từ kỳ vọng toán học của đại lượng X và xây dựng khoảng tin cậy tương ứng với xác suất tin cậy p = 0,8.
Giải pháp. Chúng ta có:

Chọn l: = 10 làm điểm tham chiếu, sử dụng công thức thứ ba (14.2.14) ta tìm được ước lượng không chệch D :

Theo bảng 14.3.1 chúng tôi tìm thấy ![]()
![]()
Giới hạn tin cậy:

Khoảng tin cậy:
![]()
Giá trị tham số T, nằm trong khoảng này phù hợp với số liệu thực nghiệm cho trong bảng. 14.3.2.
Khoảng tin cậy cho phương sai có thể được xây dựng theo cách tương tự.
Hãy để nó được sản xuất P thí nghiệm độc lập trên một biến ngẫu nhiên X với các tham số chưa biết cho cả A và độ phân tán Dđã thu được một ước tính khách quan:


Cần phải xây dựng khoảng tin cậy gần đúng cho phương sai.
Từ công thức (14.3.11) rõ ràng là đại lượng Dđại diện
số lượng P biến ngẫu nhiên có dạng . Những giá trị này không
độc lập, vì bất kỳ trong số chúng bao gồm số lượng T, phụ thuộc vào mọi người khác. Tuy nhiên, có thể thấy rằng với sự gia tăng P luật phân phối tổng của chúng cũng tiến tới mức bình thường. Gần như lúc P= 20...30 thì có thể coi là bình thường rồi.
Giả sử điều này là như vậy và hãy tìm các đặc điểm của định luật này: kỳ vọng toán học và độ phân tán. Kể từ khi đánh giá D- vậy là khách quan rồi M[D] = D.
Tính toán phương sai D Dđược liên kết với các phép tính tương đối phức tạp, vì vậy chúng tôi trình bày biểu thức của nó mà không cần dẫn xuất:
trong đó q 4 là mômen trung tâm thứ tư của độ lớn X.
Để sử dụng biểu thức này, bạn cần thay thế các giá trị \u003d 4 và D(ít nhất là những người thân thiết). Thay vì D bạn có thể sử dụng đánh giá của anh ấy D. Về nguyên tắc, mômen trung tâm thứ tư cũng có thể được thay thế bằng ước tính, ví dụ: giá trị có dạng:

nhưng sự thay thế như vậy sẽ cho độ chính xác cực kỳ thấp, vì nhìn chung, với số lượng thử nghiệm hạn chế, các khoảnh khắc bậc cao được xác định với sai số lớn. Tuy nhiên, trong thực tế thường xảy ra trường hợp loại luật phân bố số lượng X biết trước: chỉ có các tham số của nó là chưa biết. Sau đó bạn có thể thử biểu diễn μ 4 thông qua D.
Hãy lấy trường hợp phổ biến nhất, khi giá trị X phân bố theo quy luật thông thường. Sau đó, mômen trung tâm thứ tư của nó được thể hiện dưới dạng phân tán (xem Chương 6, tiểu mục 6.2);
![]()
và công thức (14.3.12) cho  hoặc
hoặc
Thay thế ẩn số vào (14.3.14) Dđánh giá của anh ấy D, chúng tôi nhận được: từ đâu 
Khoảnh khắc μ 4 có thể được biểu thị thông qua D còn trong một số trường hợp khác, khi việc phân phối giá trị X là không bình thường, nhưng sự xuất hiện của nó được biết đến. Ví dụ, đối với định luật về mật độ đồng đều (xem Chương 5), chúng ta có: 
trong đó (a, P) là khoảng mà định luật được xác định.
Kể từ đây,
![]()
Sử dụng công thức (14.3.12) ta có:  chúng ta tìm thấy khoảng đâu
chúng ta tìm thấy khoảng đâu
Trong trường hợp chưa biết loại định luật phân bố cho đại lượng 26, khi ước tính gần đúng giá trị a/), vẫn nên sử dụng công thức (14.3.16), trừ khi có lý do đặc biệt để tin rằng định luật này rất khác so với bình thường (có độ nhọn dương hoặc âm rõ rệt).
Nếu giá trị gần đúng a/) thu được bằng cách này hay cách khác thì chúng ta có thể xây dựng khoảng tin cậy cho phương sai giống như cách chúng ta xây dựng nó cho kỳ vọng toán học:
trong đó giá trị tùy thuộc vào xác suất p đã cho được tìm thấy theo bảng. 14.3.1.
Ví dụ 2. Tìm khoảng tin cậy xấp xỉ 80% cho phương sai của một biến ngẫu nhiên X theo các điều kiện của ví dụ 1, nếu biết rằng giá trị Xđược phân phối theo một quy luật gần với chuẩn mực.
Giải pháp. Giá trị vẫn giữ nguyên như trong bảng. 14.3.1:
![]()
Theo công thức (14.3.16)

Sử dụng công thức (14.3.18) chúng ta tìm được khoảng tin cậy:
![]()
Khoảng giá trị độ lệch chuẩn tương ứng: (0,21; 0,29).
14.4. Phương pháp chính xác để xây dựng khoảng tin cậy cho các tham số của biến ngẫu nhiên được phân phối theo luật chuẩn tắc
Trong tiểu mục trước, chúng ta đã xem xét các phương pháp gần đúng để xây dựng khoảng tin cậy cho kỳ vọng và phương sai toán học. Ở đây chúng tôi sẽ đưa ra ý tưởng về các phương pháp chính xác để giải quyết cùng một vấn đề. Chúng tôi nhấn mạnh rằng để tìm chính xác khoảng tin cậy nhất thiết phải biết trước dạng luật phân bố của đại lượng X, trong khi đó đối với việc áp dụng các phương pháp gần đúng thì điều này là không cần thiết.
Ý tưởng về các phương pháp chính xác để xây dựng khoảng tin cậy được đưa ra như sau. Bất kỳ khoảng tin cậy nào được tìm thấy từ một điều kiện biểu thị xác suất đáp ứng các bất đẳng thức nhất định, bao gồm ước tính mà chúng ta quan tâm MỘT. Luật phân bổ giá trị MỘT trong trường hợp tổng quát phụ thuộc vào các tham số chưa biết của đại lượng X. Tuy nhiên, đôi khi có thể truyền bất đẳng thức từ một biến ngẫu nhiên MỘTđến một số chức năng khác của các giá trị quan sát được X p X 2, ..., X tr. luật phân phối không phụ thuộc vào các tham số chưa biết mà chỉ phụ thuộc vào số lượng thí nghiệm và loại luật phân phối số lượng X. Những loại biến ngẫu nhiên này đóng một vai trò quan trọng trong thống kê toán học; chúng đã được nghiên cứu chi tiết nhất cho trường hợp phân phối chuẩn của số lượng X.
Ví dụ, người ta đã chứng minh rằng với phân phối chuẩn của giá trị X giá trị ngẫu nhiên

tuân theo cái gọi là Luật phân bố sinh viên Với P- 1 bậc tự do; mật độ của định luật này có dạng

trong đó G(x) là hàm gamma đã biết:

Người ta cũng đã chứng minh rằng biến ngẫu nhiên
có "phân phối%2" với P- 1 bậc tự do (xem Chương 7), mật độ được biểu thị bằng công thức

Không tập trung vào đạo hàm của phân bố (14.4.2) và (14.4.4), chúng tôi sẽ chỉ ra cách chúng có thể được áp dụng khi xây dựng khoảng tin cậy cho các tham số ty D.
Hãy để nó được sản xuất P thí nghiệm độc lập trên một biến ngẫu nhiên X, phân phối chuẩn với các tham số chưa biết ĐẾN.Đối với các tham số này, ước tính đã thu được

Cần xây dựng khoảng tin cậy cho cả hai tham số tương ứng với xác suất tin cậy p.
Trước tiên chúng ta hãy xây dựng khoảng tin cậy cho kỳ vọng toán học. Điều tự nhiên là lấy khoảng này đối xứng với T; gọi s p biểu thị một nửa độ dài của khoảng. Giá trị s p phải được chọn sao cho điều kiện được thỏa mãn
Hãy thử di chuyển về phía bên trái của đẳng thức (14.4.5) từ biến ngẫu nhiên Tđến một biến ngẫu nhiên T,được phân phối theo luật Sinh viên. Để làm điều này, hãy nhân cả hai vế của bất đẳng thức |m-w?|
bằng giá trị dương:  hoặc, sử dụng ký hiệu (14.4.1),
hoặc, sử dụng ký hiệu (14.4.1),

Hãy tìm một số /p sao cho có thể tìm được giá trị /p từ điều kiện

Từ công thức (14.4.2) rõ ràng (1) là hàm chẵn, do đó (14.4.8) cho 
Đẳng thức (14.4.9) xác định giá trị /p tùy thuộc vào p. Nếu bạn có sẵn một bảng các giá trị tích phân

thì giá trị của /p có thể được tìm thấy bằng phép nội suy ngược trong bảng. Tuy nhiên, sẽ thuận tiện hơn nếu lập trước một bảng giá trị /p. Bảng như vậy được đưa ra trong Phụ lục (Bảng 5). Bảng này hiển thị các giá trị tùy thuộc vào mức độ tin cậy p và số bậc tự do P- 1. Đã xác định được /p từ bảng. 5 và giả sử 
chúng ta sẽ tìm thấy một nửa chiều rộng của khoảng tin cậy / p và chính khoảng đó
Ví dụ 1. Thực hiện 5 thí nghiệm độc lập trên một biến ngẫu nhiên X, phân phối chuẩn với các tham số chưa biết T và về. Kết quả thí nghiệm được cho trong bảng. 14.4.1.
Bảng 14.4.1
Tìm xếp hạng T cho kỳ vọng toán học và xây dựng khoảng tin cậy 90% / p cho nó (tức là khoảng tương ứng với xác suất tin cậy p = 0,9).
Giải pháp. Chúng ta có:
![]()
Theo bảng 5 của hồ sơ xin cấp P - 1 = 4 và p = 0,9 ta tìm được ![]() Ở đâu
Ở đâu 
Khoảng tin cậy sẽ là
Ví dụ 2. Đối với điều kiện của ví dụ 1 tiểu mục 14.3, giả sử giá trị X có phân phối chuẩn, hãy tìm khoảng tin cậy chính xác.
Giải pháp. Theo bảng 5 của phụ lục chúng ta thấy khi P - 1 = 19ir =
0,8/p = 1,328; từ đây 
So sánh với cách giải ví dụ 1 của tiểu mục 14.3 (e p = 0,072), chúng tôi tin rằng sự khác biệt là rất không đáng kể. Nếu chúng ta duy trì độ chính xác đến chữ số thập phân thứ hai thì khoảng tin cậy được tìm bằng phương pháp chính xác và gần đúng sẽ trùng nhau:
![]()
Hãy chuyển sang xây dựng khoảng tin cậy cho phương sai. Hãy xem xét công cụ ước tính phương sai không thiên vị

và biểu thị biến ngẫu nhiên D thông qua độ lớn V.(14.4.3), có phân phối x 2 (14.4.4):

Biết định luật phân bố số lượng V, bạn có thể tìm khoảng /(1) mà nó rơi vào với xác suất p cho trước.
Luật phân phối kn_x(v) cường độ I 7 có dạng như hình 2. 14.4.1.

Cơm. 14.4.1
Câu hỏi đặt ra: làm thế nào để chọn khoảng / p? Nếu định luật phân bố độ lớn V. là đối xứng (như luật chuẩn hoặc phân phối Sinh viên), sẽ là điều tự nhiên nếu lấy khoảng /p đối xứng với kỳ vọng toán học. Trong trường hợp này pháp luật k p_x (v) không đối xứng. Chúng ta hãy đồng ý chọn khoảng /p sao cho xác suất của giá trị đó là V. ngoài khoảng bên phải và bên trái (các vùng được tô bóng trong Hình 14.4.1) đều giống nhau và bằng nhau

Để xây dựng một khoảng /p với thuộc tính này, chúng ta sử dụng bảng. 4 ứng dụng: nó chứa số y) như vậy mà
![]()
cho giá trị V, có phân phối x 2 với r bậc tự do. Trong trường hợp của chúng ta r = n- 1. Hãy sửa chữa r = n- 1 và tìm ở hàng tương ứng của bảng. 4 hai ý nghĩa x 2 - cái này tương ứng với xác suất cái kia - xác suất Hãy để chúng tôi biểu thị những điều này
giá trị lúc 2 giờ Và xl? Khoảng thời gian có năm 2, với bên trái của bạn, và y~ cuối bên phải.
Bây giờ chúng ta hãy tìm từ khoảng / p khoảng tin cậy mong muốn /|, cho độ phân tán có ranh giới D, và D2, bao gồm điểm D với xác suất p: ![]()
Chúng ta hãy xây dựng một khoảng / (, = (?> ь А) bao hàm điểm D khi và chỉ khi giá trị V. rơi vào khoảng /r. Hãy chứng minh rằng khoảng

thỏa mãn điều kiện này. Thật vậy, những bất bình đẳng  tương đương với bất đẳng thức
tương đương với bất đẳng thức
![]()
và những bất đẳng thức này được thỏa mãn với xác suất p. Như vậy, khoảng tin cậy cho phương sai đã được tìm thấy và được biểu thị bằng công thức (14.4.13).
Ví dụ 3. Tìm khoảng tin cậy cho phương sai theo điều kiện của ví dụ 2 mục 14.3, nếu biết giá trị X phân phối chuẩn.
Giải pháp. Chúng ta có ![]() . Theo bảng 4 phụ lục
. Theo bảng 4 phụ lục
chúng tôi tìm thấy ở r = n - 1 = 19

Sử dụng công thức (14.4.13) chúng ta tìm được khoảng tin cậy cho phương sai ![]()
Khoảng tương ứng cho độ lệch chuẩn là (0,21; 0,32). Khoảng này chỉ vượt quá một chút khoảng (0,21; 0,29) thu được trong ví dụ 2 của tiểu mục 14.3 bằng phương pháp gần đúng.
- Hình 14.3.1 xét một khoảng tin cậy đối xứng về a. Nói chung, như chúng ta sẽ thấy sau, điều này là không cần thiết.
Mục tiêu– Dạy học sinh các thuật toán tính khoảng tin cậy của các tham số thống kê.
Khi xử lý dữ liệu thống kê, giá trị trung bình số học được tính toán, hệ số biến thiên, hệ số tương quan, tiêu chí chênh lệch và thống kê điểm khác sẽ nhận được giới hạn tin cậy về mặt định lượng, cho biết các biến động có thể có của chỉ báo theo các hướng nhỏ hơn và lớn hơn trong khoảng tin cậy.
Ví dụ 3.1
.
Sự phân bố canxi trong huyết thanh khỉ, như đã xác định trước đó, được đặc trưng bởi các chỉ số mẫu sau: = 11,94 mg%;  = 0,127 mg%; N= 100. Cần xác định khoảng tin cậy cho trung bình chung (
= 0,127 mg%; N= 100. Cần xác định khoảng tin cậy cho trung bình chung (  ) với xác suất tin cậy P
= 0,95.
) với xác suất tin cậy P
= 0,95.
Trung bình chung được xác định với một xác suất nhất định trong khoảng:
 , Ở đâu
, Ở đâu 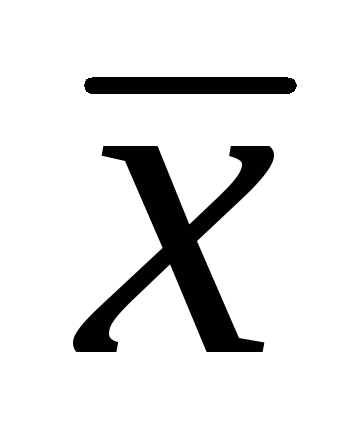 - trung bình số học mẫu; t– Bài kiểm tra của học sinh;
- trung bình số học mẫu; t– Bài kiểm tra của học sinh;  - sai số của giá trị trung bình số học.
- sai số của giá trị trung bình số học.
Sử dụng bảng “Giá trị t-test của sinh viên”, chúng tôi tìm thấy giá trị
 với xác suất tin cậy là 0,95 và số bậc tự do k= 100-1 = 99. Nó bằng 1,982. Cùng với các giá trị trung bình số học và sai số thống kê, chúng tôi thay thế nó vào công thức:
với xác suất tin cậy là 0,95 và số bậc tự do k= 100-1 = 99. Nó bằng 1,982. Cùng với các giá trị trung bình số học và sai số thống kê, chúng tôi thay thế nó vào công thức:
hoặc 11,69  12,19
12,19
Do đó, với xác suất 95%, có thể nói rằng trung bình chung của phân phối chuẩn này là từ 11,69 đến 12,19 mg%.
Ví dụ 3.2
. Xác định ranh giới của khoảng tin cậy 95% cho phương sai chung (  ) sự phân bố canxi trong máu khỉ, nếu biết được điều đó
) sự phân bố canxi trong máu khỉ, nếu biết được điều đó  = 1,60, tại N
= 100.
= 1,60, tại N
= 100.
Để giải quyết vấn đề bạn có thể sử dụng công thức sau:
Ở đâu  - sai số thống kê về độ phân tán.
- sai số thống kê về độ phân tán.
Chúng tôi tìm thấy lỗi phương sai lấy mẫu bằng công thức:  . Nó bằng 0,11. Nghĩa t- tiêu chí có xác suất tin cậy là 0,95 và số bậc tự do k= 100–1 = 99 đã được biết từ ví dụ trước.
. Nó bằng 0,11. Nghĩa t- tiêu chí có xác suất tin cậy là 0,95 và số bậc tự do k= 100–1 = 99 đã được biết từ ví dụ trước.
Hãy sử dụng công thức và nhận được:
hoặc 1,38  1,82
1,82
Chính xác hơn, khoảng tin cậy của phương sai tổng quát có thể được xây dựng bằng cách sử dụng  (chi-vuông) - Kiểm tra Pearson. Các điểm tới hạn của tiêu chí này được đưa ra trong một bảng đặc biệt. Khi sử dụng tiêu chí
(chi-vuông) - Kiểm tra Pearson. Các điểm tới hạn của tiêu chí này được đưa ra trong một bảng đặc biệt. Khi sử dụng tiêu chí  Để xây dựng khoảng tin cậy, mức ý nghĩa hai phía được sử dụng. Đối với giới hạn dưới, mức ý nghĩa được tính bằng công thức
Để xây dựng khoảng tin cậy, mức ý nghĩa hai phía được sử dụng. Đối với giới hạn dưới, mức ý nghĩa được tính bằng công thức  , cho phần trên cùng –
, cho phần trên cùng –  . Ví dụ, đối với mức độ tin cậy
. Ví dụ, đối với mức độ tin cậy  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. Theo đó, theo bảng phân bố giá trị tới hạn
= 0,990. Theo đó, theo bảng phân bố giá trị tới hạn  , với mức độ tin cậy được tính toán và số bậc tự do k= 100 – 1= 99, tìm các giá trị
, với mức độ tin cậy được tính toán và số bậc tự do k= 100 – 1= 99, tìm các giá trị  Và
Và  . Chúng tôi nhận được
. Chúng tôi nhận được  bằng 135,80 và
bằng 135,80 và  bằng 70,06.
bằng 70,06.
Để tìm giới hạn tin cậy cho phương sai tổng quát bằng cách sử dụng  Hãy sử dụng các công thức: cho ranh giới dưới
Hãy sử dụng các công thức: cho ranh giới dưới 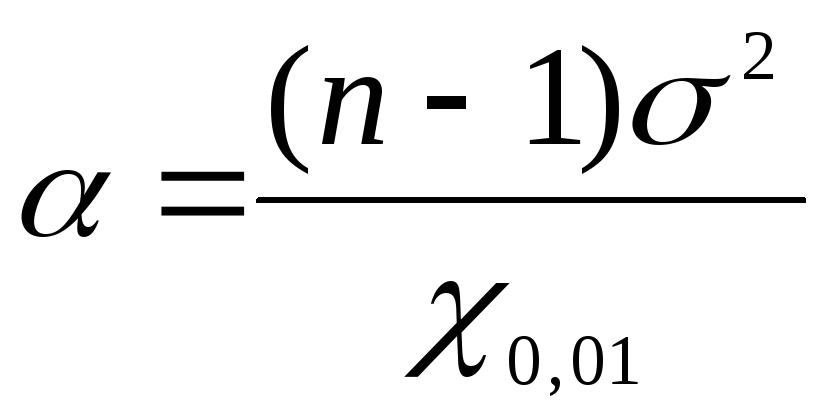 , cho giới hạn trên
, cho giới hạn trên  . Hãy thay thế các giá trị tìm được cho dữ liệu bài toán
. Hãy thay thế các giá trị tìm được cho dữ liệu bài toán  thành các công thức:
thành các công thức:  =
1,17;
=
1,17; = 2,26. Như vậy, với xác suất tin cậy P= 0,99 hoặc 99% phương sai chung sẽ nằm trong khoảng từ 1,17 đến 2,26 mg%.
= 2,26. Như vậy, với xác suất tin cậy P= 0,99 hoặc 99% phương sai chung sẽ nằm trong khoảng từ 1,17 đến 2,26 mg%.
Ví dụ 3.3 . Trong số 1000 hạt lúa mì từ lô được nhận tại thang máy, có 120 hạt bị nhiễm nấm cựa gà. Cần phải xác định ranh giới có thể xảy ra của tỷ lệ chung các hạt bị nhiễm bệnh trong một mẻ lúa mì nhất định.
Nên xác định giới hạn tin cậy cho phần chung cho tất cả các giá trị có thể có của nó bằng công thức:
 ,
,
Ở đâu N - số lượng quan sát; tôi- kích thước tuyệt đối của một trong các nhóm; t- độ lệch chuẩn hóa.
Tỷ lệ mẫu hạt bị nhiễm bệnh là  hoặc 12%. Với xác suất tin cậy R= độ lệch chuẩn hóa 95% ( t-Bài kiểm tra của học sinh tại k
=
hoặc 12%. Với xác suất tin cậy R= độ lệch chuẩn hóa 95% ( t-Bài kiểm tra của học sinh tại k
=
 )t
= 1,960.
)t
= 1,960.
Chúng tôi thay thế dữ liệu có sẵn vào công thức:
Do đó ranh giới của khoảng tin cậy bằng  = 0,122–0,041 = 0,081, hay 8,1%;
= 0,122–0,041 = 0,081, hay 8,1%;  = 0,122 + 0,041 = 0,163, hay 16,3%.
= 0,122 + 0,041 = 0,163, hay 16,3%.
Như vậy, với xác suất tin cậy là 95% có thể khẳng định rằng tỷ lệ chung của hạt bị nhiễm bệnh là từ 8,1 đến 16,3%.
Ví dụ 3.4 . Hệ số biến thiên đặc trưng cho sự biến thiên canxi (mg%) trong huyết thanh khỉ là 10,6%. Cỡ mẫu N= 100. Cần xác định ranh giới của khoảng tin cậy 95% cho tham số chung CV.
Giới hạn của khoảng tin cậy đối với hệ số biến thiên chung CV được xác định bởi các công thức sau:
 Và
Và  , Ở đâu K
giá trị trung gian được tính theo công thức
, Ở đâu K
giá trị trung gian được tính theo công thức  .
.
Biết rằng với xác suất tin cậy R= 95% độ lệch chuẩn hóa (Bài kiểm tra của học sinh tại k
=
 )t
= 1,960, trước tiên hãy tính giá trị ĐẾN:
)t
= 1,960, trước tiên hãy tính giá trị ĐẾN:
 .
.
 hoặc 9,3%
hoặc 9,3%
 hoặc 12,3%
hoặc 12,3%
Như vậy, hệ số biến thiên chung với độ tin cậy 95% nằm trong khoảng từ 9,3 đến 12,3%. Với các mẫu lặp lại, hệ số biến thiên sẽ không vượt quá 12,3% và không dưới 9,3% ở 95/100 trường hợp.
Các câu hỏi để tự kiểm soát:

Vấn đề cho giải pháp độc lập.
1. Tỷ lệ chất béo trong sữa trung bình trong thời kỳ nuôi sữa của bò lai Kholmogory như sau: 3,4; 3,6; 3,2; 3.1; 2,9; 3,7; 3,2; 3,6; 4.0; 3,4; 4.1; 3,8; 3,4; 4.0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Thiết lập khoảng tin cậy cho giá trị trung bình chung ở mức độ tin cậy 95% (20 điểm).
2. Trên 400 cây lúa mạch đen lai, trung bình 70,5 ngày sau khi gieo, những bông hoa đầu tiên xuất hiện. Độ lệch chuẩn là 6,9 ngày. Xác định sai số của giá trị trung bình và khoảng tin cậy đối với giá trị trung bình tổng quát và phương sai ở mức ý nghĩa W= 0,05 và W= 0,01 (25 điểm).
3. Khi nghiên cứu chiều dài lá của 502 mẫu dâu tây vườn, thu được số liệu sau:
 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  =± 0,06 cm, xác định khoảng tin cậy cho trung bình số học của tổng thể với mức ý nghĩa 0,01; 0,02; 0,05. (25 điểm).
=± 0,06 cm, xác định khoảng tin cậy cho trung bình số học của tổng thể với mức ý nghĩa 0,01; 0,02; 0,05. (25 điểm).
4. Trong một nghiên cứu trên 150 người đàn ông trưởng thành, chiều cao trung bình là 167 cm và σ = 6 cm. Giới hạn của giá trị trung bình tổng quát và độ phân tán tổng quát với xác suất tin cậy là 0,99 và 0,95 là bao nhiêu? (25 điểm).
5. Sự phân bố canxi trong huyết thanh khỉ được đặc trưng bởi các chỉ số chọn lọc sau:
 = 11,94 mg%, σ
= 1,27, N
= 100. Xây dựng khoảng tin cậy 95% cho giá trị trung bình chung của phân phối này. Tính hệ số biến thiên (25 điểm).
= 11,94 mg%, σ
= 1,27, N
= 100. Xây dựng khoảng tin cậy 95% cho giá trị trung bình chung của phân phối này. Tính hệ số biến thiên (25 điểm).
6. Nghiên cứu hàm lượng nitơ tổng số trong huyết tương của chuột bạch tạng ở tuổi 37 và 180 ngày. Kết quả được biểu thị bằng gam trên 100 cm 3 huyết tương. Ở tuổi 37 ngày, 9 chuột có tỷ lệ: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Ở tuổi 180 ngày, 8 con chuột có: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Đặt khoảng tin cậy cho chênh lệch ở mức tin cậy 0,95 (50 điểm).
7. Xác định ranh giới của khoảng tin cậy 95% cho phương sai chung của phân bố canxi (mg%) trong huyết thanh khỉ, nếu đối với phân bố này cỡ mẫu là n = 100, sai số thống kê của phương sai mẫu S σ 2 = 1,60 (40 điểm).
8. Xác định ranh giới của khoảng tin cậy 95% cho phương sai chung của sự phân bố của 40 bông lúa mì dọc theo chiều dài (σ 2 = 40,87 mm 2). (25 điểm).
9. Hút thuốc được coi là yếu tố chính dẫn đến bệnh phổi tắc nghẽn. Hút thuốc thụ động không được coi là một yếu tố như vậy. Các nhà khoa học nghi ngờ sự vô hại của việc hút thuốc thụ động và đã kiểm tra tình trạng đường thở của những người không hút thuốc, những người hút thuốc thụ động và chủ động. Để mô tả trạng thái của đường hô hấp, chúng tôi lấy một trong những chỉ số về chức năng hô hấp bên ngoài - tốc độ dòng thể tích tối đa ở giữa thì thở ra. Chỉ số này giảm là dấu hiệu tắc nghẽn đường thở. Số liệu khảo sát được thể hiện trong bảng.
|
Số người được khám |
Tốc độ dòng khí giữa thì thở ra tối đa, l/s |
||
|
Độ lệch chuẩn |
|||
|
người không hút thuốc |
|||
|
làm việc ở khu vực cấm hút thuốc | |||
|
làm việc trong phòng đầy khói | |||
|
Hút thuốc |
|||
|
hút một ít thuốc lá | |||
|
số người hút thuốc lá trung bình | |||
|
hút một số lượng lớn thuốc lá | |||
Sử dụng dữ liệu bảng, hãy tìm khoảng tin cậy 95% cho giá trị trung bình tổng thể và phương sai tổng thể cho mỗi nhóm. Sự khác biệt giữa các nhóm là gì? Trình bày kết quả bằng đồ họa (25 điểm).
10. Xác định ranh giới của khoảng tin cậy 95% và 99% cho phương sai chung về số lượng heo con ở 64 lứa đẻ, nếu sai số thống kê của phương sai mẫu S σ 2 = 8,25 (30 điểm).
11. Được biết, trọng lượng trung bình của thỏ là 2,1 kg. Xác định ranh giới của khoảng tin cậy 95% và 99% cho giá trị trung bình chung và phương sai tại N= 30, σ = 0,56 kg (25 điểm).
12. Hàm lượng hạt của bắp được đo cho 100 bắp ( X), chiều dài tai ( Y) và khối lượng hạt trong bông ( Z). Tìm khoảng tin cậy cho giá trị trung bình tổng quát và phương sai tại P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 nếu
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064. (25 điểm).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064. (25 điểm).
13. Trong 100 bông lúa mì mùa đông được chọn ngẫu nhiên, số lượng bông con được đếm. Dân số mẫu được đặc trưng bởi các chỉ số sau:
 = 15 bông con và σ = 2,28 chiếc. Xác định độ chính xác của kết quả trung bình thu được (
= 15 bông con và σ = 2,28 chiếc. Xác định độ chính xác của kết quả trung bình thu được (  ) và xây dựng khoảng tin cậy cho giá trị trung bình và phương sai chung ở mức ý nghĩa 95% và 99% (30 điểm).
) và xây dựng khoảng tin cậy cho giá trị trung bình và phương sai chung ở mức ý nghĩa 95% và 99% (30 điểm).
14. Số xương sườn trên vỏ nhuyễn thể hóa thạch orthambonit thư pháp:
Người ta biết rằng N = 19, σ = 4,25. Xác định ranh giới của khoảng tin cậy đối với giá trị trung bình tổng quát và phương sai tổng quát ở mức ý nghĩa W = 0,01 (25 điểm).
15. Để xác định sản lượng sữa ở một trang trại chăn nuôi bò sữa thương mại, năng suất của 15 con bò được xác định hàng ngày. Theo số liệu trong năm, trung bình mỗi con bò cho lượng sữa mỗi ngày như sau (l): 22; 19; 25; 20; 27; 17; ba mươi; 21; 18; 24; 26; 23; 25; 20; 24. Xây dựng khoảng tin cậy cho phương sai tổng quát và trung bình số học. Chúng ta có thể mong đợi sản lượng sữa trung bình hàng năm của mỗi con bò là 10.000 lít không? (50 điểm).
16. Để xác định năng suất lúa mì trung bình của doanh nghiệp nông nghiệp, việc cắt cỏ được thực hiện trên các ô thử nghiệm có diện tích 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 và 2 ha. Năng suất (c/ha) từ các lô là 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 tương ứng. Xây dựng khoảng tin cậy cho phương sai tổng quát và trung bình số học. Chúng ta có thể kỳ vọng rằng năng suất nông nghiệp trung bình sẽ là 42 c/ha không? (50 điểm).
Có hai loại ước tính trong thống kê: điểm và khoảng. Ước tính điểm là một thống kê mẫu duy nhất được sử dụng để ước tính một tham số tổng thể. Ví dụ, trung bình mẫu là ước tính điểm của kỳ vọng toán học của tổng thể và phương sai mẫu S 2- ước tính điểm của phương sai dân số σ 2. người ta đã chứng minh rằng giá trị trung bình mẫu là ước tính không thiên vị về kỳ vọng toán học của tổng thể. Giá trị trung bình mẫu được gọi là không thiên vị vì giá trị trung bình của tất cả các giá trị trung bình mẫu (có cùng cỡ mẫu) N) bằng với kỳ vọng toán học của dân số nói chung.
Để có sự khác biệt về mẫu S 2đã trở thành một ước tính không thiên vị của phương sai tổng thể σ 2, mẫu số của phương sai mẫu phải được đặt bằng N – 1 , nhưng không N. Nói cách khác, phương sai tổng thể là giá trị trung bình của tất cả các phương sai mẫu có thể có.
Khi ước lượng các thông số tổng thể, cần lưu ý rằng các số liệu thống kê mẫu như , phụ thuộc vào mẫu cụ thể. Để tính đến thực tế này, để có được ước lượng khoảng kỳ vọng toán học của dân số nói chung, phân tích sự phân bố của các phương tiện mẫu (để biết thêm chi tiết, xem). Khoảng được xây dựng được đặc trưng bởi một mức độ tin cậy nhất định, biểu thị xác suất mà tham số tổng thể thực được ước tính chính xác. Khoảng tin cậy tương tự có thể được sử dụng để ước tính tỷ lệ của một đặc tính R và khối dân cư phân bố chủ yếu.
Tải xuống ghi chú ở định dạng hoặc, ví dụ ở định dạng
Xây dựng khoảng tin cậy cho kỳ vọng toán học của tổng thể với độ lệch chuẩn đã biết
Xây dựng khoảng tin cậy cho tỷ lệ đặc điểm trong tổng thể
Phần này mở rộng khái niệm khoảng tin cậy cho dữ liệu phân loại. Điều này cho phép chúng ta ước tính tỷ lệ đặc điểm trong dân số R sử dụng chia sẻ mẫu RS= X/N. Như đã chỉ ra, nếu số lượng NR Và N(1 – p) vượt quá số 5 thì phân phối nhị thức có thể xấp xỉ như bình thường. Do đó, để ước tính tỷ lệ của một đặc điểm trong dân số R có thể xây dựng một khoảng có mức độ tin cậy bằng (1 – α)х100%.

Ở đâu PS- tỷ lệ mẫu của đặc tính bằng X/N, I E. số lần thành công chia cho cỡ mẫu, R- tỷ lệ đặc điểm trong dân số nói chung, Z- giá trị tới hạn của phân phối chuẩn chuẩn hóa, N- cỡ mẫu.
Ví dụ 3. Giả sử một mẫu gồm 100 hóa đơn được điền trong tháng trước được trích xuất từ hệ thống thông tin. Giả sử có 10 hóa đơn trong số này được biên soạn có lỗi. Như vậy, R= 10/100 = 0,1. Mức độ tin cậy 95% tương ứng với giá trị tới hạn Z = 1,96.
Như vậy, xác suất có sai sót từ 4,12% đến 15,88% hóa đơn là 95%.
Đối với một cỡ mẫu nhất định, khoảng tin cậy chứa tỷ lệ đặc tính trong tổng thể có vẻ rộng hơn so với biến ngẫu nhiên liên tục. Điều này là do các phép đo của một biến ngẫu nhiên liên tục chứa nhiều thông tin hơn các phép đo dữ liệu phân loại. Nói cách khác, dữ liệu phân loại chỉ lấy hai giá trị sẽ không chứa đủ thông tin để ước tính các tham số phân phối của chúng.
TRONGtính toán ước tính được trích xuất từ một quần thể hữu hạn
Ước tính kỳ vọng toán học. Hệ số hiệu chỉnh cho quần thể cuối cùng ( fpc) được sử dụng để giảm sai số chuẩn đi một hệ số. Khi tính toán khoảng tin cậy cho ước tính tham số tổng thể, hệ số hiệu chỉnh được áp dụng trong trường hợp mẫu được rút ra mà không được trả về. Do đó, khoảng tin cậy cho kỳ vọng toán học có mức tin cậy bằng (1 – α)х100%, được tính theo công thức:

Ví dụ 4.Để minh họa việc sử dụng hệ số hiệu chỉnh cho một tập hợp hữu hạn, chúng ta hãy quay lại bài toán tính khoảng tin cậy cho số lượng hóa đơn trung bình, được thảo luận ở trên trong Ví dụ 3. Giả sử rằng một công ty phát hành 5.000 hóa đơn mỗi tháng và X̅= 110,27 đô la, S= 28,95 USD, N = 5000, N = 100, α = 0,05, t 99 = 1,9842. Sử dụng công thức (6), chúng tôi có được:
Ước tính thị phần của một tính năng. Khi chọn không trả về, khoảng tin cậy cho tỷ lệ thuộc tính có mức độ tin cậy bằng (1 – α)х100%, được tính theo công thức:

Khoảng tin cậy và các vấn đề đạo đức
Khi lấy mẫu dân số và đưa ra kết luận thống kê, các vấn đề đạo đức thường nảy sinh. Vấn đề chính là khoảng tin cậy và ước tính điểm của số liệu thống kê mẫu giống nhau như thế nào. Việc xuất bản các ước tính điểm mà không chỉ định khoảng tin cậy liên quan (thường ở mức độ tin cậy 95%) và cỡ mẫu mà chúng được lấy từ đó có thể tạo ra sự nhầm lẫn. Điều này có thể tạo cho người dùng ấn tượng rằng ước lượng điểm chính xác là những gì anh ta cần để dự đoán các đặc tính của toàn bộ tổng thể. Vì vậy, cần phải hiểu rằng trong bất kỳ nghiên cứu nào cũng không nên tập trung vào ước tính điểm mà là ước tính khoảng. Ngoài ra, cần đặc biệt chú ý đến việc lựa chọn đúng cỡ mẫu.
Thông thường, đối tượng của thao tác thống kê là kết quả của các cuộc khảo sát xã hội học về người dân về một số vấn đề chính trị nhất định. Đồng thời, kết quả khảo sát được đăng trên trang nhất của các tờ báo, lỗi lấy mẫu và phương pháp phân tích thống kê được đăng ở đâu đó ở giữa. Để chứng minh tính hợp lệ của các ước tính điểm thu được, cần chỉ ra cỡ mẫu trên cơ sở chúng thu được, ranh giới của khoảng tin cậy và mức ý nghĩa của nó.
Ghi chú tiếp theo
Tài liệu từ cuốn sách Levin và cộng sự Thống kê dành cho nhà quản lý được sử dụng. – M.: Williams, 2004. – tr. 448–462
Định lý giới hạn trung tâm tuyên bố rằng với cỡ mẫu đủ lớn, phân phối mẫu của phương tiện có thể gần đúng bằng phân phối chuẩn. Tính chất này không phụ thuộc vào kiểu phân bố dân cư.
Và những thứ khác. Tất cả chúng đều là ước tính về các điểm tương tự về mặt lý thuyết của chúng, có thể thu được nếu không phải là một mẫu mà là một tổng thể chung. Nhưng than ôi, dân số nói chung rất đắt đỏ và thường không thể tiếp cận được.
Khái niệm ước lượng khoảng
Bất kỳ ước tính mẫu nào cũng có mức chênh lệch nào đó, bởi vì là một biến ngẫu nhiên tùy thuộc vào các giá trị trong một mẫu cụ thể. Do đó, để có kết luận thống kê đáng tin cậy hơn, người ta không chỉ nên biết ước tính điểm mà còn cả khoảng thời gian có xác suất cao. γ (gamma) bao gồm chỉ số được đánh giá θ (theta).
Về mặt hình thức, đây là hai giá trị như vậy (thống kê) T 1 (X) Và T 2 (X), Cái gì T 1< T 2 , mà tại một mức xác suất nhất định γ điều kiện được đáp ứng:
Nói tóm lại, có khả năng γ hoặc nhiều hơn chỉ báo thực sự nằm giữa các điểm T 1 (X) Và T 2 (X), được gọi là giới hạn dưới và giới hạn trên khoảng tin cậy.
Một trong những điều kiện để xây dựng khoảng tin cậy là độ hẹp tối đa của nó, tức là nó phải càng ngắn càng tốt. Mong muốn đó là điều hết sức tự nhiên, bởi vì... nhà nghiên cứu cố gắng định vị chính xác hơn vị trí của tham số mong muốn.
Theo đó, khoảng tin cậy phải bao hàm xác suất tối đa của phân bố. và bản thân việc đánh giá phải ở trung tâm.
![]()
Nghĩa là, xác suất sai lệch (của chỉ số thực so với ước tính) trở lên bằng xác suất sai lệch đi xuống. Cũng cần lưu ý rằng đối với phân bố bất đối xứng, khoảng ở bên phải không bằng khoảng ở bên trái.
Hình trên cho thấy rõ rằng xác suất tin cậy càng lớn thì khoảng - mối quan hệ trực tiếp càng rộng.
Đây là phần giới thiệu ngắn gọn về lý thuyết ước lượng khoảng của các tham số chưa biết. Hãy chuyển sang tìm giới hạn tin cậy cho kỳ vọng toán học.
Khoảng tin cậy cho kỳ vọng toán học
Nếu dữ liệu gốc được phân phối trên , thì giá trị trung bình sẽ là giá trị bình thường. Điều này tuân theo quy tắc rằng sự kết hợp tuyến tính của các giá trị bình thường cũng có phân phối chuẩn. Do đó, để tính xác suất, chúng ta có thể sử dụng bộ máy toán học của định luật phân phối chuẩn.
Tuy nhiên, điều này đòi hỏi phải biết hai tham số - kỳ vọng và phương sai, thường không xác định được. Tất nhiên, bạn có thể sử dụng các ước tính thay vì các tham số (trung bình số học và ), nhưng khi đó sự phân bố của giá trị trung bình sẽ không hoàn toàn bình thường, nó sẽ hơi dẹt xuống. Thực tế này đã được công dân William Gosset đến từ Ireland ghi nhận một cách khéo léo, công bố phát hiện của ông trên tạp chí Biometrica số tháng 3 năm 1908. Vì mục đích giữ bí mật, Gosset đã tự ký tên là Sinh viên. Đây là cách phân phối t của Sinh viên xuất hiện.
Tuy nhiên, phân bố chuẩn của dữ liệu, được K. Gauss sử dụng để phân tích sai số trong các quan sát thiên văn, là cực kỳ hiếm trong đời sống trên trái đất và khá khó thiết lập (cần khoảng 2 nghìn quan sát để có độ chính xác cao). Vì vậy, tốt nhất nên loại bỏ giả định về tính chuẩn và sử dụng các phương pháp không phụ thuộc vào sự phân bố của dữ liệu gốc.
Câu hỏi đặt ra: phân bố của giá trị trung bình số học là gì nếu nó được tính từ dữ liệu của một phân phối chưa biết? Câu trả lời được đưa ra bởi lý thuyết xác suất nổi tiếng Định lý giới hạn trung tâm(CPT). Trong toán học, có một số biến thể của nó (các công thức đã được cải tiến qua nhiều năm), nhưng tất cả chúng, nói một cách đại khái, đều rút ra kết luận rằng tổng của một số lượng lớn các biến ngẫu nhiên độc lập tuân theo quy luật phân phối chuẩn.
Khi tính giá trị trung bình số học, tổng các biến ngẫu nhiên được sử dụng. Từ đây hóa ra trung bình số học có phân phối chuẩn, trong đó kỳ vọng là kỳ vọng của dữ liệu gốc và phương sai là .
Những người thông minh biết cách chứng minh CLT, nhưng chúng tôi sẽ xác minh điều này với sự trợ giúp của một thử nghiệm được thực hiện trong Excel. Hãy mô phỏng một mẫu gồm 50 biến ngẫu nhiên phân bố đều (sử dụng hàm RANDBETWEEN trong Excel). Sau đó, chúng tôi sẽ tạo 1000 mẫu như vậy và tính giá trị trung bình số học cho mỗi mẫu. Hãy nhìn vào sự phân bố của họ.

Có thể thấy rằng sự phân bố của số trung bình gần với quy luật bình thường. Nếu kích thước và số lượng mẫu được làm lớn hơn nữa thì độ tương tự sẽ càng tốt hơn.
Bây giờ chúng ta đã tận mắt chứng kiến tính hợp lệ của CLT, chúng ta có thể, bằng cách sử dụng , tính khoảng tin cậy cho giá trị trung bình số học, bao gồm giá trị trung bình thực hoặc kỳ vọng toán học với một xác suất cho trước.
Để thiết lập giới hạn trên và giới hạn dưới, bạn cần biết các tham số của phân phối chuẩn. Theo quy định, không có, vì vậy ước tính được sử dụng: trung bình số học Và phương sai mẫu. Tôi nhắc lại, phương pháp này chỉ cho kết quả gần đúng với các mẫu lớn. Khi mẫu nhỏ, người ta thường khuyên nên sử dụng phân phối Sinh viên. Đừng tin điều đó! Phân phối Sinh viên cho giá trị trung bình chỉ xảy ra khi dữ liệu gốc được phân phối bình thường, nghĩa là hầu như không bao giờ. Vì vậy, tốt hơn là bạn nên đặt ngay một ngưỡng tối thiểu cho lượng dữ liệu cần thiết và sử dụng các phương pháp tiệm cận chính xác. Họ nói 30 quan sát là đủ. Lấy 50 - bạn sẽ không sai.
![]()
T 1.2- giới hạn dưới và trên của khoảng tin cậy
– trung bình số học mẫu
s 0– độ lệch chuẩn của mẫu (không thiên vị)
N - cỡ mẫu
γ – xác suất tin cậy (thường bằng 0,9, 0,95 hoặc 0,99)
c γ =Φ -1 ((1+γ)/2)– giá trị nghịch đảo của hàm phân phối chuẩn chuẩn hóa. Nói một cách đơn giản, đây là số sai số chuẩn từ trung bình số học đến giới hạn dưới hoặc giới hạn trên (ba xác suất này tương ứng với các giá trị 1,64, 1,96 và 2,58).
Bản chất của công thức là giá trị trung bình số học được lấy và sau đó một số tiền nhất định được đặt sang một bên ( với γ) sai số chuẩn ( s 0 /√n). Mọi thứ đều được biết, hãy lấy nó và xem xét nó.
Trước khi máy tính cá nhân được sử dụng rộng rãi, chúng thường thu được các giá trị của hàm phân phối chuẩn và nghịch đảo của nó. Ngày nay chúng vẫn được sử dụng nhưng sẽ hiệu quả hơn nếu sử dụng các công thức Excel có sẵn. Tất cả các phần tử từ công thức trên ( , và ) có thể được tính toán dễ dàng trong Excel. Nhưng có một công thức làm sẵn để tính khoảng tin cậy - TRUST.NORM. Cú pháp của nó như sau.
CONFIDENCE.NORM(alpha;standard_off;size)
alpha– mức ý nghĩa hoặc mức độ tin cậy, trong ký hiệu được chấp nhận ở trên bằng 1- γ, nghĩa là xác suất mà toán họckỳ vọng sẽ nằm ngoài khoảng tin cậy. Với mức độ tin cậy là 0,95, alpha là 0,05, v.v.
tiêu chuẩn_tắt– độ lệch chuẩn của dữ liệu mẫu. Không cần tính sai số chuẩn, bản thân Excel sẽ chia cho căn của n.
kích cỡ– cỡ mẫu (n).
Kết quả của hàm CONFIDENCE NORM là số hạng thứ hai trong công thức tính khoảng tin cậy, tức là. nửa quãng Theo đó, điểm dưới và điểm trên là giá trị trung bình ± giá trị thu được.
Vì vậy, có thể xây dựng một thuật toán phổ quát để tính khoảng tin cậy cho giá trị trung bình số học, thuật toán này không phụ thuộc vào sự phân bố của dữ liệu gốc. Cái giá phải trả cho tính phổ quát là bản chất tiệm cận của nó, tức là. nhu cầu sử dụng mẫu tương đối lớn. Tuy nhiên, trong thời đại công nghệ hiện đại, việc thu thập lượng dữ liệu cần thiết thường không khó.
Kiểm tra các giả thuyết thống kê bằng khoảng tin cậy
(mô-đun 111)
Một trong những vấn đề chính được giải quyết trong thống kê là. Bản chất của nó ngắn gọn như sau. Ví dụ, một giả định được đưa ra là kỳ vọng của dân số nói chung bằng một giá trị nào đó. Sau đó, việc phân phối các phương tiện mẫu có thể được quan sát cho một kỳ vọng nhất định sẽ được xây dựng. Tiếp theo, họ xem xét mức trung bình thực nằm ở đâu trong phân bố có điều kiện này. Nếu nó vượt quá giới hạn có thể chấp nhận được thì rất khó xảy ra sự xuất hiện của mức trung bình như vậy và nếu thí nghiệm được lặp lại một lần thì điều đó gần như không thể xảy ra, điều này mâu thuẫn với giả thuyết đưa ra và giả thuyết này đã bị bác bỏ thành công. Nếu mức trung bình không vượt quá mức tới hạn thì giả thuyết không bị bác bỏ (nhưng cũng không được chứng minh!).
Vì vậy, với sự trợ giúp của khoảng tin cậy, trong trường hợp kỳ vọng của chúng tôi, bạn cũng có thể kiểm tra một số giả thuyết. Nó rất dễ làm. Giả sử trung bình số học của một mẫu nhất định bằng 100. Giả thuyết được kiểm tra rằng giá trị kỳ vọng là 90. Nghĩa là, nếu chúng ta đặt câu hỏi một cách nguyên thủy, nó sẽ giống như thế này: liệu điều đó có đúng không? giá trị trung bình bằng 90 thì giá trị trung bình quan sát được là 100?
Để trả lời câu hỏi này, bạn sẽ cần thêm thông tin về độ lệch chuẩn và cỡ mẫu. Giả sử độ lệch chuẩn là 30 và số lượng quan sát là 64 (để dễ dàng trích ra gốc). Khi đó sai số chuẩn của giá trị trung bình là 30/8 hoặc 3,75. Để tính khoảng tin cậy 95%, bạn sẽ cần thêm hai sai số chuẩn vào mỗi bên của giá trị trung bình (chính xác hơn là 1,96). Khoảng tin cậy sẽ xấp xỉ 100±7,5 hoặc từ 92,5 đến 107,5.
Lý luận sâu hơn như sau. Nếu giá trị đang được kiểm tra nằm trong khoảng tin cậy thì nó không mâu thuẫn với giả thuyết, bởi vì nằm trong giới hạn dao động ngẫu nhiên (với xác suất 95%). Nếu điểm được kiểm tra nằm ngoài khoảng tin cậy thì xác suất xảy ra sự kiện như vậy là rất nhỏ, trong mọi trường hợp đều dưới mức chấp nhận được. Điều này có nghĩa là giả thuyết bị bác bỏ vì mâu thuẫn với dữ liệu quan sát được. Trong trường hợp của chúng tôi, giả thuyết về giá trị kỳ vọng nằm ngoài khoảng tin cậy (giá trị được kiểm tra là 90 không nằm trong khoảng 100±7,5), vì vậy nó nên bị bác bỏ. Trả lời câu hỏi sơ khai ở trên, cần phải nói: không, không thể, trong mọi trường hợp, điều này cực kỳ hiếm khi xảy ra. Thông thường, chúng chỉ ra xác suất cụ thể của việc bác bỏ sai giả thuyết (mức p) chứ không phải mức cụ thể mà khoảng tin cậy được xây dựng mà chỉ ra nhiều hơn vào thời điểm khác.
Như bạn có thể thấy, việc xây dựng khoảng tin cậy cho giá trị trung bình (hoặc kỳ vọng toán học) không khó. Điều chính là nắm bắt được bản chất, và sau đó mọi thứ sẽ tiếp tục. Trong thực tế, hầu hết các trường hợp đều sử dụng khoảng tin cậy 95%, xấp xỉ hai sai số chuẩn ở hai bên giá trị trung bình.
Đó là tất cả cho bây giờ. Mọi điều tốt đẹp nhất!