Selang keyakinan. Selang keyakinan
Dan lain-lain. Kesemuanya adalah anggaran analog teori mereka, yang boleh diperolehi jika bukan sampel, tetapi populasi umum tersedia. Tetapi malangnya, penduduk umum sangat mahal dan selalunya tidak dapat diakses.
Konsep anggaran selang
Sebarang anggaran sampel mempunyai beberapa penyebaran, kerana ialah pembolehubah rawak bergantung kepada nilai dalam sampel tertentu. Oleh itu, untuk kesimpulan statistik yang lebih dipercayai, seseorang harus mengetahui bukan sahaja anggaran titik, tetapi juga selang, yang dengan kebarangkalian tinggi γ (gamma) meliputi penunjuk yang dinilai θ (theta).
Secara rasmi, ini adalah dua nilai tersebut (statistik) T 1 (X) Dan T 2 (X), Apa T 1< T 2 , yang pada tahap kebarangkalian tertentu γ syarat dipenuhi:
Pendek kata, kemungkinan besar γ atau lebih penunjuk sebenar adalah antara mata T 1 (X) Dan T 2 (X), yang dipanggil sempadan bawah dan atas selang keyakinan.
Salah satu syarat untuk membina selang keyakinan ialah kesempitan maksimumnya, i.e. ia sepatutnya sesingkat mungkin. Keinginan itu adalah wajar, kerana... penyelidik cuba menyetempatkan lokasi parameter yang dikehendaki dengan lebih tepat.
Ia berikutan bahawa selang keyakinan mesti meliputi kebarangkalian maksimum taburan. dan penilaian itu sendiri harus berada di tengah.
![]()
Iaitu, kebarangkalian sisihan (penunjuk sebenar dari anggaran) ke atas adalah sama dengan kebarangkalian sisihan ke bawah. Perlu juga diperhatikan bahawa untuk taburan asimetri, selang di sebelah kanan tidak sama dengan selang di sebelah kiri.
Angka di atas jelas menunjukkan bahawa lebih besar kebarangkalian keyakinan, lebih luas selang - hubungan langsung.
Ini adalah pengenalan ringkas kepada teori anggaran selang parameter yang tidak diketahui. Mari kita teruskan untuk mencari had keyakinan untuk jangkaan matematik.
Selang keyakinan untuk jangkaan matematik
Jika data asal diedarkan ke atas , maka purata akan menjadi nilai normal. Ini berikutan daripada peraturan bahawa gabungan linear nilai normal juga mempunyai taburan normal. Oleh itu, untuk mengira kebarangkalian kita boleh menggunakan radas matematik bagi hukum taburan normal.
Walau bagaimanapun, ini memerlukan mengetahui dua parameter - jangkaan dan varians, yang biasanya tidak diketahui. Anda boleh, tentu saja, menggunakan anggaran dan bukannya parameter (min aritmetik dan ), tetapi kemudian taburan purata tidak akan normal sepenuhnya, ia akan diratakan sedikit ke bawah. Fakta ini diperhatikan dengan bijak oleh warganegara William Gosset dari Ireland, menerbitkan penemuannya dalam edisi Mac 1908 jurnal Biometrika. Untuk tujuan kerahsiaan, Gosset menandatangani dirinya Student. Ini adalah bagaimana taburan-t Pelajar muncul.
Walau bagaimanapun, taburan normal data, yang digunakan oleh K. Gauss dalam menganalisis kesilapan dalam pemerhatian astronomi, sangat jarang berlaku dalam kehidupan duniawi dan agak sukar untuk ditubuhkan (kira-kira 2 ribu pemerhatian diperlukan untuk ketepatan yang tinggi). Oleh itu, adalah lebih baik untuk membuang andaian normal dan menggunakan kaedah yang tidak bergantung kepada taburan data asal.
Timbul persoalan: apakah taburan min aritmetik jika ia dikira daripada data taburan yang tidak diketahui? Jawapannya diberikan oleh teori kebarangkalian yang terkenal Teorem had pusat(CPT). Dalam matematik, terdapat beberapa varian (rumusan telah diperhalusi selama bertahun-tahun), tetapi kesemuanya, secara kasarnya, bermuara kepada pernyataan bahawa jumlah sejumlah besar pembolehubah rawak bebas mematuhi hukum taburan normal.
Apabila mengira min aritmetik, jumlah pembolehubah rawak digunakan. Dari sini ternyata min aritmetik mempunyai taburan normal, di mana jangkaan adalah jangkaan data asal, dan variansnya ialah .
Orang pintar tahu cara membuktikan CLT, tetapi kami akan mengesahkannya dengan bantuan percubaan yang dijalankan dalam Excel. Mari kita simulasi sampel 50 pembolehubah rawak teragih seragam (menggunakan fungsi Excel RANDBETWEEN). Kemudian kita akan membuat 1000 sampel tersebut dan mengira min aritmetik bagi setiap satu. Mari kita lihat pengedaran mereka.

Dapat dilihat bahawa taburan purata adalah hampir dengan hukum biasa. Jika saiz dan nombor sampel dibuat lebih besar, persamaan akan menjadi lebih baik.
Sekarang kita telah melihat dengan mata kepala kita sendiri kesahihan CLT, kita boleh, menggunakan , mengira selang keyakinan untuk min aritmetik, yang meliputi min sebenar atau jangkaan matematik dengan kebarangkalian yang diberikan.
Untuk menetapkan had atas dan bawah, anda perlu mengetahui parameter taburan normal. Sebagai peraturan, tidak ada, jadi anggaran digunakan: min aritmetik Dan varians sampel. Saya ulangi, kaedah ini memberikan anggaran yang baik hanya dengan sampel yang besar. Apabila sampel kecil, selalunya disyorkan untuk menggunakan pengedaran Pelajar. Jangan percaya! Taburan Pelajar untuk min berlaku hanya apabila data asal diedarkan secara normal, iaitu hampir tidak pernah. Oleh itu, adalah lebih baik untuk segera menetapkan bar minimum untuk jumlah data yang diperlukan dan menggunakan kaedah asymptotically betul. Mereka mengatakan 30 pemerhatian sudah memadai. Ambil 50 - anda tidak akan salah.
![]()
T 1.2– had bawah dan atas selang keyakinan
– contoh aritmetik min
s 0– sisihan piawai sampel (tidak berat sebelah)
n - saiz sampel
γ – kebarangkalian keyakinan (biasanya sama dengan 0.9, 0.95 atau 0.99)
c γ =Φ -1 ((1+γ)/2)– nilai songsang bagi fungsi taburan normal piawai. Ringkasnya, ini ialah bilangan ralat piawai daripada min aritmetik ke sempadan bawah atau atas (tiga kebarangkalian ini sepadan dengan nilai 1.64, 1.96 dan 2.58).
Intipati formula adalah bahawa min aritmetik diambil dan kemudian jumlah tertentu diketepikan daripadanya ( dengan γ) ralat piawai ( s 0 /√n). Semuanya diketahui, ambil dan pertimbangkan.
Sebelum penggunaan meluas komputer peribadi, mereka biasa mendapatkan nilai fungsi pengedaran normal dan songsangnya. Mereka masih digunakan hari ini, tetapi lebih berkesan untuk menggunakan formula Excel siap pakai. Semua elemen daripada formula di atas ( , dan ) boleh dikira dengan mudah dalam Excel. Tetapi terdapat formula sedia untuk mengira selang keyakinan - AMANAH.NORM. Sintaksnya adalah seperti berikut.
KEYAKINAN.NORM(alfa;standard_off;saiz)
alfa– aras keertian atau aras keyakinan, yang dalam notasi yang diterima pakai di atas adalah sama dengan 1- γ, i.e. kebarangkalian bahawa matematikjangkaan akan berada di luar selang keyakinan. Dengan tahap keyakinan 0.95, alfa ialah 0.05, dsb.
standard_off– sisihan piawai data sampel. Tidak perlu mengira ralat standard; Excel sendiri akan membahagikan dengan akar n.
saiz– saiz sampel (n).
Hasil daripada fungsi NORM KEYAKINAN ialah sebutan kedua daripada formula untuk mengira selang keyakinan, i.e. separuh selang Sehubungan itu, titik bawah dan atas adalah purata ± nilai yang diperolehi.
Oleh itu, adalah mungkin untuk membina algoritma sejagat untuk mengira selang keyakinan bagi min aritmetik, yang tidak bergantung pada taburan data asal. Harga untuk kesejagatan adalah sifat asimptotiknya, i.e. keperluan untuk menggunakan sampel yang agak besar. Walau bagaimanapun, dalam zaman teknologi moden, mengumpul jumlah data yang diperlukan biasanya tidak sukar.
Menguji hipotesis statistik menggunakan selang keyakinan
(modul 111)
Salah satu masalah utama yang diselesaikan dalam statistik ialah. Intipatinya secara ringkas seperti berikut. Andaian dibuat, sebagai contoh, bahawa jangkaan populasi umum adalah sama dengan beberapa nilai. Kemudian taburan sampel bermakna yang boleh diperhatikan untuk jangkaan yang diberikan dibina. Seterusnya, mereka melihat di mana dalam pengagihan bersyarat ini terletak purata sebenar. Sekiranya ia melampaui had yang boleh diterima, maka penampilan purata sedemikian sangat tidak mungkin, dan jika eksperimen diulang sekali, ia hampir mustahil, yang bercanggah dengan hipotesis yang dikemukakan, yang berjaya ditolak. Jika purata tidak melepasi tahap kritikal, maka hipotesis tidak ditolak (tetapi juga tidak terbukti!).
Jadi, dengan bantuan selang keyakinan, dalam kes kami untuk jangkaan, anda juga boleh menguji beberapa hipotesis. Ia sangat mudah untuk dilakukan. Katakan min aritmetik untuk sampel tertentu adalah bersamaan dengan 100. Hipotesis diuji bahawa nilai yang dijangkakan ialah, katakan, 90. Iaitu, jika kita mengemukakan soalan secara primitif, ia berbunyi seperti ini: bolehkah dengan yang benar nilai min bersamaan dengan 90, purata yang diperhatikan ternyata menjadi 100?
Untuk menjawab soalan ini, anda juga memerlukan maklumat tentang sisihan piawai dan saiz sampel. Mari kita andaikan sisihan piawai ialah 30 dan bilangan cerapan ialah 64 (untuk mengekstrak punca dengan mudah). Maka ralat piawai bagi min ialah 30/8 atau 3.75. Untuk mengira selang keyakinan 95%, anda perlu menambah dua ralat standard pada setiap sisi min (lebih tepat lagi, 1.96). Selang keyakinan adalah kira-kira 100±7.5 atau dari 92.5 hingga 107.5.
Alasan selanjutnya adalah seperti berikut. Jika nilai yang diuji jatuh dalam selang keyakinan, maka ia tidak bercanggah dengan hipotesis, kerana berada dalam had turun naik rawak (dengan kebarangkalian 95%). Jika titik yang diperiksa berada di luar selang keyakinan, maka kebarangkalian kejadian sedemikian adalah sangat kecil, dalam mana-mana kes di bawah tahap yang boleh diterima. Ini bermakna hipotesis ditolak kerana bercanggah dengan data yang diperhatikan. Dalam kes kami, hipotesis tentang nilai jangkaan berada di luar selang keyakinan (nilai 90 yang diuji tidak termasuk dalam selang 100±7.5), jadi ia harus ditolak. Menjawab soalan primitif di atas, harus dikatakan: tidak, tidak boleh, dalam apa jua keadaan, ini jarang berlaku. Selalunya, mereka menunjukkan kebarangkalian khusus untuk tersilap menolak hipotesis (peringkat-p), dan bukan tahap yang ditentukan di mana selang keyakinan dibina, tetapi lebih kepada itu pada masa lain.
Seperti yang anda lihat, membina selang keyakinan untuk purata (atau jangkaan matematik) tidak sukar. Perkara utama adalah untuk memahami intipati, dan kemudian perkara akan diteruskan. Dalam amalan, kebanyakan kes menggunakan selang keyakinan 95%, iaitu kira-kira dua ralat standard lebar pada kedua-dua belah min.
Itu sahaja buat masa ini. Semua yang terbaik!
Anggaran Selang Keyakinan
Objektif Pembelajaran
Statistik mempertimbangkan perkara berikut dua tugas utama:
Kami mempunyai beberapa anggaran berdasarkan data sampel dan kami ingin membuat beberapa pernyataan kebarangkalian tentang di mana nilai sebenar parameter anggaran terletak.
Kami mempunyai hipotesis khusus yang perlu diuji menggunakan data sampel.
Dalam topik ini kami mempertimbangkan tugas pertama. Marilah kita juga memperkenalkan definisi selang keyakinan.
Selang keyakinan ialah selang yang dibina di sekitar nilai anggaran parameter dan menunjukkan di mana nilai sebenar parameter anggaran terletak dengan kebarangkalian yang ditentukan secara priori.
Selepas mempelajari bahan mengenai topik ini, anda:
pelajari apakah selang keyakinan untuk anggaran;
belajar mengklasifikasikan masalah statistik;
menguasai teknik membina selang keyakinan, kedua-duanya menggunakan formula statistik dan menggunakan alat perisian;
belajar untuk menentukan saiz sampel yang diperlukan untuk mencapai parameter ketepatan anggaran statistik tertentu.
Taburan ciri sampel
pengagihan T
Seperti yang dibincangkan di atas, taburan pembolehubah rawak adalah hampir dengan taburan normal piawai dengan parameter 0 dan 1. Oleh kerana kita tidak mengetahui nilai σ, kita menggantikannya dengan beberapa anggaran s. Kuantiti tersebut sudah mempunyai taburan yang berbeza iaitu atau Pengagihan pelajar, yang ditentukan oleh parameter n -1 (bilangan darjah kebebasan). Taburan ini hampir dengan taburan normal (semakin besar n, semakin hampir taburan).
Dalam Rajah. 95  taburan Pelajar dengan 30 darjah kebebasan dibentangkan. Seperti yang anda lihat, ia sangat hampir dengan taburan normal.
taburan Pelajar dengan 30 darjah kebebasan dibentangkan. Seperti yang anda lihat, ia sangat hampir dengan taburan normal.
Sama seperti fungsi untuk bekerja dengan taburan normal NORMIDIST dan NORMINV, terdapat fungsi untuk bekerja dengan taburan-t - STUDIST (TDIST) dan STUDRASOBR (TINV). Contoh penggunaan fungsi ini boleh dilihat dalam fail STUDRASP.XLS (template dan penyelesaian) dan dalam Rajah. 96  .
.
Taburan ciri-ciri lain
Seperti yang kita sedia maklum, untuk menentukan ketepatan menganggar jangkaan matematik, kita memerlukan taburan-t. Untuk menganggarkan parameter lain, seperti varians, taburan berbeza diperlukan. Dua daripadanya ialah taburan-F dan x 2 -agihan.
Selang keyakinan untuk min
Selang keyakinan- ini ialah selang yang dibina di sekitar nilai anggaran parameter dan menunjukkan di mana nilai sebenar parameter anggaran terletak dengan kebarangkalian yang ditentukan secara priori.
Pembinaan selang keyakinan untuk nilai purata berlaku dengan cara berikut:
Contoh
Restoran makanan segera itu merancang untuk mengembangkan pelbagai jenisnya dengan jenis sandwic baharu. Untuk menganggarkan permintaan untuknya, pengurus merancang untuk memilih 40 pelawat secara rawak daripada mereka yang telah mencubanya dan meminta mereka menilai sikap mereka terhadap produk baharu pada skala dari 1 hingga 10. Pengurus ingin menganggarkan jangkaan bilangan mata yang produk baharu akan terima dan membina selang keyakinan 95% untuk anggaran ini. Bagaimana untuk melakukan ini? (lihat fail SANDWICH1.XLS (template dan penyelesaian).
Penyelesaian
Untuk menyelesaikan masalah ini anda boleh menggunakan . Hasilnya dibentangkan dalam Rajah. 97  .
.
Selang keyakinan untuk jumlah nilai
Kadangkala, menggunakan data sampel, adalah perlu untuk menganggarkan bukan jangkaan matematik, tetapi jumlah keseluruhan nilai. Sebagai contoh, dalam situasi dengan juruaudit, kepentingan mungkin dalam menganggarkan bukan purata saiz akaun, tetapi jumlah semua akaun.
Biarkan N ialah jumlah bilangan elemen, n saiz sampel, T 3 jumlah nilai dalam sampel, T" anggaran untuk jumlah ke atas keseluruhan populasi, kemudian ![]() , dan selang keyakinan dikira dengan formula , dengan s ialah anggaran sisihan piawai untuk sampel, dan ialah anggaran min bagi sampel.
, dan selang keyakinan dikira dengan formula , dengan s ialah anggaran sisihan piawai untuk sampel, dan ialah anggaran min bagi sampel.
Contoh
Katakan agensi cukai ingin menganggarkan jumlah bayaran balik cukai untuk 10,000 pembayar cukai. Pembayar cukai sama ada menerima bayaran balik atau membayar cukai tambahan. Cari selang keyakinan 95% untuk jumlah bayaran balik, dengan andaian saiz sampel 500 orang (lihat fail JUMLAH PEMBAYARAN BALIK.XLS (templat dan penyelesaian).
Penyelesaian
StatPro tidak mempunyai prosedur khas untuk kes ini, walau bagaimanapun, boleh diperhatikan bahawa sempadan boleh diperolehi daripada sempadan untuk purata berdasarkan formula di atas (Rajah 98).  ).
).
Selang keyakinan untuk perkadaran
Biarkan p ialah jangkaan matematik bahagian pelanggan, dan biarkan p b ialah anggaran bahagian ini yang diperoleh daripada sampel saiz n. Ia boleh ditunjukkan bahawa untuk cukup besar  taburan penilaian akan hampir normal dengan jangkaan matematik p dan sisihan piawai
taburan penilaian akan hampir normal dengan jangkaan matematik p dan sisihan piawai ![]() . Ralat piawai anggaran dalam kes ini dinyatakan sebagai
. Ralat piawai anggaran dalam kes ini dinyatakan sebagai  , dan selang keyakinan adalah sebagai
, dan selang keyakinan adalah sebagai  .
.
Contoh
Restoran makanan segera itu merancang untuk mengembangkan pelbagai jenisnya dengan jenis sandwic baharu. Untuk menilai permintaan untuknya, pengurus secara rawak memilih 40 pelawat daripada mereka yang telah mencubanya dan meminta mereka menilai sikap mereka terhadap produk baharu itu pada skala dari 1 hingga 10. Pengurus ingin menganggarkan nisbah jangkaan pelanggan yang menilai produk baharu sekurang-kurangnya 6 mata (dia menjangkakan bahawa pelanggan ini akan menjadi pengguna produk baharu).
Penyelesaian
Pada mulanya, kami membuat lajur baharu berdasarkan atribut 1 jika rating pelanggan melebihi 6 mata dan 0 sebaliknya (lihat fail SANDWICH2.XLS (templat dan penyelesaian).
Kaedah 1
Dengan mengira nombor 1, kami menganggarkan bahagian, dan kemudian menggunakan formula.
Nilai zcr diambil daripada jadual taburan normal khas (contohnya, 1.96 untuk selang keyakinan 95%).
Menggunakan pendekatan ini dan data khusus untuk membina selang 95%, kami memperoleh keputusan berikut (Rajah 99).  ). Nilai kritikal bagi parameter zcr ialah 1.96. Ralat piawai anggaran ialah 0.077. Had bawah selang keyakinan ialah 0.475. Had atas selang keyakinan ialah 0.775. Oleh itu, pengurus mempunyai hak untuk mempercayai dengan keyakinan 95% bahawa peratusan pelanggan yang menilai produk baharu 6 mata atau lebih tinggi adalah antara 47.5 dan 77.5.
). Nilai kritikal bagi parameter zcr ialah 1.96. Ralat piawai anggaran ialah 0.077. Had bawah selang keyakinan ialah 0.475. Had atas selang keyakinan ialah 0.775. Oleh itu, pengurus mempunyai hak untuk mempercayai dengan keyakinan 95% bahawa peratusan pelanggan yang menilai produk baharu 6 mata atau lebih tinggi adalah antara 47.5 dan 77.5.
Kaedah 2
Masalah ini boleh diselesaikan menggunakan alat StatPro standard. Untuk melakukan ini, cukup untuk ambil perhatian bahawa bahagian dalam kes ini bertepatan dengan nilai purata lajur Jenis. Seterusnya kami memohon StatPro/Inferens Statistik/Analisis Satu Sampel untuk membina selang keyakinan bagi min (anggaran jangkaan matematik) untuk lajur Jenis. Keputusan yang diperolehi dalam kes ini akan sangat hampir dengan keputusan kaedah pertama (Rajah 99).
Selang keyakinan untuk sisihan piawai
s digunakan sebagai anggaran sisihan piawai (formula diberikan dalam Bahagian 1). Fungsi ketumpatan anggaran s ialah fungsi khi kuasa dua, yang, seperti taburan-t, mempunyai n-1 darjah kebebasan. Terdapat fungsi khas untuk bekerja dengan pengedaran ini CHIDIST dan CHIINV.
Selang keyakinan dalam kes ini tidak lagi simetri. Gambar rajah sempadan konvensional ditunjukkan dalam Rajah. 100 .
Contoh
Mesin mesti menghasilkan bahagian dengan diameter 10 cm Namun, disebabkan pelbagai keadaan, ralat berlaku. Pengawal kualiti mengambil berat tentang dua keadaan: pertama, nilai purata hendaklah 10 cm; kedua, walaupun dalam kes ini, jika penyelewengan besar, maka banyak bahagian akan ditolak. Setiap hari dia membuat sampel sebanyak 50 bahagian (lihat fail KUALITI KAWALAN.XLS (template dan penyelesaian). Apakah kesimpulan yang boleh diberikan oleh sampel sedemikian?
Penyelesaian
Mari bina 95% selang keyakinan untuk min dan sisihan piawai menggunakan StatPro/Inferens Statistik/Analisis Satu Sampel(Gamb. 101  ).
).
Seterusnya, dengan menggunakan andaian taburan normal diameter, kami mengira bahagian produk yang rosak, menetapkan sisihan maksimum 0.065. Dengan menggunakan keupayaan jadual penggantian (kes dua parameter), kami merancang pergantungan bahagian kecacatan pada nilai purata dan sisihan piawai (Rajah 102).  ).
).
Selang keyakinan untuk perbezaan antara dua min
Ini adalah salah satu aplikasi kaedah statistik yang paling penting. Contoh situasi.
Seorang pengurus kedai pakaian ingin mengetahui berapa banyak lebih atau kurang purata pelanggan wanita berbelanja di kedai berbanding purata pelanggan lelaki.
Kedua-dua syarikat penerbangan itu menggunakan laluan yang sama. Organisasi pengguna ingin membandingkan perbezaan antara purata jangka masa kelewatan penerbangan untuk kedua-dua syarikat penerbangan.
Syarikat menghantar kupon untuk jenis barangan tertentu di satu bandar dan bukan di bandar lain. Pengurus ingin membandingkan purata volum pembelian produk ini dalam tempoh dua bulan akan datang.
Seorang peniaga kereta sering berurusan dengan pasangan suami isteri semasa pembentangan. Untuk memahami reaksi peribadi mereka terhadap pembentangan, pasangan sering ditemu bual secara berasingan. Pengurus ingin menilai perbezaan penilaian yang diberikan oleh lelaki dan wanita.
Kes sampel bebas
Perbezaan antara min akan mempunyai taburan-t dengan n 1 + n 2 - 2 darjah kebebasan. Selang keyakinan untuk μ 1 - μ 2 dinyatakan oleh hubungan:

Masalah ini boleh diselesaikan bukan sahaja menggunakan formula di atas, tetapi juga menggunakan alat StatPro standard. Untuk melakukan ini, sudah cukup untuk digunakan
Selang keyakinan untuk perbezaan antara perkadaran
Biarlah jangkaan matematik saham. Biarkan anggaran sampel mereka, dibina daripada sampel bersaiz n 1 dan n 2, masing-masing. Kemudian adalah anggaran untuk perbezaan . Oleh itu, selang keyakinan perbezaan ini dinyatakan sebagai:
Di sini z cr ialah nilai yang diperoleh daripada taburan normal menggunakan jadual khas (contohnya, 1.96 untuk selang keyakinan 95%).
Ralat piawai anggaran dinyatakan dalam kes ini oleh hubungan:
 .
.
Contoh
Kedai itu, membuat persediaan untuk jualan besar, menjalankan penyelidikan pemasaran berikut. 300 pembeli teratas telah dipilih dan dibahagikan secara rawak kepada dua kumpulan dengan 150 ahli setiap satu. Semua pembeli terpilih telah dihantar jemputan untuk menyertai jualan, tetapi hanya ahli kumpulan pertama menerima kupon yang melayakkan mereka mendapat diskaun 5%. Semasa jualan, pembelian kesemua 300 pembeli terpilih telah direkodkan. Bagaimanakah pengurus boleh mentafsir keputusan dan membuat pertimbangan tentang keberkesanan kupon? (lihat fail COUPONS.XLS (template dan penyelesaian)).
Penyelesaian
Untuk kes khusus kami, daripada 150 pelanggan yang menerima kupon diskaun, 55 membuat pembelian untuk jualan, dan antara 150 yang tidak menerima kupon, hanya 35 membuat pembelian (Gamb. 103  ). Kemudian nilai perkadaran sampel ialah 0.3667 dan 0.2333, masing-masing. Dan perbezaan sampel di antara mereka adalah sama dengan 0.1333, masing-masing. Dengan mengandaikan selang keyakinan 95%, kita dapati daripada jadual taburan normal z cr = 1.96. Pengiraan ralat piawai perbezaan sampel ialah 0.0524. Kami akhirnya mendapati bahawa had bawah selang keyakinan 95% ialah 0.0307, dan had atas ialah 0.2359, masing-masing. Keputusan yang diperoleh boleh ditafsirkan sedemikian rupa sehingga bagi setiap 100 pelanggan yang menerima kupon diskaun, kita boleh menjangkakan daripada 3 hingga 23 pelanggan baharu. Walau bagaimanapun, kita mesti ingat bahawa kesimpulan ini sendiri tidak bermakna keberkesanan menggunakan kupon (kerana dengan memberikan diskaun, kita kehilangan keuntungan!). Mari kita tunjukkan ini dengan data tertentu. Mari kita anggap bahawa saiz pembelian purata ialah 400 rubel, di mana 50 rubel. ada untung kedai. Kemudian jangkaan keuntungan bagi 100 pelanggan yang tidak menerima kupon ialah:
). Kemudian nilai perkadaran sampel ialah 0.3667 dan 0.2333, masing-masing. Dan perbezaan sampel di antara mereka adalah sama dengan 0.1333, masing-masing. Dengan mengandaikan selang keyakinan 95%, kita dapati daripada jadual taburan normal z cr = 1.96. Pengiraan ralat piawai perbezaan sampel ialah 0.0524. Kami akhirnya mendapati bahawa had bawah selang keyakinan 95% ialah 0.0307, dan had atas ialah 0.2359, masing-masing. Keputusan yang diperoleh boleh ditafsirkan sedemikian rupa sehingga bagi setiap 100 pelanggan yang menerima kupon diskaun, kita boleh menjangkakan daripada 3 hingga 23 pelanggan baharu. Walau bagaimanapun, kita mesti ingat bahawa kesimpulan ini sendiri tidak bermakna keberkesanan menggunakan kupon (kerana dengan memberikan diskaun, kita kehilangan keuntungan!). Mari kita tunjukkan ini dengan data tertentu. Mari kita anggap bahawa saiz pembelian purata ialah 400 rubel, di mana 50 rubel. ada untung kedai. Kemudian jangkaan keuntungan bagi 100 pelanggan yang tidak menerima kupon ialah:
50 0.2333 100 = 1166.50 gosok.
Pengiraan yang sama untuk 100 pelanggan yang menerima pemberian kupon:
30 0.3667 100 = 1100.10 gosok.
Penurunan keuntungan purata kepada 30 dijelaskan oleh fakta bahawa, menggunakan diskaun, pelanggan yang menerima kupon secara purata akan membuat pembelian untuk 380 rubel.
Oleh itu, kesimpulan akhir menunjukkan ketidakberkesanan menggunakan kupon sedemikian dalam keadaan tertentu ini.
Komen. Masalah ini boleh diselesaikan menggunakan alat StatPro standard. Untuk melakukan ini, sudah cukup untuk mengurangkan masalah ini kepada masalah menganggarkan perbezaan antara dua purata menggunakan kaedah, dan kemudian memohon StatPro/Inferens Statistik/Analisis Dua Sampel untuk membina selang keyakinan bagi perbezaan antara dua nilai purata.
Mengawal Panjang Selang Keyakinan
Panjang selang keyakinan bergantung pada syarat berikut:
data secara langsung (sisihan piawai);
tahap kepentingan;
saiz sampel.
Saiz sampel untuk menganggar min
Pertama, mari kita pertimbangkan masalah dalam kes umum. Mari kita nyatakan nilai separuh panjang selang keyakinan yang diberikan kepada kita sebagai B (Rajah 104  ). Kita tahu bahawa selang keyakinan bagi nilai min bagi beberapa pembolehubah rawak X dinyatakan sebagai
). Kita tahu bahawa selang keyakinan bagi nilai min bagi beberapa pembolehubah rawak X dinyatakan sebagai ![]() , Di mana
, Di mana ![]() . Percaya:
. Percaya:
![]() dan menyatakan n, kita dapat .
dan menyatakan n, kita dapat .
Malangnya, kita tidak tahu nilai sebenar varians pembolehubah rawak X. Di samping itu, kita tidak tahu nilai tcr, kerana ia bergantung pada n melalui bilangan darjah kebebasan. Dalam keadaan ini, kita boleh melakukan perkara berikut. Daripada varians s, kami menggunakan beberapa anggaran varians berdasarkan sebarang pelaksanaan yang tersedia bagi pembolehubah rawak yang dikaji. Daripada nilai t cr, kami menggunakan nilai z cr untuk taburan normal. Ini agak boleh diterima, kerana fungsi ketumpatan taburan untuk taburan normal dan t adalah sangat rapat (kecuali untuk kes n kecil). Oleh itu, formula yang diperlukan dalam bentuk:
 .
.
Oleh kerana formula memberikan, secara amnya, keputusan bukan integer, pembundaran dengan lebihan keputusan diambil sebagai saiz sampel yang diingini.
Contoh
Restoran makanan segera itu merancang untuk mengembangkan pelbagai jenisnya dengan jenis sandwic baharu. Untuk menilai permintaan untuknya, pengurus merancang untuk memilih secara rawak beberapa pelawat daripada mereka yang telah mencubanya dan meminta mereka menilai sikap mereka terhadap produk baharu pada skala dari 1 hingga 10. Pengurus ingin menganggarkan jangkaan bilangan mata yang produk baharu akan menerima produk dan membina selang keyakinan 95% untuk anggaran ini. Pada masa yang sama, dia mahukan separuh lebar selang keyakinan tidak melebihi 0.3. Berapa ramai pelawat yang perlu dia temuduga?
seperti berikut:

Di sini r ots ialah anggaran bahagian p, dan B ialah separuh panjang selang keyakinan tertentu. Anggaran terlalu tinggi untuk n boleh diperoleh menggunakan nilai r ots= 0.5. Dalam kes ini, panjang selang keyakinan tidak akan melebihi nilai B yang ditentukan untuk sebarang nilai sebenar p.
Contoh
Biarkan pengurus daripada contoh terdahulu merancang untuk menganggarkan bahagian pelanggan yang memilih jenis produk baharu. Dia mahu membina selang keyakinan 90% yang separuh panjangnya tidak melebihi 0.05. Berapakah bilangan pelanggan yang perlu dimasukkan ke dalam sampel rawak?
Penyelesaian
Dalam kes kami, nilai z cr = 1.645. Oleh itu, kuantiti yang diperlukan dikira sebagai  .
.
Jika pengurus mempunyai sebab untuk mempercayai bahawa nilai p yang dikehendaki adalah, sebagai contoh, lebih kurang 0.3, maka dengan menggantikan nilai ini ke dalam formula di atas, kita akan mendapat nilai sampel rawak yang lebih kecil, iaitu 228.
Formula untuk menentukan saiz sampel rawak sekiranya terdapat perbezaan antara dua min ditulis sebagai:
 .
.
Contoh
Sesetengah syarikat komputer mempunyai pusat khidmat pelanggan. Baru-baru ini, bilangan aduan pelanggan mengenai kualiti perkhidmatan yang kurang baik telah meningkat. Pusat khidmat terutamanya menggaji dua jenis pekerja: mereka yang tidak mempunyai banyak pengalaman, tetapi telah menyelesaikan kursus persediaan khas, dan mereka yang mempunyai pengalaman praktikal yang luas, tetapi belum menamatkan kursus khas. Syarikat itu ingin menganalisis aduan pelanggan sejak enam bulan lalu dan membandingkan purata bilangan aduan bagi setiap dua kumpulan pekerja. Diandaikan bahawa nombor dalam sampel untuk kedua-dua kumpulan adalah sama. Berapa ramai pekerja mesti dimasukkan ke dalam sampel untuk mendapatkan selang 95% dengan separuh panjang tidak lebih daripada 2?
Penyelesaian
Di sini σ ots ialah anggaran sisihan piawai bagi kedua-dua pembolehubah rawak di bawah andaian bahawa ia hampir. Oleh itu, dalam masalah kita, kita perlu mendapatkan anggaran ini. Ini boleh dilakukan, sebagai contoh, seperti berikut. Setelah melihat data tentang aduan pelanggan sepanjang enam bulan yang lalu, pengurus mungkin menyedari bahawa setiap pekerja biasanya menerima 6 hingga 36 aduan. Mengetahui bahawa untuk taburan normal hampir semua nilai tidak lebih daripada tiga sisihan piawai dari min, dia boleh percaya bahawa:
![]() , dari mana σ ots = 5.
, dari mana σ ots = 5.
Menggantikan nilai ini ke dalam formula, kita dapat  .
.
Formula untuk menentukan saiz sampel rawak sekiranya menganggar perbezaan antara perkadaran mempunyai bentuk:

Contoh
Sesetengah syarikat mempunyai dua kilang yang mengeluarkan produk yang serupa. Seorang pengurus syarikat ingin membandingkan peratusan produk yang rosak di kedua-dua kilang. Mengikut maklumat yang ada, kadar kecacatan di kedua-dua kilang adalah antara 3 hingga 5%. Ia bertujuan untuk membina selang keyakinan 99% dengan separuh panjang tidak lebih daripada 0.005 (atau 0.5%). Berapa banyak produk mesti dipilih dari setiap kilang?
Penyelesaian
Di sini p 1ots dan p 2ots ialah anggaran dua bahagian kecacatan yang tidak diketahui di kilang pertama dan kedua. Jika kita meletakkan p 1ots = p 2ots = 0.5, maka kita mendapat nilai yang terlalu tinggi untuk n. Tetapi oleh kerana dalam kes kami, kami mempunyai beberapa maklumat apriori tentang saham ini, kami mengambil anggaran atas saham ini, iaitu 0.05. Kita mendapatkan
Apabila menganggar beberapa parameter populasi daripada data sampel, adalah berguna untuk memberikan bukan sahaja anggaran titik parameter, tetapi juga untuk menyediakan selang keyakinan yang menunjukkan di mana nilai tepat parameter yang dianggarkan mungkin terletak.
Dalam bab ini, kami juga berkenalan dengan hubungan kuantitatif yang membolehkan kami membina selang sedemikian untuk pelbagai parameter; mempelajari cara untuk mengawal panjang selang keyakinan.
Perhatikan juga bahawa masalah menganggar saiz sampel (masalah merancang eksperimen) boleh diselesaikan menggunakan alat StatPro standard, iaitu StatPro/Inferens Statistik/Pemilihan Saiz Sampel.
SELANG KEYAKINAN UNTUK KEKERAPAN DAN PECAHAN
© 2008
Institut Kesihatan Awam Negara, Oslo, Norway
Artikel ini menerangkan dan membincangkan pengiraan selang keyakinan untuk frekuensi dan perkadaran menggunakan kaedah Wald, Wilson, Clopper - Pearson, menggunakan penjelmaan sudut dan kaedah Wald dengan pembetulan Agresti - Coull. Bahan yang dibentangkan memberikan maklumat umum tentang kaedah untuk mengira selang keyakinan untuk frekuensi dan perkadaran dan bertujuan untuk membangkitkan minat pembaca jurnal bukan sahaja dalam menggunakan selang keyakinan semasa membentangkan hasil penyelidikan mereka sendiri, tetapi juga dalam membaca kesusasteraan khusus sebelum memulakan kerja. pada penerbitan akan datang.
Kata kunci: selang keyakinan, kekerapan, perkadaran
Salah satu penerbitan sebelumnya secara ringkas menyebut perihalan data kualitatif dan melaporkan bahawa anggaran selangnya adalah lebih baik daripada anggaran titik untuk menerangkan kekerapan berlakunya ciri yang dikaji dalam populasi. Sesungguhnya, memandangkan penyelidikan dijalankan menggunakan data sampel, unjuran keputusan ke atas populasi mesti mengandungi unsur ketidaktepatan persampelan. Selang keyakinan ialah ukuran ketepatan parameter yang dianggarkan. Adalah menarik bahawa beberapa buku mengenai statistik asas untuk doktor benar-benar mengabaikan topik selang keyakinan untuk frekuensi. Dalam artikel ini kita akan melihat beberapa cara untuk mengira selang keyakinan untuk frekuensi, membayangkan ciri sampel seperti bukan pengulangan dan perwakilan, serta kebebasan pemerhatian antara satu sama lain. Dalam artikel ini, kekerapan difahami bukan sebagai nombor mutlak yang menunjukkan berapa kali nilai tertentu berlaku dalam agregat, tetapi sebagai nilai relatif yang menentukan bahagian peserta kajian yang ciri yang dikaji berlaku.
Dalam penyelidikan bioperubatan, selang keyakinan 95% paling kerap digunakan. Selang keyakinan ini ialah kawasan di mana perkadaran sebenar jatuh 95% sepanjang masa. Dalam erti kata lain, kita boleh mengatakan dengan kebolehpercayaan 95% bahawa nilai sebenar kekerapan kejadian sesuatu sifat dalam populasi akan berada dalam selang keyakinan 95%.
Kebanyakan manual statistik untuk penyelidik perubatan melaporkan bahawa ralat kekerapan dikira menggunakan formula
di mana p ialah kekerapan berlakunya ciri dalam sampel (nilai dari 0 hingga 1). Kebanyakan artikel saintifik domestik menunjukkan kekerapan berlakunya sifat dalam sampel (p), serta ralatnya (s) dalam bentuk p ± s. Walau bagaimanapun, adalah lebih sesuai untuk membentangkan selang keyakinan 95% untuk kekerapan berlakunya sifat dalam populasi, yang akan merangkumi nilai daripada
 |
 sebelum ini.
sebelum ini.
Sesetengah manual mengesyorkan bahawa untuk sampel kecil, gantikan nilai 1.96 dengan nilai t untuk N – 1 darjah kebebasan, di mana N ialah bilangan cerapan dalam sampel. Nilai t didapati daripada jadual untuk taburan-t, tersedia dalam hampir semua buku teks statistik. Penggunaan taburan t untuk kaedah Wald tidak memberikan kelebihan yang boleh dilihat berbanding dengan kaedah lain yang dibincangkan di bawah, dan oleh itu tidak disyorkan oleh sesetengah pengarang.
Kaedah yang dibentangkan di atas untuk mengira selang keyakinan untuk frekuensi atau perkadaran dinamakan Wald sebagai penghormatan kepada Abraham Wald (1902–1950), kerana penggunaannya yang meluas bermula selepas penerbitan Wald dan Wolfowitz pada tahun 1939. Walau bagaimanapun, kaedah itu sendiri telah dicadangkan oleh Pierre Simon Laplace (1749–1827) pada tahun 1812.
Kaedah Wald sangat popular, tetapi aplikasinya dikaitkan dengan masalah yang ketara. Kaedah ini tidak disyorkan untuk saiz sampel yang kecil, serta dalam kes di mana kekerapan kejadian ciri cenderung kepada 0 atau 1 (0% atau 100%) dan hanya mustahil untuk frekuensi 0 dan 1. Di samping itu, penghampiran taburan normal, yang digunakan semasa mengira ralat , "tidak berfungsi" dalam kes di mana n · p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Memandangkan pembolehubah baharu diedarkan secara normal, sempadan bawah dan atas selang keyakinan 95% untuk pembolehubah φ ialah φ-1.96 dan φ+1.96 kiri">


Daripada 1.96 untuk sampel kecil, adalah disyorkan untuk menggantikan nilai t untuk N – 1 darjah kebebasan. Kaedah ini tidak menghasilkan nilai negatif dan membenarkan anggaran selang keyakinan yang lebih tepat untuk frekuensi daripada kaedah Wald. Di samping itu, ia diterangkan dalam banyak buku rujukan domestik mengenai statistik perubatan, yang, bagaimanapun, tidak membawa kepada penggunaannya yang meluas dalam penyelidikan perubatan. Pengiraan selang keyakinan menggunakan penjelmaan sudut tidak disyorkan untuk frekuensi yang menghampiri 0 atau 1.
Di sinilah huraian kaedah untuk menganggar selang keyakinan dalam kebanyakan buku mengenai asas statistik untuk penyelidik perubatan biasanya berakhir, dan masalah ini adalah tipikal bukan sahaja untuk domestik tetapi juga untuk kesusasteraan asing. Kedua-dua kaedah adalah berdasarkan teorem had pusat, yang membayangkan sampel yang besar.
Dengan mengambil kira kelemahan menganggar selang keyakinan menggunakan kaedah di atas, Clopper dan Pearson mencadangkan pada tahun 1934 satu kaedah untuk mengira apa yang dipanggil selang keyakinan tepat, memandangkan taburan binomial sifat yang sedang dikaji. Kaedah ini tersedia dalam banyak kalkulator dalam talian, tetapi selang keyakinan yang diperoleh dengan cara ini dalam kebanyakan kes terlalu lebar. Pada masa yang sama, kaedah ini disyorkan untuk digunakan dalam kes di mana penilaian konservatif diperlukan. Tahap konservatif kaedah meningkat apabila saiz sampel berkurangan, terutamanya apabila N< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
Menurut banyak ahli statistik, penilaian selang keyakinan yang paling optimum untuk frekuensi dijalankan oleh kaedah Wilson, yang dicadangkan pada tahun 1927, tetapi secara praktikal tidak digunakan dalam penyelidikan bioperubatan domestik. Kaedah ini bukan sahaja membenarkan seseorang untuk menganggarkan selang keyakinan untuk kedua-dua frekuensi yang sangat kecil dan sangat besar, tetapi juga boleh digunakan untuk sebilangan kecil pemerhatian. Secara umum, selang keyakinan mengikut formula Wilson mempunyai bentuk
 |
 |
di mana mengambil nilai 1.96 apabila mengira selang keyakinan 95%, N ialah bilangan cerapan, dan p ialah kekerapan berlakunya ciri dalam sampel. Kaedah ini boleh didapati dalam kalkulator dalam talian, jadi penggunaannya tidak bermasalah. dan jangan mengesyorkan menggunakan kaedah ini untuk n p< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Sebagai tambahan kepada kaedah Wilson, kaedah Wald dengan pembetulan Agresti-Coll juga dipercayai memberikan anggaran optimum selang keyakinan untuk frekuensi. Pembetulan Agresti-Coll ialah penggantian dalam formula Wald kekerapan kejadian ciri dalam sampel (p) dengan p`, apabila mengira yang 2 ditambah kepada pengangka dan 4 ditambah kepada penyebut, iaitu, p` = (X + 2) / (N + 4), di mana X ialah bilangan peserta kajian yang mempunyai ciri yang sedang dikaji, dan N ialah saiz sampel. Pengubahsuaian ini menghasilkan keputusan yang hampir sama dengan formula Wilson, kecuali apabila kekerapan peristiwa menghampiri 0% atau 100% dan sampel adalah kecil. Sebagai tambahan kepada kaedah di atas untuk mengira selang keyakinan untuk frekuensi, pembetulan kesinambungan telah dicadangkan untuk kedua-dua kaedah Wald dan Wilson untuk sampel kecil, tetapi kajian telah menunjukkan bahawa penggunaannya tidak sesuai.
Mari kita pertimbangkan aplikasi kaedah di atas untuk mengira selang keyakinan menggunakan dua contoh. Dalam kes pertama, kami mengkaji sampel besar 1,000 peserta kajian yang dipilih secara rawak, di mana 450 daripadanya mempunyai sifat yang dikaji (ini boleh menjadi faktor risiko, hasil, atau sebarang sifat lain), mewakili kekerapan 0.45, atau 45 %. Dalam kes kedua, kajian dijalankan menggunakan sampel yang kecil, katakan, hanya 20 orang, dan hanya 1 peserta kajian (5%) mempunyai sifat yang dikaji. Selang keyakinan menggunakan kaedah Wald, kaedah Wald dengan pembetulan Agresti-Coll, dan kaedah Wilson dikira menggunakan kalkulator dalam talian yang dibangunkan oleh Jeff Sauro (http://www. /wald. htm). Selang keyakinan yang diperbetulkan kesinambungan Wilson dikira menggunakan kalkulator yang disediakan oleh Wassar Stats: Web Site for Statistical Computation (http://faculty.vassar.edu/lowry/prop1.html). Pengiraan transformasi Angular Fisher dilakukan secara manual menggunakan nilai t kritikal untuk 19 dan 999 darjah kebebasan, masing-masing. Keputusan pengiraan dibentangkan dalam jadual untuk kedua-dua contoh.
Selang keyakinan dikira dalam enam cara berbeza untuk dua contoh yang diterangkan dalam teks
Kaedah pengiraan selang keyakinan |
P=0.0500, atau 5% | 95% CI untuk X=450, N=1000, P=0.4500 atau 45% |
–0,0455–0,2541 | ||
Wald dengan pembetulan Agresti–Coll | <,0001–0,2541 | |
Wilson dengan pembetulan kesinambungan | ||
Clopper–Pearson "kaedah tepat" | ||
Transformasi sudut | <0,0001–0,1967 |
Seperti yang dapat dilihat dari jadual, untuk contoh pertama selang keyakinan yang dikira menggunakan kaedah Wald "diterima secara umum" memasuki rantau negatif, yang tidak boleh berlaku untuk frekuensi. Malangnya, kejadian sebegitu tidak jarang berlaku dalam kesusasteraan Rusia. Cara tradisional untuk menyampaikan data dari segi kekerapan dan ralatnya sebahagiannya menutupi masalah ini. Sebagai contoh, jika kekerapan kejadian sesuatu sifat (dalam peratusan) dibentangkan sebagai 2.1 ± 1.4, maka ini tidak "menyinggung mata" seperti 2.1% (95% CI: -0.7; 4.9), walaupun dan bermakna benda yang sama. Kaedah Wald dengan pembetulan Agresti–Coll dan pengiraan menggunakan penjelmaan sudut memberikan batas bawah yang cenderung kepada sifar. Kaedah pembetulan kesinambungan Wilson dan "kaedah tepat" menghasilkan selang keyakinan yang lebih luas daripada kaedah Wilson. Untuk contoh kedua, semua kaedah memberikan kira-kira selang keyakinan yang sama (perbezaan hanya muncul dalam perseribu), yang tidak menghairankan, kerana kekerapan kejadian dalam contoh ini tidak jauh berbeza daripada 50%, dan saiz sampel adalah agak besar.
Bagi pembaca yang berminat dalam masalah ini, kami boleh mengesyorkan karya R. G. Newcombe dan Brown, Cai dan Dasgupta, yang memberikan kebaikan dan keburukan menggunakan 7 dan 10 kaedah berbeza untuk mengira selang keyakinan, masing-masing. Di antara manual domestik, kami mengesyorkan buku itu dan, sebagai tambahan kepada penerangan terperinci tentang teori, membentangkan kaedah Wald dan Wilson, serta kaedah untuk mengira selang keyakinan dengan mengambil kira taburan frekuensi binomial. Selain kalkulator dalam talian percuma (http://www. /wald. htm dan http://faculty. vassar. edu/lowry/prop1.html), selang keyakinan untuk frekuensi (dan bukan sahaja!) boleh dikira menggunakan Program CIA ( Confidence Intervals Analysis), yang boleh dimuat turun dari http://www. sekolah perubatan. soton. ac. uk/cia/ .
Artikel seterusnya akan melihat cara univariate untuk membandingkan data kualitatif.
Bibliografi
Banerji A. Statistik perubatan dalam bahasa yang jelas: kursus pengenalan / A. Banerjee. – M.: Perubatan Praktikal, 2007. – 287 p. Statistik perubatan / . – M.: Agensi Maklumat Perubatan, 2007. – 475 p. Glanz S. Statistik perubatan dan biologi / S. Glanz. – M.: Praktika, 1998. Jenis data, ujian pengedaran dan statistik deskriptif // Ekologi Manusia – 2008. – No. 1. – P. 52–58. Zhizhin K. S.. Statistik perubatan: buku teks / . – Rostov n/d: Phoenix, 2007. – 160 p. Perangkaan perubatan gunaan / , . - St Petersburg. : Foliot, 2003. – 428 p. Lakin G. F. Biometrik / . – M.: Higher School, 1990. – 350 p. Perubatan V. A. Statistik matematik dalam perubatan / , . – M.: Kewangan dan Perangkaan, 2007. – 798 p. Statistik matematik dalam penyelidikan klinikal / , . – M.: GEOTAR-MED, 2001. – 256 hlm. Junkerov V. DAN. Pemprosesan perubatan dan statistik data penyelidikan perubatan / , . - St Petersburg. : VmedA, 2002. – 266 p. Agresti A. Anggaran adalah lebih baik daripada tepat untuk anggaran selang perkadaran binomial / A. Agresti, B. Coull // ahli statistik Amerika. – 1998. – N 52. – P. 119–126. Altman D. Statistik dengan yakin // D. Altman, D. Machin, T. Bryant, M. J. Gardner. – London: BMJ Books, 2000. – 240 p. Brown L.D. Anggaran selang untuk perkadaran binomial / L. D. Brown, T. T. Cai, A. Dasgupta // Sains statistik. – 2001. – N 2. – P. 101–133. Clopper C.J. Penggunaan had keyakinan atau fiducial yang digambarkan dalam kes binomial / C. J. Clopper, E. S. Pearson // Biometrika. – 1934. – N 26. – P. 404–413. Garcia-Perez M. A. Pada selang keyakinan untuk parameter binomial / M. A. Garcia-Perez // Kualiti dan kuantiti. – 2005. – N 39. – P. 467–481. Motulsky H. Biostatistik intuitif // H. Motulsky. – Oxford: Oxford University Press, 1995. – 386 hlm. Newcombe R. G. Selang Keyakinan Dua Sebelah untuk Perkadaran Tunggal: Perbandingan Tujuh Kaedah / R. G. Newcombe // Statistik dalam Perubatan. – 1998. – N. 17. – P. 857–872. Sauro J. Menganggar kadar penyiapan daripada sampel kecil menggunakan selang keyakinan binomial: perbandingan dan cadangan / J. Sauro, J. R. Lewis // Prosiding mesyuarat tahunan masyarakat faktor manusia dan ergonomik. – Orlando, FL, 2005. Wald A. Had keyakinan untuk fungsi pengedaran berterusan // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. – 1939. – N 10. – P. 105–118. Wilson E.B. Inferens berkemungkinan, undang-undang penggantian, dan inferens statistik / E. B. Wilson // Journal of American Statistical Association. – 1927. – N 22. – P. 209–212.SELANG KEYAKINAN UNTUK PERKADAR
A. M. Grjibovski
Institut Kesihatan Awam Negara, Oslo, Norway
Artikel ini membentangkan beberapa kaedah untuk pengiraan selang keyakinan untuk perkadaran binomial, iaitu, Wald, Wilson, arcsine, Agresti-Coull dan kaedah Clopper-Pearson yang tepat. Makalah ini hanya memberikan pengenalan umum kepada masalah anggaran selang keyakinan bagi perkadaran binomial dan tujuannya bukan sahaja untuk merangsang pembaca menggunakan selang keyakinan apabila membentangkan hasil penyelidikan empirikal mereka sendiri, tetapi juga untuk menggalakkan mereka merujuk buku statistik. sebelum menganalisis data sendiri dan menyediakan manuskrip.
Kata kunci: selang keyakinan, perkadaran
Maklumat perhubungan:
– Penasihat Kanan, Institut Kesihatan Awam Negara, Oslo, Norway
Mana-mana sampel hanya memberikan gambaran anggaran populasi umum, dan semua ciri statistik sampel (min, mod, varians...) adalah beberapa anggaran atau katakan anggaran parameter umum, yang dalam kebanyakan kes tidak dapat dikira disebabkan kepada ketidakupayaan penduduk umum (Rajah 20).
Rajah 20. Ralat pensampelan
Tetapi anda boleh menentukan selang di mana, dengan tahap kebarangkalian tertentu, nilai sebenar (umum) bagi ciri statistik terletak. Selang ini dipanggil d selang keyakinan (CI).
Jadi nilai purata am dengan kebarangkalian 95% terletak di dalamnya
dari hingga, (20)
di mana t – nilai jadual ujian Pelajar untuk α =0.05 dan f= n-1
CI 99% juga boleh didapati, dalam kes ini t dipilih untuk α =0,01.
Apakah kepentingan praktikal selang keyakinan?
Selang keyakinan yang luas menunjukkan bahawa min sampel tidak menggambarkan dengan tepat min populasi. Ini biasanya disebabkan oleh saiz sampel yang tidak mencukupi, atau kepelbagaiannya, i.e. penyebaran yang besar. Kedua-duanya memberikan ralat min yang lebih besar dan, dengan itu, CI yang lebih luas. Dan ini adalah asas untuk kembali ke peringkat perancangan penyelidikan.
Had atas dan bawah CI memberikan anggaran sama ada keputusan akan menjadi signifikan secara klinikal
Marilah kita memikirkan secara terperinci persoalan tentang kepentingan statistik dan klinikal hasil kajian sifat kumpulan. Mari kita ingat bahawa tugas statistik adalah untuk mengesan sekurang-kurangnya beberapa perbezaan dalam populasi umum berdasarkan data sampel. Cabaran untuk doktor adalah untuk mengesan perbezaan (bukan sebarangan) yang akan membantu diagnosis atau rawatan. Dan kesimpulan statistik tidak selalu menjadi asas untuk kesimpulan klinikal. Oleh itu, penurunan hemoglobin yang ketara secara statistik sebanyak 3 g/l tidaklah membimbangkan. Dan, sebaliknya, jika beberapa masalah dalam tubuh manusia tidak tersebar luas di peringkat keseluruhan populasi, ini bukanlah alasan untuk tidak menangani masalah ini.
|
Mari kita lihat keadaan ini contoh. Penyelidik tertanya-tanya sama ada kanak-kanak lelaki yang telah menderita sejenis penyakit berjangkit ketinggalan di belakang rakan sebaya mereka dalam pertumbuhan. Untuk tujuan ini, satu kajian sampel telah dijalankan di mana 10 orang kanak-kanak lelaki yang telah menghidap penyakit ini mengambil bahagian. Keputusan dibentangkan dalam Jadual 23. Jadual 23. Keputusan pemprosesan statistik
Daripada pengiraan ini menunjukkan bahawa purata ketinggian sampel bagi kanak-kanak lelaki berumur 10 tahun yang telah mengalami beberapa penyakit berjangkit adalah hampir normal (132.5 cm). Walau bagaimanapun, had bawah selang keyakinan (126.6 cm) menunjukkan bahawa terdapat 95% kebarangkalian bahawa purata ketinggian sebenar kanak-kanak ini sepadan dengan konsep "ketinggian pendek", i.e. kanak-kanak ini terbantut. Dalam contoh ini, keputusan pengiraan selang keyakinan adalah signifikan secara klinikal. |
|||||||||||||||||||
Sasaran– ajar pelajar algoritma untuk mengira selang keyakinan parameter statistik.
Apabila memproses data secara statistik, min aritmetik yang dikira, pekali variasi, pekali korelasi, kriteria perbezaan dan statistik titik lain harus menerima had keyakinan kuantitatif, yang menunjukkan kemungkinan turun naik penunjuk dalam arah yang lebih kecil dan lebih besar dalam selang keyakinan.
Contoh 3.1
.
Pengagihan kalsium dalam serum darah monyet, seperti yang telah ditetapkan sebelum ini, dicirikan oleh petunjuk sampel berikut: = 11.94 mg%;  = 0.127 mg%; n= 100. Ia diperlukan untuk menentukan selang keyakinan bagi purata am (
= 0.127 mg%; n= 100. Ia diperlukan untuk menentukan selang keyakinan bagi purata am (  ) dengan kebarangkalian keyakinan P
= 0,95.
) dengan kebarangkalian keyakinan P
= 0,95.
Purata am terletak dengan kebarangkalian tertentu dalam selang:
 , Di mana
, Di mana  – sampel min aritmetik; t- Ujian pelajar;
– sampel min aritmetik; t- Ujian pelajar;  – ralat min aritmetik.
– ralat min aritmetik.
Menggunakan jadual "Nilai ujian-t pelajar" kami mencari nilainya
 dengan kebarangkalian keyakinan 0.95 dan bilangan darjah kebebasan k= 100-1 = 99. Ia bersamaan dengan 1.982. Bersama-sama dengan nilai-nilai min aritmetik dan ralat statistik, kami menggantikannya ke dalam formula:
dengan kebarangkalian keyakinan 0.95 dan bilangan darjah kebebasan k= 100-1 = 99. Ia bersamaan dengan 1.982. Bersama-sama dengan nilai-nilai min aritmetik dan ralat statistik, kami menggantikannya ke dalam formula:
atau 11.69  12,19
12,19
Oleh itu, dengan kebarangkalian 95%, boleh dinyatakan bahawa purata am bagi taburan normal ini adalah antara 11.69 dan 12.19 mg%.
Contoh 3.2
. Tentukan sempadan selang keyakinan 95% untuk varians am (  ) pengagihan kalsium dalam darah monyet, jika diketahui bahawa
) pengagihan kalsium dalam darah monyet, jika diketahui bahawa  = 1.60, pada n
= 100.
= 1.60, pada n
= 100.
Untuk menyelesaikan masalah anda boleh menggunakan formula berikut:
di mana  – ralat statistik penyebaran.
– ralat statistik penyebaran.
Kami mencari ralat varians pensampelan menggunakan formula:  . Ia bersamaan dengan 0.11. Maknanya t- kriteria dengan kebarangkalian keyakinan 0.95 dan bilangan darjah kebebasan k= 100–1 = 99 diketahui daripada contoh sebelumnya.
. Ia bersamaan dengan 0.11. Maknanya t- kriteria dengan kebarangkalian keyakinan 0.95 dan bilangan darjah kebebasan k= 100–1 = 99 diketahui daripada contoh sebelumnya.
Mari gunakan formula dan dapatkan:
atau 1.38  1,82
1,82
Lebih tepat lagi, selang keyakinan varians am boleh dibina menggunakan  (chi-square) - Ujian Pearson. Mata kritikal untuk kriteria ini diberikan dalam jadual khas. Apabila menggunakan kriteria
(chi-square) - Ujian Pearson. Mata kritikal untuk kriteria ini diberikan dalam jadual khas. Apabila menggunakan kriteria  Untuk membina selang keyakinan, aras keertian dua belah digunakan. Untuk had bawah, aras keertian dikira menggunakan formula
Untuk membina selang keyakinan, aras keertian dua belah digunakan. Untuk had bawah, aras keertian dikira menggunakan formula  , untuk bahagian atas -
, untuk bahagian atas -  . Sebagai contoh, untuk tahap keyakinan
. Sebagai contoh, untuk tahap keyakinan  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. Sehubungan itu, mengikut jadual taburan nilai kritikal
= 0.990. Sehubungan itu, mengikut jadual taburan nilai kritikal  , dengan tahap keyakinan yang dikira dan bilangan darjah kebebasan k= 100 – 1= 99, cari nilainya
, dengan tahap keyakinan yang dikira dan bilangan darjah kebebasan k= 100 – 1= 99, cari nilainya  Dan
Dan  . Kita mendapatkan
. Kita mendapatkan  bersamaan dengan 135.80, dan
bersamaan dengan 135.80, dan  bersamaan dengan 70.06.
bersamaan dengan 70.06.
Untuk mencari had keyakinan bagi varians am menggunakan  Mari kita gunakan formula: untuk sempadan bawah
Mari kita gunakan formula: untuk sempadan bawah  , untuk sempadan atas
, untuk sempadan atas  . Mari gantikan nilai yang ditemui untuk data masalah
. Mari gantikan nilai yang ditemui untuk data masalah  ke dalam formula:
ke dalam formula:  =
1,17;
=
1,17; = 2.26. Oleh itu, dengan kebarangkalian keyakinan P= 0.99 atau 99% varians am akan terletak dalam julat dari 1.17 hingga 2.26 mg% inklusif.
= 2.26. Oleh itu, dengan kebarangkalian keyakinan P= 0.99 atau 99% varians am akan terletak dalam julat dari 1.17 hingga 2.26 mg% inklusif.
Contoh 3.3 . Di antara 1000 biji gandum daripada kumpulan yang diterima di lif, 120 biji didapati dijangkiti ergot. Ia adalah perlu untuk menentukan sempadan kemungkinan perkadaran umum benih yang dijangkiti dalam kelompok gandum tertentu.
Adalah dinasihatkan untuk menentukan had keyakinan untuk bahagian umum untuk semua nilai yang mungkin menggunakan formula:
 ,
,
di mana n – bilangan pemerhatian; m– saiz mutlak salah satu kumpulan; t– sisihan normal.
Kadar sampel benih yang dijangkiti ialah  atau 12%. Dengan kebarangkalian keyakinan R= 95% sisihan ternormal ( t-Ujian pelajar di k
=
atau 12%. Dengan kebarangkalian keyakinan R= 95% sisihan ternormal ( t-Ujian pelajar di k
=
 )t
= 1,960.
)t
= 1,960.
Kami menggantikan data yang tersedia ke dalam formula:
Oleh itu sempadan selang keyakinan adalah sama dengan  = 0.122–0.041 = 0.081, atau 8.1%;
= 0.122–0.041 = 0.081, atau 8.1%;  = 0.122 + 0.041 = 0.163, atau 16.3%.
= 0.122 + 0.041 = 0.163, atau 16.3%.
Oleh itu, dengan kebarangkalian keyakinan 95% boleh dinyatakan bahawa perkadaran umum benih yang dijangkiti adalah antara 8.1 dan 16.3%.
Contoh 3.4 . Pekali variasi yang mencirikan variasi kalsium (mg%) dalam serum darah monyet adalah bersamaan dengan 10.6%. Saiz sampel n= 100. Ia adalah perlu untuk menentukan sempadan selang keyakinan 95% untuk parameter umum CV.
Had selang keyakinan untuk pekali umum variasi CV ditentukan oleh formula berikut:
 Dan
Dan  , Di mana K
nilai perantaraan yang dikira oleh formula
, Di mana K
nilai perantaraan yang dikira oleh formula  .
.
Mengetahui bahawa dengan keyakinan kebarangkalian R= 95% sisihan ternormal (Ujian pelajar di k
=
 )t
= 1.960, mari kita hitung nilai dahulu KEPADA:
)t
= 1.960, mari kita hitung nilai dahulu KEPADA:
 .
.
 atau 9.3%
atau 9.3%
 atau 12.3%
atau 12.3%
Oleh itu, pekali umum variasi dengan tahap keyakinan 95% terletak dalam julat dari 9.3 hingga 12.3%. Dengan sampel berulang, pekali variasi tidak akan melebihi 12.3% dan tidak akan di bawah 9.3% dalam 95 kes daripada 100.
Soalan untuk mengawal diri:

Masalah untuk penyelesaian bebas.
1. Purata peratusan lemak dalam susu semasa penyusuan lembu kacukan Kholmogory adalah seperti berikut: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. Wujudkan selang keyakinan untuk min umum pada tahap keyakinan 95% (20 mata).
2. Pada 400 pokok rai hibrid, bunga pertama muncul secara purata 70.5 hari selepas disemai. Sisihan piawai ialah 6.9 hari. Tentukan ralat min dan selang keyakinan bagi min dan varians am pada aras keertian W= 0.05 dan W= 0.01 (25 mata).
3. Apabila mengkaji panjang daun 502 spesimen strawberi taman, data berikut diperolehi:
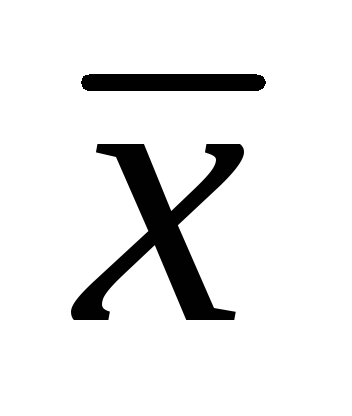 = 7.86 cm; σ = 1.32 cm,
= 7.86 cm; σ = 1.32 cm,  =± 0.06 cm Tentukan selang keyakinan bagi min populasi aritmetik dengan aras keertian 0.01; 0.02; 0.05. (25 mata).
=± 0.06 cm Tentukan selang keyakinan bagi min populasi aritmetik dengan aras keertian 0.01; 0.02; 0.05. (25 mata).
4. Dalam kajian 150 lelaki dewasa, ketinggian purata ialah 167 cm, dan σ = 6 cm Apakah had bagi min am dan varians am dengan kebarangkalian keyakinan 0.99 dan 0.95? (25 mata).
5. Pengagihan kalsium dalam serum darah monyet dicirikan oleh penunjuk terpilih berikut:
 = 11.94 mg%, σ
= 1,27, n
= 100. Bina selang keyakinan 95% untuk min am taburan ini. Kira pekali variasi (25 mata).
= 11.94 mg%, σ
= 1,27, n
= 100. Bina selang keyakinan 95% untuk min am taburan ini. Kira pekali variasi (25 mata).
6. Jumlah kandungan nitrogen dalam plasma darah tikus albino pada umur 37 dan 180 hari telah dikaji. Keputusan dinyatakan dalam gram setiap 100 cm 3 plasma. Pada umur 37 hari, 9 ekor tikus mempunyai: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. Pada umur 180 hari, 8 ekor tikus mempunyai: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. Tetapkan selang keyakinan untuk perbezaan pada tahap keyakinan 0.95 (50 mata).
7. Tentukan sempadan selang keyakinan 95% untuk varians umum taburan kalsium (mg%) dalam serum darah monyet, jika untuk taburan ini saiz sampel ialah n = 100, ralat statistik varians sampel s σ 2 = 1.60 (40 mata).
8. Tentukan sempadan selang keyakinan 95% bagi varians umum taburan 40 spikelet gandum sepanjang panjang (σ 2 = 40.87 mm 2). (25 mata).
9. Merokok dianggap sebagai faktor utama yang terdedah kepada penyakit pulmonari obstruktif. Merokok pasif tidak dianggap sebagai faktor sedemikian. Para saintis meragui tidak berbahaya merokok pasif dan meneliti patensi saluran pernafasan bagi perokok bukan perokok, pasif dan aktif. Untuk mencirikan keadaan saluran pernafasan, kami mengambil salah satu penunjuk fungsi pernafasan luaran - kadar aliran volumetrik maksimum pada pertengahan tamat tempoh. Penurunan penunjuk ini adalah tanda halangan saluran pernafasan. Data tinjauan ditunjukkan dalam jadual.
|
Bilangan orang yang diperiksa |
Kadar aliran pertengahan ekspirasi maksimum, l/s |
||
|
Sisihan piawai |
|||
|
Bukan perokok |
|||
|
bekerja di kawasan larangan merokok | |||
|
bekerja dalam bilik berasap | |||
|
Merokok |
|||
|
menghisap sebilangan kecil rokok | |||
|
purata bilangan perokok | |||
|
menghisap sejumlah besar rokok | |||
Menggunakan data jadual, cari selang keyakinan 95% untuk min keseluruhan dan varians keseluruhan bagi setiap kumpulan. Apakah perbezaan antara kumpulan? Bentangkan keputusan secara grafik (25 mata).
10. Tentukan sempadan selang keyakinan 95% dan 99% untuk varians umum dalam bilangan anak babi dalam 64 ekor farrow, jika ralat statistik varians sampel s σ 2 = 8.25 (30 mata).
11. Adalah diketahui bahawa purata berat arnab ialah 2.1 kg. Tentukan sempadan selang keyakinan 95% dan 99% untuk min dan varians am pada n= 30, σ = 0.56 kg (25 mata).
12. Kandungan bijian telinga diukur untuk 100 biji ( X), panjang telinga ( Y) dan jisim bijirin di dalam telinga ( Z). Cari selang keyakinan untuk min dan varians am pada P 1
= 0,95, P 2
= 0,99, P 3
= 0.999 jika
 = 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 mata).
= 19, = 6.766 cm, = 0.554 g; σ x 2 = 29.153, σ y 2 = 2. 111, σ z 2 = 0. 064. (25 mata).
13. Dalam 100 biji gandum musim sejuk yang dipilih secara rawak, bilangan spikelet telah dikira. Populasi sampel dicirikan oleh penunjuk berikut:
 = 15 spikelet dan σ = 2.28 pcs. Tentukan dengan ketepatan apa hasil purata diperolehi (
= 15 spikelet dan σ = 2.28 pcs. Tentukan dengan ketepatan apa hasil purata diperolehi (  ) dan bina selang keyakinan untuk min dan varians am pada tahap keertian 95% dan 99% (30 mata).
) dan bina selang keyakinan untuk min dan varians am pada tahap keertian 95% dan 99% (30 mata).
14. Bilangan rusuk pada kulit moluska fosil Orthambonit kaligramma:
Adalah diketahui bahawa n = 19, σ = 4.25. Tentukan sempadan selang keyakinan bagi min am dan varians am pada aras keertian W = 0.01 (25 mata).
15. Untuk menentukan hasil susu di ladang tenusu komersial, produktiviti 15 ekor lembu ditentukan setiap hari. Mengikut data bagi tahun tersebut, setiap lembu memberikan secara purata jumlah susu yang berikut setiap hari (l): 22; 19; 25; 20; 27; 17; tiga puluh; 21; 18; 24; 26; 23; 25; 20; 24. Bina selang keyakinan untuk varians am dan min aritmetik. Bolehkah kita menjangkakan purata hasil susu tahunan bagi setiap lembu ialah 10,000 liter? (50 mata).
16. Untuk menentukan purata hasil gandum untuk perusahaan pertanian, pemotongan dijalankan pada plot percubaan seluas 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 dan 2 hektar. Produktiviti (c/ha) daripada plot ialah 39.4; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; 29 masing-masing. Bina selang keyakinan untuk varians am dan min aritmetik. Bolehkah kita menjangkakan purata hasil pertanian ialah 42 c/ha? (50 mata).