Phân phối liên tục thống nhất trong MS EXCEL. Quy luật phân bố đồng nhất và hàm mũ của một biến ngẫu nhiên liên tục
Vấn đề này đã được nghiên cứu chi tiết từ lâu và phương pháp tọa độ cực do George Box, Mervyn Muller và George Marsaglia đề xuất năm 1958 được sử dụng rộng rãi nhất. Phương pháp này cho phép bạn có được một cặp biến ngẫu nhiên phân phối chuẩn độc lập với giá trị trung bình 0 và phương sai 1 như sau:
Trong đó Z 0 và Z 1 là các giá trị mong muốn, s \u003d u 2 + v 2 và u và v là các biến ngẫu nhiên phân bố đều trên đoạn (-1, 1), được chọn sao cho thỏa mãn điều kiện 0< s < 1.
Nhiều người sử dụng những công thức này mà không hề suy nghĩ, và nhiều người thậm chí không nghi ngờ sự tồn tại của chúng, vì họ sử dụng các triển khai có sẵn. Nhưng cũng có người thắc mắc: “Công thức này đến từ đâu? Và tại sao bạn nhận được một cặp giá trị cùng một lúc? Sau đây, tôi sẽ cố gắng đưa ra câu trả lời rõ ràng cho những câu hỏi này.
Để bắt đầu, hãy để tôi nhắc bạn mật độ xác suất, hàm phân phối của một biến ngẫu nhiên và hàm nghịch đảo là gì. Giả sử có một biến ngẫu nhiên nào đó có phân phối được cho bởi hàm mật độ f(x), có dạng sau:

Điều này có nghĩa là xác suất để giá trị của biến ngẫu nhiên này nằm trong khoảng (A, B) bằng diện tích phần tô đậm. Và kết quả là diện tích của toàn bộ vùng tô bóng phải bằng 1, vì trong mọi trường hợp, giá trị của biến ngẫu nhiên sẽ rơi vào miền của hàm f.
Hàm phân phối của một biến ngẫu nhiên là một tích phân của hàm mật độ. Và trong trường hợp này, dạng gần đúng của nó sẽ như sau:

Ở đây ý nghĩa là giá trị của biến ngẫu nhiên sẽ nhỏ hơn A với xác suất B. Và kết quả là hàm số không bao giờ giảm và các giá trị của nó nằm trong khoảng.
Hàm nghịch đảo là hàm trả về đối số của hàm ban đầu nếu bạn truyền giá trị của hàm ban đầu vào nó. Ví dụ, đối với hàm x 2, nghịch đảo sẽ là hàm trích rút căn, đối với sin (x) là arcsin (x), v.v.
Vì hầu hết các trình tạo số giả ngẫu nhiên chỉ đưa ra phân bố đồng đều ở đầu ra nên thường cần phải chuyển đổi nó sang một số khác. Trong trường hợp này, với một Gaussian bình thường:

Cơ sở của tất cả các phương pháp chuyển đổi một phân bố đều thành bất kỳ phân bố nào khác là phương pháp chuyển đổi nghịch đảo. Nó hoạt động như sau. Một hàm được tìm thấy nghịch đảo với hàm của phân bố bắt buộc và một biến ngẫu nhiên được phân bố đều trên đoạn (0, 1) được chuyển cho hàm đó dưới dạng đối số. Ở đầu ra, chúng ta thu được một giá trị với phân phối được yêu cầu. Để rõ ràng, đây là hình ảnh sau đây.

Do đó, một phân đoạn đồng nhất dường như được làm mờ theo phân bố mới, được chiếu lên một trục khác thông qua một hàm nghịch đảo. Nhưng vấn đề là tích phân mật độ của phân bố Gauss không dễ tính nên các nhà khoa học trên đã phải gian lận.
Có một phân phối chi bình phương (phân phối Pearson), là phân phối tổng bình phương của k biến ngẫu nhiên chuẩn tắc độc lập. Và trong trường hợp k = 2 thì phân phối này là hàm mũ.

Điều này có nghĩa là nếu một điểm trong hệ tọa độ hình chữ nhật có tọa độ X và Y ngẫu nhiên được phân bố chuẩn, thì sau khi chuyển đổi các tọa độ này sang hệ cực (r, θ), bình phương bán kính (khoảng cách từ gốc đến điểm) sẽ được phân bố theo cấp số nhân, vì bình phương của bán kính là tổng bình phương của tọa độ (theo định luật Pythagore). Mật độ phân bố của các điểm như vậy trên mặt phẳng sẽ như sau:


Vì nó bằng nhau theo mọi hướng nên góc θ sẽ có phân bố đều trong khoảng từ 0 đến 2π. Điều ngược lại cũng đúng: nếu bạn chỉ định một điểm trong hệ tọa độ cực sử dụng hai biến ngẫu nhiên độc lập (góc phân bố đều và bán kính phân bố theo cấp số nhân), thì tọa độ hình chữ nhật của điểm này sẽ là các biến ngẫu nhiên chuẩn tắc độc lập. Và việc thu được phân bố mũ từ một phân bố đều đã dễ dàng hơn nhiều bằng cách sử dụng cùng một phương pháp biến đổi nghịch đảo. Đây là bản chất của phương pháp cực Box-Muller.
Bây giờ chúng ta hãy lấy các công thức.
![]() (1)
(1)
Để thu được r và θ, cần tạo ra hai biến ngẫu nhiên phân bố đều trên đoạn (0, 1) (gọi là u và v), phân bố của một trong số đó (giả sử v) phải được chuyển đổi thành hàm mũ thành thu được bán kính. Hàm phân phối mũ có dạng như sau:
Hàm nghịch đảo của nó:
![]()
Vì phân bố đều là đối xứng nên phép biến đổi sẽ hoạt động tương tự với hàm
![]()
Theo công thức phân bố chi bình phương thì λ = 0,5. Chúng ta thay thế λ, v vào hàm này và lấy bình phương của bán kính, sau đó là chính bán kính:

Chúng ta thu được góc bằng cách kéo dài đoạn đơn vị thành 2π:
Bây giờ chúng ta thay thế r và θ vào công thức (1) và nhận được:
 (2)
(2)
Những công thức này đã sẵn sàng để sử dụng. X và Y sẽ độc lập và có phân phối chuẩn với phương sai bằng 1 và giá trị trung bình bằng 0. Để có được phân bố với các đặc điểm khác, chỉ cần nhân kết quả của hàm với độ lệch chuẩn và cộng giá trị trung bình là đủ.
Nhưng có thể loại bỏ các hàm lượng giác bằng cách xác định góc không trực tiếp mà gián tiếp thông qua tọa độ hình chữ nhật của một điểm ngẫu nhiên trong đường tròn. Sau đó, thông qua các tọa độ này, người ta có thể tính độ dài của vectơ bán kính, sau đó tìm cosin và sin bằng cách chia x và y tương ứng cho nó. Làm thế nào và tại sao nó hoạt động?
Chúng ta chọn một điểm ngẫu nhiên từ phân bố đều trong đường tròn bán kính đơn vị và biểu thị bình phương chiều dài vectơ bán kính của điểm này bằng chữ s:

Lựa chọn được thực hiện bằng cách gán tọa độ hình chữ nhật x và y ngẫu nhiên phân bố đều trong khoảng (-1, 1) và loại bỏ các điểm không thuộc đường tròn, cũng như điểm trung tâm tại đó góc của vectơ bán kính là không xác định. Tức là điều kiện 0< s < 1. Тогда, как и в случае с Гауссовским распределением на плоскости, угол θ будет распределен равномерно. Это очевидно - количество точек в каждом направлении одинаково, значит каждый угол равновероятен. Но есть и менее очевидный факт - s тоже будет иметь равномерное распределение. Полученные s и θ будут независимы друг от друга. Поэтому мы можем воспользоваться значением s для получения экспоненциального распределения, не генерируя третью случайную величину. Подставим теперь s в формулы (2) вместо v, а вместо тригонометрических функций - их расчет делением координаты на длину радиус-вектора, которая в данном случае является корнем из s:
Chúng ta có được công thức như ở đầu bài. Nhược điểm của phương pháp này là loại bỏ các điểm không có trong vòng tròn. Tức là chỉ sử dụng 78,5% số biến ngẫu nhiên được tạo ra. Trên các máy tính cũ, việc thiếu các hàm lượng giác vẫn là một lợi thế lớn. Bây giờ, khi một lệnh của bộ xử lý đồng thời tính toán sin và cosin ngay lập tức, tôi nghĩ các phương pháp này vẫn có thể cạnh tranh.
Cá nhân tôi có thêm hai câu hỏi:
- Tại sao giá trị của s được phân bố đều?
- Tại sao tổng bình phương của hai biến ngẫu nhiên bình thường được phân phối theo cấp số nhân?

Nếu một phép biến đổi tương tự được thực hiện cho một biến ngẫu nhiên thông thường thì hàm mật độ của bình phương của nó sẽ tương tự như một hyperbol. Và việc cộng hai bình phương của các biến ngẫu nhiên thông thường đã là một quá trình phức tạp hơn nhiều liên quan đến tích phân kép. Và thực tế là kết quả sẽ là một sự phân bố theo cấp số nhân, về mặt cá nhân, tôi vẫn phải kiểm tra nó bằng một phương pháp thực tế hoặc chấp nhận nó như một tiên đề. Và đối với những ai quan tâm, tôi khuyên bạn nên làm quen với chủ đề này kỹ hơn bằng cách rút ra kiến thức từ những cuốn sách này:
- Wentzel E.S. Lý thuyết xác suất
- Knut D.E. Nghệ thuật lập trình Tập 2
Để kết luận, tôi sẽ đưa ra một ví dụ về việc triển khai trình tạo số ngẫu nhiên được phân phối thông thường trong JavaScript:
Hàm Gauss() ( varready = false; var giây = 0.0; this.next = function(mean, dev) (mean =mean == unfined ? 0.0:mean; dev = dev == unfined ? 1.0: dev; if ( this.ready) ( this.ready = false; return this.second * dev +mean; ) else ( var u, v, s; do ( u = 2.0 * Math.random() - 1.0; v = 2.0 * Math. ngẫu nhiên() - 1.0; s = u * u + v * v; ) while (s > 1.0 || s == 0.0);var r = Math.sqrt(-2.0 * Math.log(s) / s); this.second = r * u; this.ready = true; return r * v * dev +mean; ) ); ) g = new Gauss(); // tạo một đối tượng a = g.next(); // tạo một cặp giá trị và lấy giá trị đầu tiên b = g.next(); // lấy kết quả thứ hai c = g.next(); // tạo lại một cặp giá trị và lấy giá trị đầu tiên
Các tham số trung bình (kỳ vọng toán học) và dev (độ lệch chuẩn) là tùy chọn. Tôi lưu ý bạn rằng logarit là tự nhiên.
Hàm phân phối trong trường hợp này, theo (5.7), sẽ có dạng:
trong đó: m là kỳ vọng toán học, s là độ lệch chuẩn.
Phân phối chuẩn còn được gọi là Gaussian theo tên nhà toán học người Đức Gauss. Việc một biến ngẫu nhiên có phân phối chuẩn với các tham số: m,, được ký hiệu như sau: N(m,s), trong đó: m =a =M ;
Khá thường xuyên, trong các công thức, kỳ vọng toán học được biểu thị bằng MỘT . Nếu một biến ngẫu nhiên được phân phối theo luật N(0,1) thì nó được gọi là giá trị chuẩn hóa hoặc chuẩn hóa. Hàm phân phối của nó có dạng:
|
|
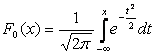 .
.Đồ thị mật độ của phân bố chuẩn, được gọi là đường cong chuẩn hoặc đường cong Gaussian, được thể hiện trong Hình 5.4.

Cơm. 5.4. Mật độ phân bố bình thường
Việc xác định các đặc tính số của một biến ngẫu nhiên bằng mật độ của nó được xem xét trên một ví dụ.
Ví dụ 6.
Một biến ngẫu nhiên liên tục được cho bởi mật độ phân phối: ![]() .
.
Xác định loại phân phối, tìm kỳ vọng toán học M(X) và phương sai D(X).
So sánh mật độ phân bố đã cho với (5.16), chúng ta có thể kết luận rằng định luật phân bố chuẩn với m =4 đã cho. Do đó, kỳ vọng toán học M(X)=4, phương sai D(X)=9.
Độ lệch chuẩn s=3.
Hàm Laplace có dạng:
|
|
 ,
,có liên quan đến hàm phân phối chuẩn (5.17), bởi quan hệ:
F 0 (x) \u003d F (x) + 0,5.
Hàm Laplace lẻ.
Ф(-x)=-Ф(x).
Các giá trị của hàm Laplace Ф(х) được lập bảng và lấy từ bảng theo giá trị của x (xem Phụ lục 1).
Phân phối chuẩn của một biến ngẫu nhiên liên tục có vai trò quan trọng trong lý thuyết xác suất và trong mô tả hiện thực, nó rất phổ biến trong các hiện tượng tự nhiên ngẫu nhiên. Trong thực tế, rất thường xuyên có các biến ngẫu nhiên được hình thành chính xác do tổng của nhiều số hạng ngẫu nhiên. Đặc biệt, việc phân tích các sai số đo lường cho thấy chúng là tổng của các loại sai số khác nhau. Thực tiễn cho thấy phân bố xác suất của sai số đo lường gần với quy luật chuẩn mực.
Sử dụng hàm Laplace, người ta có thể giải các bài toán tính xác suất rơi vào một khoảng cho trước và độ lệch cho trước của một biến ngẫu nhiên chuẩn tắc.
Hãy xem xét một phân phối liên tục thống nhất. Hãy tính toán kỳ vọng và phương sai toán học. Hãy tạo các giá trị ngẫu nhiên bằng hàm MS EXCELRAND() và phần bổ trợ Gói Phân tích, chúng tôi sẽ đánh giá giá trị trung bình và độ lệch chuẩn.
chia đêu trên khoảng đó, biến ngẫu nhiên có:
Hãy tạo một mảng gồm 50 số từ phạm vi)