Güvenilirlik aralığı. Güven aralığı
Ve diğerleri.Hepsi, bir örneklem değil, genel popülasyon olsaydı elde edilebilecek teorik meslektaşlarının tahminleridir. Ama ne yazık ki, genel nüfus çok pahalı ve çoğu zaman ulaşılamıyor.
Aralık tahmini kavramı
Herhangi bir örnek tahmininde bir miktar dağılım vardır, çünkü belirli bir örneklemdeki değerlere bağlı olarak rastgele bir değişkendir. Bu nedenle, daha güvenilir istatistiksel çıkarımlar için, yalnızca nokta tahmini değil, aynı zamanda olasılığı yüksek olan aralığı da bilmek gerekir. γ (gama) tahmini göstergeyi kapsar θ (teta).
Resmen, bunlar böyle iki değerdir (istatistikler) T1(X) ve T2(X), ne T1< T 2 , bunun için belirli bir olasılık düzeyinde γ koşul karşılandı:
kısacası büyük ihtimalle γ veya daha fazla gerçek değer noktalar arasındadır T1(X) ve T2(X) alt ve üst sınırlar olarak adlandırılan güven aralığı.
Güven aralıkları oluşturmanın koşullarından biri, maksimum darlığıdır, yani. mümkün olduğunca kısa olmalıdır. Arzu oldukça doğal çünkü. araştırmacı, istenen parametrenin bulgusunu daha doğru bir şekilde yerelleştirmeye çalışır.
Güven aralığının, dağılımın maksimum olasılıklarını kapsaması gerektiği sonucu çıkar. ve skorun kendisi merkezde olsun.
![]()
Yani, (tahminden gerçek göstergenin) yukarı doğru sapma olasılığı, aşağı doğru sapma olasılığına eşittir. Ayrıca çarpık dağılımlar için sağdaki aralığın soldaki aralığa eşit olmadığına da dikkat edilmelidir.
Yukarıdaki şekil, güven düzeyi ne kadar yüksek olursa, aralığın o kadar geniş olduğunu açıkça göstermektedir - doğrudan bir ilişki.
Bu, bilinmeyen parametrelerin aralık tahmini teorisine küçük bir girişti. Matematiksel beklenti için güven sınırlarını bulmaya devam edelim.
Matematiksel beklenti için güven aralığı
Orijinal veriler dağıtılırsa, ortalama normal bir değer olacaktır. Bu, normal değerlerin doğrusal bir kombinasyonunun da normal bir dağılıma sahip olduğu kuralından kaynaklanmaktadır. Bu nedenle, olasılıkları hesaplamak için normal dağılım yasasının matematiksel aygıtını kullanabiliriz.
Bununla birlikte, bu, genellikle bilinmeyen beklenen değer ve varyans olmak üzere iki parametrenin bilgisini gerektirecektir. Elbette, parametreler (aritmetik ortalama ve ) yerine tahminleri kullanabilirsiniz, ancak o zaman ortalamanın dağılımı oldukça normal olmayacak, biraz düzleşecektir. İrlanda Vatandaşı William Gosset, keşfini Biometrica'nın Mart 1908 sayısında yayınlarken bu gerçeği ustalıkla kaydetti. Gizlilik amacıyla Gosset, Student ile imzaladı. Student'in t-dağılımı bu şekilde ortaya çıktı.
Ancak, K. Gauss tarafından astronomik gözlemlerdeki hataların analizinde kullanılan verilerin normal dağılımı, karasal yaşamda son derece nadirdir ve bunu tespit etmek oldukça zordur (yüksek doğruluk için yaklaşık 2 bin gözlem gereklidir). Bu nedenle normallik varsayımını bırakmak ve orijinal verilerin dağılımına bağlı olmayan yöntemler kullanmak en iyisidir.
Soru ortaya çıkıyor: Bilinmeyen bir dağılımın verilerinden hesaplanırsa aritmetik ortalamanın dağılımı nedir? Cevap, olasılık teorisinde iyi bilinen tarafından verilir. Merkezi Limit Teoremi(CPT). Matematikte, bunun birkaç versiyonu vardır (formülasyonlar yıllar içinde rafine edilmiştir), ancak hepsi, kabaca konuşursak, çok sayıda bağımsız rastgele değişkenin toplamının normal dağılım yasasına uyduğu ifadesine gelir.
Aritmetik ortalama hesaplanırken rastgele değişkenlerin toplamı kullanılır. Bundan, aritmetik ortalamanın, beklenen değerin orijinal verilerin beklenen değeri ve varyansın olduğu normal bir dağılıma sahip olduğu ortaya çıkıyor.
Akıllı insanlar CLT'yi nasıl kanıtlayacağını bilirler, ancak bunu Excel'de yapılan bir deney yardımıyla doğrulayacağız. 50 tekdüze dağıtılmış rastgele değişkenin bir örneğini simüle edelim (RANDOMBETWEEN Excel işlevini kullanarak). Daha sonra böyle 1000 örnek yapacağız ve her biri için aritmetik ortalamayı hesaplayacağız. dağılımlarına bakalım.

Ortalamanın dağılımının normal yasaya yakın olduğu görülebilir. Numunelerin hacmi ve sayıları daha da büyük yapılırsa, benzerlik daha da iyi olacaktır.
Artık CLT'nin geçerliliğini kendimiz gördüğümüze göre, belirli bir olasılıkla gerçek ortalamayı veya matematiksel beklentiyi kapsayan aritmetik ortalama için güven aralıklarını kullanarak, hesaplayabiliriz.
Alt ve üst sınırları belirlemek için normal dağılımın parametrelerini bilmek gerekir. Kural olarak, bunlar değildir, bu nedenle tahminler kullanılır: aritmetik ortalama ve örnek varyans. Yine, bu yöntem yalnızca büyük örnekler için iyi bir yaklaşıklık verir. Örnekler küçük olduğunda, genellikle Student dağılımının kullanılması önerilir. İnanma! Öğrencinin ortalama dağılımı, yalnızca orijinal veri normal bir dağılıma sahip olduğunda, yani neredeyse hiçbir zaman gerçekleşir. Bu nedenle, gerekli veri miktarı için minimum çubuğu hemen ayarlamak ve asimptotik olarak doğru yöntemleri kullanmak daha iyidir. 30 gözlemin yeterli olduğunu söylüyorlar. 50 al - yanlış gidemezsin.
![]()
1.2 güven aralığının alt ve üst sınırlarıdır
– örnek aritmetik ortalama
s0– örnek standart sapma (tarafsız)
n - örnek boyut
γ – güven düzeyi (genellikle 0,9, 0,95 veya 0,99'a eşittir)
c γ =Φ -1 ((1+γ)/2) standart normal dağılım fonksiyonunun tersidir. Basit bir ifadeyle, bu, aritmetik ortalamadan alt veya üst sınıra kadar standart hataların sayısıdır (belirtilen üç olasılık, 1.64, 1.96 ve 2.58 değerlerine karşılık gelir).
Formülün özü, aritmetik ortalamanın alınması ve ardından ondan belirli bir miktarın ayrılmasıdır ( y ile) standart hatalar ( s 0 /√n). Her şey biliniyor, al ve say.
PC'lerin toplu kullanımından önce, normal dağılım fonksiyonunun ve tersinin değerlerini elde etmek için kullandılar. Hala kullanılıyorlar, ancak hazır Excel formüllerine dönmek daha verimli. Yukarıdaki formüldeki tüm öğeler ( , ve ) Excel'de kolayca hesaplanabilir. Ancak güven aralığını hesaplamak için hazır bir formül de var - GÜVEN NORMASI. Sözdizimi aşağıdaki gibidir.
GÜVEN NORM(alfa; standart_dev; boyut)
alfa– yukarıdaki gösterimde 1-γ'ye eşit olan anlamlılık düzeyi veya güven düzeyi, yani. matematiksel olma olasılığıbeklenti güven aralığının dışında olacaktır. 0,95 güven düzeyiyle alfa 0,05'tir vb.
standart_offörnek verilerin standart sapmasıdır. Standart hatayı hesaplamanıza gerek yok, Excel n'nin köküne böler.
boyut– numune boyutu (n).
GÜVENİLİRLİK.NORM işlevinin sonucu, güven aralığını hesaplama formülündeki ikinci terimdir, yani. yarı aralık. Buna göre alt ve üst noktalar ortalama ± elde edilen değerdir.
Böylece, ilk verilerin dağılımına bağlı olmayan aritmetik ortalama için güven aralıklarını hesaplamak için evrensel bir algoritma oluşturmak mümkündür. Evrenselliğin bedeli asimptotik doğasıdır, yani. nispeten büyük örnekler kullanma ihtiyacı. Ancak, modern teknoloji çağında, doğru miktarda veri toplamak genellikle zor değildir.
Bir Güven Aralığı Kullanarak İstatistiksel Hipotezleri Test Etme
(modül 111)
İstatistikte çözülen temel sorunlardan biri de şudur. Özetle, özü budur. Örneğin, genel nüfusun beklentisinin bir değere eşit olduğu varsayımı yapılır. Daha sonra, belirli bir beklenti ile gözlemlenebilen örnek ortalamaların dağılımı oluşturulur. Ardından, bu koşullu dağılımda gerçek ortalamanın nerede olduğuna bakacağız. İzin verilen sınırların ötesine geçerse, böyle bir ortalamanın ortaya çıkması pek olası değildir ve deneyin tek bir tekrarıyla, başarılı bir şekilde reddedilen öne sürülen hipotezle çelişen neredeyse imkansızdır. Ortalama kritik seviyenin ötesine geçmezse, hipotez reddedilmez (ancak kanıtlanmaz!).
Dolayısıyla, bizim durumumuzda beklenti için güven aralıkları yardımıyla bazı hipotezleri de test edebilirsiniz. Bunu yapmak çok kolay. Bir örnek için aritmetik ortalamanın 100 olduğunu varsayalım. Hipotez, beklenen değerin, örneğin 90 olduğu yönünde test ediliyor. Yani, soruyu ilkel olarak koyarsak, kulağa şöyle geliyor: ortalama 90'a eşit, gözlemlenen ortalama 100'dü?
Bu soruyu cevaplamak için standart sapma ve örneklem büyüklüğü hakkında ek bilgi gerekli olacaktır. Diyelim ki standart sapma 30 ve gözlem sayısı 64 (kökünü kolayca çıkarmak için). O zaman ortalamanın standart hatası 30/8 veya 3.75'tir. %95 güven aralığını hesaplamak için ortalamanın her iki tarafında iki standart hata ayırmanız gerekecektir (daha doğrusu 1,96). Güven aralığı yaklaşık 100 ± 7,5 veya 92,5 ila 107,5 olacaktır.
Daha fazla akıl yürütme aşağıdaki gibidir. Test edilen değer güven aralığı içindeyse, hipotezle çelişmez, çünkü rastgele dalgalanmaların sınırlarına uyuyor (%95 olasılıkla). Test edilen nokta güven aralığının dışındaysa, böyle bir olayın olasılığı çok küçüktür, her durumda kabul edilebilir seviyenin altındadır. Bu nedenle, hipotez, gözlemlenen verilerle çeliştiği için reddedilir. Bizim durumumuzda beklenti hipotezi güven aralığının dışındadır (test edilen 90 değeri 100±7,5 aralığına dahil değildir), bu nedenle reddedilmelidir. Yukarıdaki ilkel soruyu cevaplayarak şunu söylemelisiniz: hayır, her durumda olamaz, bu çok nadiren olur. Genellikle, bu, güven aralığının oluşturulduğu belirli bir düzeyi değil, hipotezin (p düzeyi) hatalı bir şekilde reddedilme olasılığını gösterir, ancak başka bir zamanda daha fazlası.
Gördüğünüz gibi, ortalama (veya matematiksel beklenti) için bir güven aralığı oluşturmak zor değil. Ana şey özü yakalamak ve sonra işler gidecek. Pratikte çoğu, ortalamanın her iki tarafında yaklaşık iki standart hata olan %95 güven aralığını kullanır.
Şimdilik bu kadar. Herşey gönlünce olsun!
Güven aralıklarının tahmini
Öğrenme hedefleri
İstatistikler aşağıdakileri dikkate alır iki ana görev:
Örnek verilere dayalı bazı tahminlerimiz var ve tahmin edilen parametrenin gerçek değerinin nerede olduğu hakkında bazı olasılık ifadeleri yapmak istiyoruz.
Örnek verilere dayanarak test edilmesi gereken belirli bir hipotezimiz var.
Bu konuda, ilk sorunu ele alıyoruz. Ayrıca bir güven aralığı tanımını da sunuyoruz.
Güven aralığı, bir parametrenin tahmini değeri etrafında oluşturulan ve önceden verilen bir olasılıkla tahmin edilen parametrenin gerçek değerinin nerede olduğunu gösteren bir aralıktır.
Bu konuyla ilgili materyali inceledikten sonra, siz:
tahminin güven aralığının ne olduğunu öğrenin;
istatistiksel problemleri sınıflandırmayı öğrenir;
hem istatistiksel formüller kullanarak hem de yazılım araçlarını kullanarak güven aralıkları oluşturma tekniğinde ustalaşın;
İstatistiksel tahminlerin belirli doğruluk parametrelerine ulaşmak için gerekli örnek boyutlarını belirlemeyi öğrenir.
Örnek özelliklerin dağılımları
T-dağılımı
Yukarıda tartışıldığı gibi, rastgele değişkenin dağılımı, 0 ve 1 parametreleriyle standartlaştırılmış normal dağılıma yakındır. σ'nın değerini bilmediğimiz için, onu bazı s tahminleriyle değiştiririz. Miktar zaten farklı bir dağılıma sahip, yani veya Öğrenci dağılımı n -1 parametresi tarafından belirlenir (serbestlik derecesi sayısı). Bu dağılım normal dağılıma yakındır (n ne kadar büyükse dağılımlar o kadar yakın olur).
Şek. 95  30 serbestlik dereceli öğrenci dağılımı sunulmuştur. Görüldüğü gibi normal dağılıma çok yakındır.
30 serbestlik dereceli öğrenci dağılımı sunulmuştur. Görüldüğü gibi normal dağılıma çok yakındır.
Normal dağılım NORMDAĞ ve NORMINV ile çalışma işlevlerine benzer şekilde, t-dağılımı ile çalışma işlevleri vardır - STUDIST (TDAĞ) ve STUDRASPBR (TINV). Bu işlevlerin kullanımına ilişkin bir örnek, STUDRIST.XLS dosyasında (şablon ve çözüm) ve şek. 96  .
.
Diğer özelliklerin dağılımları
Bildiğimiz gibi, beklenti tahmininin doğruluğunu belirlemek için bir t dağılımına ihtiyacımız var. Varyans gibi diğer parametreleri tahmin etmek için başka dağılımlar gereklidir. Bunlardan ikisi F dağılımı ve x 2 -dağıtım.
Ortalama için güven aralığı
Güven aralığı parametrenin tahmini değeri etrafında oluşturulan ve önceden verilen bir olasılıkla tahmin edilen parametrenin gerçek değerinin nerede olduğunu gösteren bir aralıktır.
Ortalama değer için bir güven aralığının oluşturulması Aşağıdaki şekilde:
Misal
Fast food restoranı, ürün yelpazesini yeni bir sandviç türüyle genişletmeyi planlıyor. Buna olan talebi tahmin etmek için yönetici, daha önce denemiş olanlar arasından rastgele 40 ziyaretçi seçmeyi ve onlardan yeni ürüne yönelik tutumlarını 1'den 10'a kadar bir ölçekte derecelendirmelerini istemeyi planlıyor. Yönetici, talebi tahmin etmek istiyor. yeni ürünün alacağı beklenen puan sayısı ve bu tahmin için %95'lik bir güven aralığı oluşturur. Nasıl yapılır? (SANDWICH1.XLS dosyasına bakın (şablon ve çözüm).
Karar
Bu sorunu çözmek için kullanabilirsiniz. Sonuçlar şek. 97  .
.
Toplam değer için güven aralığı
Bazen örnek verilere göre matematiksel beklentiyi değil, değerlerin toplamını tahmin etmek gerekir. Örneğin, bir denetçinin olduğu bir durumda, bir faturanın ortalama değerini değil, tüm faturaların toplamını tahmin etmek ilgi çekici olabilir.
N toplam eleman sayısı olsun, n örneklem büyüklüğü olsun, T3 örneklemdeki değerlerin toplamı olsun, T" tüm popülasyondaki toplamın tahmini olsun, sonra ![]() , ve güven aralığı formülle hesaplanır, burada s örnek için standart sapmanın tahmini, örnek için ortalamanın tahminidir.
, ve güven aralığı formülle hesaplanır, burada s örnek için standart sapmanın tahmini, örnek için ortalamanın tahminidir.
Misal
Diyelim ki bir vergi dairesi 10.000 vergi mükellefi için toplam vergi iadesi miktarını tahmin etmek istiyor. Mükellef ya bir geri ödeme alır ya da ek vergi öder. 500 kişilik bir örneklem büyüklüğü varsayılarak, geri ödeme tutarı için %95 güven aralığını bulun (bkz. REFUND AMOUNT.XLS dosyası (şablon ve çözüm).
Karar
Bu durum için StatPro'da özel bir prosedür yoktur, ancak, yukarıdaki formüller kullanılarak ortalamanın sınırlarından sınırların elde edilebileceğini görebilirsiniz (Şekil 98).  ).
).
Orantı için güven aralığı
p, müşterilerin bir payının beklentisi olsun ve pv, n büyüklüğünde bir örneklemden elde edilen bu payın tahmini olsun. yeterince büyük olduğu gösterilebilir.  tahmin dağılımı, ortalama p ve standart sapma ile normale yakın olacaktır
tahmin dağılımı, ortalama p ve standart sapma ile normale yakın olacaktır ![]() . Bu durumda tahminin standart hatası şu şekilde ifade edilir:
. Bu durumda tahminin standart hatası şu şekilde ifade edilir:  , ve güven aralığı olarak
, ve güven aralığı olarak  .
.
Misal
Fast food restoranı, ürün yelpazesini yeni bir sandviç türüyle genişletmeyi planlıyor. Buna olan talebi tahmin etmek için yönetici, daha önce denemiş olanlar arasından rastgele 40 ziyaretçi seçti ve onlardan yeni ürüne yönelik tutumlarını 1'den 10'a kadar bir ölçekte derecelendirmelerini istedi. Yönetici, beklenen oranı tahmin etmek istiyor. yeni ürünü en az 6 puandan fazla değerlendiren müşterilerin oranı (bu müşterilerin yeni ürünün tüketicileri olmasını bekliyor).
Karar
Başlangıçta, müşterinin puanı 6 puandan fazlaysa 1, aksi takdirde 0 temelinde yeni bir sütun oluştururuz (SANDWICH2.XLS dosyasına bakın (şablon ve çözüm).
Yöntem 1
1'i sayarak payı tahmin ediyoruz ve ardından formülleri kullanıyoruz.
z cr değeri özel normal dağılım tablolarından alınmıştır (örneğin, %95 güven aralığı için 1,96).
%95'lik bir aralık oluşturmak için bu yaklaşımı ve özel verileri kullanarak aşağıdaki sonuçları elde ederiz (Şekil 99).  ). z cr parametresinin kritik değeri 1,96'dır. Tahminin standart hatası 0.077'dir. Güven aralığının alt sınırı 0,475'tir. Güven aralığının üst sınırı 0.775'tir. Böylece bir yönetici, yeni bir ürüne 6 puan veya daha fazla puan veren müşterilerin yüzdesinin 47,5 ile 77,5 arasında olacağını %95 kesinlik ile varsayabilir.
). z cr parametresinin kritik değeri 1,96'dır. Tahminin standart hatası 0.077'dir. Güven aralığının alt sınırı 0,475'tir. Güven aralığının üst sınırı 0.775'tir. Böylece bir yönetici, yeni bir ürüne 6 puan veya daha fazla puan veren müşterilerin yüzdesinin 47,5 ile 77,5 arasında olacağını %95 kesinlik ile varsayabilir.
Yöntem 2
Bu sorun, standart StatPro araçları kullanılarak çözülebilir. Bunu yapmak için, bu durumda payın Tür sütununun ortalama değeri ile çakıştığını belirtmek yeterlidir. Sonraki başvuru StatPro/İstatistiksel Çıkarım/Tek Örnek Analizi Tür sütununun ortalama değeri (beklenti tahmini) için bir güven aralığı oluşturmak için. Bu durumda elde edilen sonuçlar 1. yöntemin sonucuna çok yakın olacaktır (Şekil 99).
Standart sapma için güven aralığı
s standart sapmanın bir tahmini olarak kullanılır (formül bölüm 1'de verilmiştir). s tahmininin yoğunluk fonksiyonu, t-dağılımı gibi n-1 serbestlik derecesine sahip olan ki-kare fonksiyonudur. Bu dağıtımla çalışmak için özel işlevler vardır CHI2DIST (CHIDIST) ve CHI2OBR (CHIINV) .
Bu durumda güven aralığı artık simetrik olmayacaktır. Sınırların koşullu şeması, Şek. 100 .
Misal
Makine 10 cm çapında parçalar üretmelidir, ancak çeşitli durumlardan dolayı hatalar meydana gelir. Kalite kontrolörü iki şeyle ilgilenir: birincisi, ortalama değer 10 cm olmalıdır; ikinci olarak, bu durumda bile, sapmalar büyükse, birçok ayrıntı reddedilecektir. Her gün 50 parçalık bir numune yapar (QUALITY CONTROL.XLS dosyasına bakın (şablon ve çözüm). Böyle bir numune ne gibi sonuçlar verebilir?
Karar
Ortalama ve standart sapma için %95 güven aralıkları oluşturuyoruz. StatPro/İstatistiksel Çıkarım/ Tek Örnek Analizi(Şek. 101  ).
).
Ayrıca, normal çap dağılımı varsayımını kullanarak, maksimum 0,065 sapma ayarlayarak kusurlu ürünlerin oranını hesaplıyoruz. Arama tablosunun yeteneklerini kullanarak (iki parametre durumunda), reddetme yüzdesinin ortalama değere ve standart sapmaya bağımlılığını oluşturuyoruz (Şekil 102).  ).
).
İki ortalamanın farkı için güven aralığı
Bu, istatistiksel yöntemlerin en önemli uygulamalarından biridir. Durum örnekleri.
Bir giyim mağazası yöneticisi, ortalama bir bayan alışverişçinin mağazada bir erkekten ne kadar daha fazla veya daha az harcadığını bilmek ister.
İki havayolu benzer rotalarda uçuyor. Bir tüketici kuruluşu, her iki havayolu için beklenen ortalama uçuş gecikme süreleri arasındaki farkı karşılaştırmak istiyor.
Şirket, bir şehirde belirli mal türleri için kupon gönderir ve başka bir şehirde göndermez. Yöneticiler, önümüzdeki iki ay boyunca bu ürünlerin ortalama satın alımlarını karşılaştırmak istiyor.
Bir araba satıcısı genellikle sunumlarda evli çiftlerle ilgilenir. Sunuma yönelik kişisel tepkilerini anlamak için çiftlerle genellikle ayrı ayrı görüşülür. Yönetici, erkekler ve kadınlar tarafından verilen derecelendirmelerdeki farkı değerlendirmek istiyor.
Bağımsız numune durumu
Ortalama fark, n 1 + n 2 - 2 serbestlik dereceli bir t dağılımına sahip olacaktır. μ 1 - μ 2 için güven aralığı şu oran ile ifade edilir:

Bu sorun sadece yukarıdaki formüllerle değil, standart StatPro araçlarıyla da çözülebilir. Bunun için başvurmanız yeterli
Oranlar arasındaki fark için güven aralığı
Payların matematiksel beklentisi olsun. Sırasıyla n 1 ve n 2 büyüklüğündeki örneklere dayanan örnek tahminleri olsun. Sonra fark için bir tahmindir. Bu nedenle, bu fark için güven aralığı şu şekilde ifade edilir:
Burada z cr, özel tabloların normal dağılımından elde edilen değerdir (örneğin, %95 güven aralığı için 1,96).
Tahminin standart hatası bu durumda şu bağıntı ile ifade edilir:
 .
.
Misal
Mağaza, büyük indirime hazırlanırken aşağıdaki pazarlama araştırmasını yaptı. İlk 300 alıcı seçildi ve rastgele her biri 150 üyeden oluşan iki gruba ayrıldı. Seçilen tüm alıcılara satışa katılmaları için davetiye gönderildi, ancak yalnızca ilk grubun üyelerine %5 indirim hakkı veren bir kupon iliştirildi. Satış sırasında, seçilen 300 alıcının tamamının alımları kaydedildi. Bir yönetici sonuçları nasıl yorumlayabilir ve kuponlamanın etkinliği hakkında bir yargıya varabilir? (Bkz. COUPONS.XLS dosyası (şablon ve çözüm)).
Karar
Özel durumumuz için, indirim kuponu alan 150 müşteriden 55'i indirimli alışveriş yaptı ve kupon almayan 150 müşteriden sadece 35'i alışveriş yaptı (Şekil 103).  ). Daha sonra numune oranlarının değerleri sırasıyla 0.3667 ve 0.2333'tür. Ve aralarındaki örnek farkı sırasıyla 0.1333'e eşittir. %95'lik bir güven aralığını varsayarak, normal dağılım tablosundan z cr = 1,96 buluyoruz. Örnek farkının standart hatasının hesaplanması 0.0524'tür. Son olarak, %95 güven aralığının alt sınırının sırasıyla 0.0307 ve üst sınırının 0.2359 olduğunu elde ederiz. Elde edilen sonuçlar, indirim kuponu alan her 100 müşteri için 3 ila 23 yeni müşteri bekleyebileceğimiz şeklinde yorumlanabilir. Ancak, bu sonucun kendi başına kupon kullanmanın verimliliği anlamına gelmediği unutulmamalıdır (çünkü indirim yaparak kar kaybederiz!). Bunu belirli veriler üzerinde gösterelim. Ortalama satın alma tutarının 400 ruble olduğunu ve bunun 50 ruble olduğunu varsayalım. mağaza karı var. Kupon almayan 100 müşteri için beklenen kar şuna eşittir:
). Daha sonra numune oranlarının değerleri sırasıyla 0.3667 ve 0.2333'tür. Ve aralarındaki örnek farkı sırasıyla 0.1333'e eşittir. %95'lik bir güven aralığını varsayarak, normal dağılım tablosundan z cr = 1,96 buluyoruz. Örnek farkının standart hatasının hesaplanması 0.0524'tür. Son olarak, %95 güven aralığının alt sınırının sırasıyla 0.0307 ve üst sınırının 0.2359 olduğunu elde ederiz. Elde edilen sonuçlar, indirim kuponu alan her 100 müşteri için 3 ila 23 yeni müşteri bekleyebileceğimiz şeklinde yorumlanabilir. Ancak, bu sonucun kendi başına kupon kullanmanın verimliliği anlamına gelmediği unutulmamalıdır (çünkü indirim yaparak kar kaybederiz!). Bunu belirli veriler üzerinde gösterelim. Ortalama satın alma tutarının 400 ruble olduğunu ve bunun 50 ruble olduğunu varsayalım. mağaza karı var. Kupon almayan 100 müşteri için beklenen kar şuna eşittir:
50 0.2333 100 \u003d 1166.50 ruble.
Kupon alan 100 alıcı için benzer hesaplamalar şunları sağlar:
30 0.3667 100 \u003d 1100.10 ruble.
Ortalama kârın 30'a düşmesi, indirimi kullanarak kupon alan alıcıların ortalama olarak 380 ruble için satın alma yapacakları gerçeğiyle açıklanmaktadır.
Bu nedenle, nihai sonuç, bu özel durumda bu tür kuponları kullanmanın verimsizliğini göstermektedir.
Yorum. Bu sorun, standart StatPro araçları kullanılarak çözülebilir. Bunu yapmak için, bu sorunu iki ortalamanın farkını yöntemle tahmin etme sorununa indirgemek ve ardından uygulamak yeterlidir. StatPro/İstatistiksel Çıkarım/İki Örnek Analizi iki ortalama değer arasındaki fark için bir güven aralığı oluşturmak.
Güven aralığı kontrolü
Güven aralığının uzunluğu şunlara bağlıdır: aşağıdaki koşullar:
doğrudan veri (standart sapma);
önem düzeyi;
örnek boyut.
Ortalamayı tahmin etmek için örnek boyutu
Önce sorunu genel durumda ele alalım. Bize verilen güven aralığının yarısının değerini B olarak gösterelim (Şekil 104).  ). Bazı rasgele değişken X'in ortalama değeri için güven aralığının şu şekilde ifade edildiğini biliyoruz.
). Bazı rasgele değişken X'in ortalama değeri için güven aralığının şu şekilde ifade edildiğini biliyoruz. ![]() , nerede
, nerede ![]() . varsayarsak:
. varsayarsak:
![]() ve n ifade edersek elde ederiz.
ve n ifade edersek elde ederiz.
Ne yazık ki, X rastgele değişkeninin varyansının tam değerini bilmiyoruz. Ayrıca, serbestlik derecesi sayısı aracılığıyla n'ye bağlı olduğu için t cr'nin değerini bilmiyoruz. Bu durumda şunları yapabiliriz. Varyans s yerine, incelenen rastgele değişkenin bazı mevcut gerçekleşmeleri için varyansın bir tahminini kullanırız. Normal dağılım için t cr değeri yerine z cr değerini kullanıyoruz. Normal ve t dağılımları için yoğunluk fonksiyonları çok yakın olduğundan (küçük n durumu hariç) bu oldukça kabul edilebilir bir durumdur. Böylece, istenen formül şu şekli alır:
 .
.
Formül, genel olarak, tamsayı olmayan sonuçlar verdiğinden, sonucun fazlalığı ile yuvarlama, istenen örnek boyutu olarak alınır.
Misal
Fast food restoranı, ürün yelpazesini yeni bir sandviç türüyle genişletmeyi planlıyor. Buna olan talebi tahmin etmek için yönetici, daha önce denemiş olanlar arasından rastgele birkaç ziyaretçi seçmeyi ve onlardan yeni ürüne yönelik tutumlarını 1'den 10'a kadar bir ölçekte derecelendirmelerini istemeyi planlıyor. yeni ürünün alacağı beklenen puan sayısını tahmin etmek ve bu tahminin %95 güven aralığını çizmek. Ancak güven aralığının yarısının 0,3'ü geçmemesini istiyor. Anket için kaç ziyaretçiye ihtiyacı var?
aşağıdaki gibi:

Burada y otlar p fraksiyonunun bir tahminidir ve B, güven aralığının uzunluğunun verilen bir yarısıdır. Değer kullanılarak n için şişirilmiş bir değer elde edilebilir. y otlar= 0,5. Bu durumda, güven aralığının uzunluğu, p'nin herhangi bir gerçek değeri için verilen B değerini aşamaz.
Misal
Önceki örnekteki yöneticinin, yeni bir ürün türünü tercih eden müşterilerin oranını tahmin etmesine izin verin. Yarı uzunluğu 0,05'e eşit veya daha küçük olan %90'lık bir güven aralığı oluşturmak istiyor. Kaç müşteri rastgele örneklenmelidir?
Karar
Bizim durumumuzda z cr = 1.645 değeri. Bu nedenle, gerekli miktar şu şekilde hesaplanır:  .
.
Yöneticinin istenen p değerinin örneğin yaklaşık 0,3 olduğuna inanmak için nedeni varsa, o zaman bu değeri yukarıdaki formülde değiştirerek, rastgele örneğin daha küçük bir değerini, yani 228'i elde ederdik.
belirlemek için formül iki ortalama arasında fark olması durumunda rastgele örnek boyutlarışöyle yazılır:
 .
.
Misal
Bazı bilgisayar şirketlerinin bir müşteri hizmetleri merkezi vardır. Son zamanlarda, hizmet kalitesinin düşük olduğu konusunda müşteri şikayetlerinin sayısı arttı. Servis merkezinde esas olarak iki tür çalışan istihdam edilmektedir: az deneyime sahip olan ancak özel eğitim kurslarını tamamlamış olanlar ve kapsamlı uygulama deneyimine sahip ancak özel kursları tamamlamamış olanlar. Şirket, son altı aydaki müşteri şikayetlerini analiz etmek ve her iki çalışan grubu için ortalama sayılarını karşılaştırmak istiyor. Her iki grup için örneklerdeki sayıların aynı olacağı varsayılmıştır. Yarım uzunluğu 2'den fazla olmayan %95'lik bir aralık elde etmek için örneğe kaç çalışan dahil edilmelidir?
Karar
Burada σ ots, yakın oldukları varsayımı altında her iki rastgele değişkenin standart sapmasının bir tahminidir. Bu nedenle, görevimizde bu tahmini bir şekilde elde etmemiz gerekiyor. Bu, örneğin aşağıdaki gibi yapılabilir. Son altı aydaki müşteri şikayet verilerine bakıldığında, bir yönetici genellikle çalışan başına 6 ila 36 şikayet olduğunu fark edebilir. Normal bir dağılım için, pratikte tüm değerlerin ortalamadan üç standart sapmadan fazla olmadığını bilerek, makul bir şekilde şuna inanabilir:
![]() , nereden σ ots = 5.
, nereden σ ots = 5.
Bu değeri formülde yerine koyarsak,  .
.
belirlemek için formül paylar arasındaki farkın tahmin edilmesi durumunda rastgele bir örneğin büyüklüğüşuna benziyor:

Misal
Bazı şirketlerin benzer ürünlerin üretimi için iki fabrikası var. Bir şirketin yöneticisi her iki fabrikanın kusur oranlarını karşılaştırmak istiyor. Mevcut bilgilere göre, her iki fabrikada da reddedilme oranı %3 ila %5 arasındadır. Yarım uzunluğu 0,005'ten (veya %0,5) fazla olmayan %99 güven aralığı oluşturması beklenir. Her fabrikadan kaç ürün seçilmelidir?
Karar
Burada p 1ot ve p 2ot, 1. ve 2. fabrikalardaki ıskartaların bilinmeyen iki fraksiyonunun tahminleridir. p 1ots \u003d p 2ots \u003d 0,5 koyarsak, n için fazla tahmin edilen bir değer alırız. Ancak bizim durumumuzda bu paylar hakkında bazı ön bilgilerimiz olduğundan, bu payların üst tahminini yani 0,05'i alıyoruz. alırız
Örnek verilerden bazı popülasyon parametrelerini tahmin ederken, parametrenin yalnızca bir nokta tahminini değil, aynı zamanda tahmin edilen parametrenin tam değerinin nerede olabileceğini gösteren bir güven aralığını sağlamak da yararlıdır.
Bu bölümde, çeşitli parametreler için bu tür aralıkları oluşturmamıza izin veren nicel ilişkilerle de tanıştık; güven aralığının uzunluğunu kontrol etmenin öğrenilmiş yolları.
Ayrıca örneklem boyutunu tahmin etme probleminin (deney planlama problemi) standart StatPro araçları kullanılarak çözülebileceğini, yani StatPro/İstatistiksel Çıkarım/Örnek Boyutu Seçimi.
FREKANS VE PARÇALAR İÇİN GÜVEN ARALIKLARI
© 2008
Ulusal Halk Sağlığı Enstitüsü, Oslo, Norveç
Makale, Wald, Wilson, Klopper-Pearson yöntemleri, açısal dönüşüm ve Agresti-Cowll düzeltmeli Wald yöntemi kullanılarak frekanslar ve oranlar için güven aralıklarının hesaplanmasını açıklar ve tartışır. Sunulan materyal, frekanslar ve oranlar için güven aralıklarını hesaplama yöntemleri hakkında genel bilgiler sağlar ve dergi okuyucularının yalnızca kendi araştırmalarının sonuçlarını sunarken güven aralıklarını kullanmaya değil, aynı zamanda daha önce özel literatürü okumaya olan ilgisini uyandırmayı amaçlar. gelecekteki yayınlar üzerinde çalışmaya başlamak.
anahtar kelimeler: güven aralığı, sıklık, orantı
Önceki yayınlardan birinde, nitel verilerin tanımından kısaca bahsedildi ve genel popülasyonda çalışılan özelliğin ortaya çıkma sıklığını tanımlamak için nokta tahminine göre aralık tahminlerinin tercih edildiği bildirildi. Gerçekten de, çalışmalar örnek veriler kullanılarak yürütüldüğünden, sonuçların genel popülasyon üzerindeki projeksiyonu, örneklem tahmininde bir yanlışlık unsuru içermelidir. Güven aralığı, tahmin edilen parametrenin doğruluğunun bir ölçüsüdür. Hekimler için istatistiğin temelleri üzerine bazı kitaplarda, frekanslar için güven aralıkları konusunun tamamen göz ardı edilmesi ilginçtir. Bu makalede, tekrarlamama ve temsil edilebilirlik gibi örnek özelliklerini ve gözlemlerin birbirinden bağımsızlığını varsayarak, frekanslar için güven aralıklarını hesaplamanın birkaç yolunu ele alacağız. Bu makaledeki sıklık, şu veya bu değerin toplamda kaç kez meydana geldiğini gösteren mutlak bir sayı olarak değil, çalışılan özelliğe sahip çalışma katılımcılarının oranını belirleyen göreli bir değer olarak anlaşılmalıdır.
Biyomedikal araştırmalarda en yaygın olarak %95 güven aralığı kullanılır. Bu güven aralığı, gerçek oranın zamanın %95'inde düştüğü bölgedir. Başka bir deyişle, bir özelliğin genel popülasyonda görülme sıklığının gerçek değerinin %95 güven aralığında olacağı %95 kesinlikle söylenebilir.
Tıp araştırmacıları için çoğu istatistiksel ders kitabı, frekans hatasının formül kullanılarak hesaplandığını bildirmektedir.
burada p, numunedeki özelliğin ortaya çıkma sıklığıdır (0'dan 1'e kadar olan değer). Yerli bilimsel makalelerin çoğunda, örnekte (p) bir özelliğin ortaya çıkma sıklığının değeri ve hata (lar) p ± s şeklinde belirtilir. Bununla birlikte, genel popülasyonda bir özelliğin ortaya çıkma sıklığı için %95'lik bir güven aralığı sunmak daha uygundur;
 |
 önceki.
önceki.
Bazı ders kitaplarında, küçük örnekler için, N - 1 serbestlik derecesi için 1,96 değerinin t değeriyle değiştirilmesi önerilir; burada N, örnekteki gözlem sayısıdır. t değeri, hemen hemen tüm istatistik ders kitaplarında bulunan t-dağılımı tablolarında bulunur. Wald yöntemi için t dağılımının kullanılması, aşağıda tartışılan diğer yöntemlere göre görünür avantajlar sağlamaz ve bu nedenle bazı yazarlar tarafından hoş karşılanmaz.
Frekanslar veya kesirler için güven aralıklarını hesaplamak için yukarıdaki yöntem, 1939'da Wald ve Wolfowitz'in yayınlanmasından sonra yaygın olarak kullanılmaya başlandığı için Abraham Wald'ın (Abraham Wald, 1902–1950) adını almıştır. Bununla birlikte, yöntemin kendisi Pierre Simon Laplace (1749-1827) tarafından 1812 gibi erken bir tarihte önerildi.
Wald yöntemi çok popülerdir, ancak uygulanması önemli problemlerle ilişkilidir. Yöntem, küçük örneklem büyüklükleri için ve bir özelliğin ortaya çıkma sıklığının 0 veya 1 (%0 veya %100) olma eğiliminde olduğu ve 0 ve 1 frekansları için basitçe mümkün olmadığı durumlarda önerilmez. hata hesaplanırken kullanılan normal dağılım yaklaşımı n p olduğu durumlarda "çalışmaz"< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Yeni değişken normal olarak dağıldığından, φ değişkeni için %95 güven aralığının alt ve üst sınırları φ-1.96 ve φ+1.96sol">


Küçük numuneler için 1,96 yerine, N - 1 serbestlik derecesi yerine t değerinin kullanılması önerilir. Bu yöntem negatif değerler vermez ve frekanslar için güven aralıklarını Wald yöntemine göre daha doğru bir şekilde tahmin etmenizi sağlar. Ek olarak, tıbbi istatistiklerle ilgili birçok yerli referans kitabında açıklanmıştır, ancak bu, tıbbi araştırmalarda yaygın olarak kullanılmasına yol açmamıştır. 0 veya 1'e yaklaşan frekanslar için bir açı dönüşümü kullanarak güven aralıklarının hesaplanması önerilmez.
Tıp araştırmacıları için istatistiklerin temelleri üzerine çoğu kitapta güven aralıklarını tahmin etme yöntemlerinin açıklamasının genellikle burada sona erdiği yer burasıdır ve bu sorun sadece yerli değil, aynı zamanda yabancı literatür için de tipiktir. Her iki yöntem de büyük bir örneklem anlamına gelen merkezi limit teoremine dayanmaktadır.
Yukarıdaki yöntemleri kullanarak güven aralıklarını tahmin etmenin eksikliklerini dikkate alan Clopper (Clopper) ve Pearson (Pearson), 1934'te, incelenen özelliğin binom dağılımını hesaba katarak sözde kesin güven aralığını hesaplamak için bir yöntem önerdi. Bu yöntem birçok çevrimiçi hesap makinesinde mevcuttur, ancak bu şekilde elde edilen güven aralıkları çoğu durumda çok geniştir. Aynı zamanda, ihtiyatlı bir tahminin gerekli olduğu durumlarda bu yöntemin kullanılması önerilir. Yöntemin konservatiflik derecesi, özellikle N için örneklem boyutu azaldıkça artar.< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
Birçok istatistikçiye göre, frekanslar için en uygun güven aralıkları tahmini, 1927'de önerilen, ancak pratik olarak yerel biyomedikal araştırmalarda kullanılmayan Wilson yöntemiyle gerçekleştirilir. Bu yöntem yalnızca hem çok küçük hem de çok yüksek frekanslar için güven aralıklarının tahmin edilmesini mümkün kılmakla kalmaz, aynı zamanda az sayıda gözleme de uygulanabilir. Genel olarak, Wilson formülüne göre güven aralığı şu şekildedir:
 |
 |
%95 güven aralığını hesaplarken 1,96 değerini aldığı yerde N gözlem sayısı ve p örnekteki özelliğin frekansıdır. Bu yöntem çevrimiçi hesap makinelerinde mevcuttur, bu nedenle uygulaması sorunlu değildir. ve n p için bu yöntemin kullanılmasını önermeyin< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Wilson yöntemine ek olarak, Agresti-Caull düzeltmeli Wald yönteminin de frekanslar için güven aralığının optimal bir tahminini sağladığına inanılmaktadır. Agresti-Coulle düzeltmesi, paya hangi 2'nin eklendiğini ve paydaya 4'ün eklendiğini hesaplarken, örnekte (p) bir özelliğin ortaya çıkma sıklığının Wald formülünde p' ile değiştirilmesidir. , p` = (X + 2) / (N + 4), burada X, incelenen özelliğe sahip çalışma katılımcılarının sayısıdır ve N, örnek boyutudur. Bu modifikasyon, olay oranının %0 veya %100'e yaklaşması ve numunenin küçük olması dışında, Wilson formülüne çok benzer sonuçlar üretir. Frekanslar için güven aralıklarını hesaplamak için yukarıdaki yöntemlere ek olarak, küçük örnekler için hem Wald yöntemi hem de Wilson yöntemi için süreklilik düzeltmeleri önerilmiştir, ancak çalışmalar bunların kullanımının uygun olmadığını göstermiştir.
İki örnek kullanarak güven aralıklarını hesaplamak için yukarıdaki yöntemlerin uygulamasını düşünün. İlk durumda, 450'si incelenen özelliğe (risk faktörü, sonuç veya başka bir özellik olsun) sahip olan ve 0,45 sıklık veya %45. İkinci durumda, çalışma küçük bir örneklem kullanılarak yürütülür, diyelim ki sadece 20 kişi ve çalışmadaki sadece 1 katılımcı (%5) incelenen özelliğe sahiptir. Wald yöntemi için, Agresti-Coll düzeltmeli Wald yöntemi için, Wilson yöntemi için güven aralıkları Jeff Sauro (http://www./wald.htm) tarafından geliştirilen bir çevrimiçi hesap makinesi kullanılarak hesaplandı. Süreklilik düzeltmeli Wilson güven aralıkları, Wassar İstatistikleri: İstatistiksel Hesaplama için Web Sitesi (http://faculty.vassar.edu/lowry/prop1.html) tarafından sağlanan hesaplayıcı kullanılarak hesaplandı. Fisher açısal dönüşümünü kullanan hesaplamalar, sırasıyla 19 ve 999 serbestlik derecesi için kritik t değeri kullanılarak "manuel" olarak yapıldı. Hesaplama sonuçları her iki örnek için de tabloda sunulmuştur.
Metinde anlatılan iki örnek için altı farklı şekilde hesaplanan güven aralıkları
Güven Aralığı Hesaplama Yöntemi |
P=0.0500 veya %5 | X=450, N=1000, P=0.4500 veya %45 için %95 GA |
–0,0455–0,2541 | ||
Agresti-Coll düzeltmeli Walda | <,0001–0,2541 | |
Süreklilik düzeltmeli Wilson | ||
Klopper-Pearson'ın "kesin yöntemi" | ||
açısal dönüşüm | <0,0001–0,1967 |
Tablodan da anlaşılacağı üzere birinci örnek için "genel kabul görmüş" Wald yöntemi ile hesaplanan güven aralığı frekanslar için geçerli olmayan negatif bölgeye gitmektedir. Ne yazık ki, bu tür olaylar Rus edebiyatında nadir değildir. Verileri bir frekans olarak göstermenin geleneksel yolu ve hatası bu sorunu kısmen maskeler. Örneğin, bir özelliğin ortaya çıkma sıklığı (yüzde olarak) 2,1 ± 1,4 olarak sunuluyorsa, bu durum aynı anlama gelse de %2,1 (%95 GA: –0,7; 4,9) kadar “rahatsız edici” değildir. Agresti-Coulle düzeltmeli Wald yöntemi ve açısal dönüşüm kullanılarak hesaplama, sıfıra eğilimli bir alt sınır verir. Süreklilik düzeltmeli Wilson yöntemi ve "kesin yöntem", Wilson yönteminden daha geniş güven aralıkları verir. İkinci örnek için, tüm yöntemler yaklaşık olarak aynı güven aralıklarını verir (farklar yalnızca binde bir görünür), bu şaşırtıcı değildir, çünkü bu örnekteki olayın sıklığı %50'den çok farklı değildir ve örneklem boyutu oldukça büyüktür. .
Bu problemle ilgilenen okuyucular için, güven aralığını hesaplamak için sırasıyla 7 ve 10 farklı yöntem kullanmanın artılarını ve eksilerini veren R. G. Newcombe ve Brown, Cai ve Dasgupta'nın çalışmalarını önerebiliriz. Yerli kılavuzlardan, teorinin ayrıntılı bir açıklamasına ek olarak, Wald ve Wilson yöntemlerinin yanı sıra binom frekans dağılımını dikkate alarak güven aralıklarını hesaplamak için bir yöntemin sunulduğu kitap ve tavsiye edilir. Ücretsiz çevrimiçi hesaplayıcılara (http://www./wald.htm ve http://faculty.vassar.edu/lowry/prop1.html) ek olarak, frekanslar için güven aralıkları (sadece değil!) http://www.CIA programı (Güven Aralıkları Analizi) adresinden indirilebilir. tıp fakültesi. soton. AC. İngiltere/cia/ .
Sonraki makale, nitel verileri karşılaştırmanın tek değişkenli yollarına bakacaktır.
bibliyografya
Banerjee A. Sade bir dilde tıbbi istatistikler: bir giriş kursu / A. Banerzhi. - M. : Pratik tıp, 2007. - 287 s. Tıbbi istatistikler / . - M. : Tıbbi Bilgi Ajansı, 2007. - 475 s. Glanz S. Mediko-biyolojik istatistikler / S. Glants. - M. : Uygulama, 1998. Veri türleri, dağıtım doğrulaması ve tanımlayıcı istatistikler // İnsan Ekolojisi - 2008. - No. 1. - S. 52–58. Zhizhin K.S.. Tıbbi istatistikler: ders kitabı / . - Rostov n / D: Phoenix, 2007. - 160 s. Uygulamalı Tıbbi İstatistikler / , . - St.Petersburg. : Folyo, 2003. - 428 s. lakin GF. Biyometri / . - M. : Yüksekokul, 1990. - 350 s. doktor V.A. Tıpta matematiksel istatistik / , . - M. : Finans ve istatistik, 2007. - 798 s. Klinik araştırmalarda matematiksel istatistikler / , . - E. : GEOTAR-MED, 2001. - 256 s. Junkerov V. Ve. Tıbbi araştırma verilerinin mediko-istatistiksel işlenmesi /,. - St.Petersburg. : VmedA, 2002. - 266 s. Agresti A. Yaklaşık, binom oranlarının aralık tahmini için kesinden daha iyidir / A. Agresti, B. Coull // Amerikan istatistikçi. - 1998. - N 52. - S. 119-126. Altman D. Güvenilir istatistikler // D. Altman, D. Machin, T. Bryant, M. J. Gardner. - Londra: BMJ Kitapları, 2000. - 240 s. kahverengi L.D. Binom oranı için aralık tahmini / L. D. Brown, T. T. Cai, A. Dasgupta // İstatistik bilimi. - 2001. - N 2. - S. 101-133. Clopper C.J. Binom / C. J. Clopper, E. S. Pearson // Biometrika durumunda gösterilen güven veya referans sınırlarının kullanımı. - 1934. - N 26. - S. 404-413. Garcia-Perez M.A. Binom parametresi / M. A. Garcia-Perez // Nitelik ve nicelik için güven aralığında. - 2005. - N 39. - S. 467-481. Motulsky H. Sezgisel biyoistatistik // H. Motulsky. - Oxford: Oxford University Press, 1995. - 386 s. Newcombe R.G. Tek Oran için İki Taraflı Güven Aralıkları: Yedi Yöntemin Karşılaştırılması / R. G. Newcombe // Tıpta İstatistik. - 1998. - N. 17. - S. 857-872. Sauro J.İki terimli güven aralıklarını kullanarak küçük örneklerden tamamlama oranlarının tahmin edilmesi: karşılaştırmalar ve öneriler / J. Sauro, J. R. Lewis // İnsan faktörleri ve ergonomi topluluğu yıllık toplantısının bildirileri. - Orlando, Florida, 2005. Wald A. Sürekli dağılım fonksiyonları için güven sınırları // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. - 1939. - N 10. - S. 105–118. Wilson E.B.. Olası çıkarım, ardışıklık yasası ve istatistiksel çıkarım / E. B. Wilson // Amerikan İstatistik Derneği Dergisi. - 1927. - N 22. - S. 209-212.ORANLAR İÇİN GÜVEN ARALIKLARI
A. M. Grjibovski
Ulusal Halk Sağlığı Enstitüsü, Oslo, Norveç
Makale, Wald, Wilson, arksinüs, Agresti-Coull ve kesin Clopper-Pearson yöntemleri gibi binom oranları için güven aralıklarını hesaplamak için çeşitli yöntemler sunmaktadır. Bu makale, iki terimli bir oranın güven aralığı tahmini sorununa yalnızca genel bir giriş sağlar ve amacı, okuyucuları yalnızca kendi deneysel araştırmalarının sonuçlarını sunarken güven aralıklarını kullanmaya teşvik etmek değil, aynı zamanda onları daha önce istatistik kitaplarına başvurmaya teşvik etmektir. kendi verilerini analiz etme ve el yazmaları hazırlama.
anahtar kelimeler: güven aralığı, orantı
İletişim bilgileri:
– Kıdemli Danışman, Ulusal Halk Sağlığı Enstitüsü, Oslo, Norveç
Herhangi bir örnek, genel popülasyon hakkında yalnızca yaklaşık bir fikir verir ve tüm örnek istatistiksel özellikleri (ortalama, mod, varyans ...) bazı yaklaşımlardır veya çoğu durumda hesaplanamayan genel parametrelerin bir tahminidir. genel nüfusun erişilemezliği (Şekil 20) .
Şekil 20. Örnekleme hatası
Ancak, belirli bir olasılık derecesi ile istatistiksel özelliğin gerçek (genel) değerinin bulunduğu aralığı belirtebilirsiniz. Bu aralığa denir d güven aralığı (CI).
Yani %95 olasılıkla genel ortalama
itibaren, (20)
nerede t - Öğrenci kriterinin tablo değeri α =0.05 ve f= n-1
Bu durumda bulunabilir ve %99 CI t için seçildi α =0,01.
Bir güven aralığının pratik önemi nedir?
Geniş bir güven aralığı, örneklem ortalamasının popülasyon ortalamasını doğru bir şekilde yansıtmadığını gösterir. Bu genellikle yetersiz örneklem büyüklüğünden veya heterojenliğinden, yani büyük dağılım. Her ikisi de ortalamada büyük bir hata ve buna bağlı olarak daha geniş bir CI verir. Ve bu, araştırma planlama aşamasına geri dönme sebebidir.
Üst ve alt CI limitleri, sonuçların klinik olarak anlamlı olup olmayacağını değerlendirir
Grup özellikleri çalışmasının sonuçlarının istatistiksel ve klinik önemi sorusu üzerinde daha ayrıntılı olarak duralım. İstatistiğin görevinin, örnek verilere dayanarak genel popülasyonlardaki en azından bazı farklılıkları tespit etmek olduğunu hatırlayın. Tanı veya tedaviye yardımcı olacak bu tür (herhangi bir değil) farklılıkları bulmak klinisyenin görevidir. Ve her zaman istatistiksel sonuçlar klinik sonuçların temeli değildir. Bu nedenle, hemoglobinde 3 g/l'lik istatistiksel olarak anlamlı bir azalma endişe nedeni değildir. Ve tersine, insan vücudundaki bir sorun tüm nüfus düzeyinde kitlesel bir karaktere sahip değilse, bu, bu sorunla uğraşmamak için bir neden değildir.
|
Bu pozisyonu değerlendireceğiz misal. Araştırmacılar, bir tür bulaşıcı hastalığı olan erkek çocukların büyüme açısından yaşıtlarının gerisinde kalıp kalmadığını merak ettiler. Bu amaçla bu hastalığa sahip 10 erkek çocuğun yer aldığı seçici bir çalışma yapılmıştır. Sonuçlar tablo 23'te sunulmuştur. Tablo 23. İstatistiksel sonuçlar
Bu hesaplamalardan, bir tür bulaşıcı hastalığı olan 10 yaşındaki erkek çocukların seçici ortalama boylarının normale yakın (132,5 cm) olduğu anlaşılmaktadır. Bununla birlikte, güven aralığının alt sınırı (126.6 cm), bu çocukların gerçek ortalama boyunun "kısa boy" kavramına, yani. bu çocuklar bodur. Bu örnekte, güven aralığı hesaplamalarının sonuçları klinik olarak önemlidir. |
|||||||||||||||||||
Hedef– öğrencilere istatistiksel parametrelerin güven aralıklarını hesaplamak için algoritmaları öğretmek.
Verilerin istatistiksel olarak işlenmesi sırasında, hesaplanan aritmetik ortalama, varyasyon katsayısı, korelasyon katsayısı, fark kriterleri ve diğer nokta istatistikleri, güven aralığı içinde göstergenin yukarı ve aşağı olası dalgalanmalarını gösteren nicel güven sınırları almalıdır.
Örnek 3.1
.
Maymunların kan serumundaki kalsiyum dağılımı, daha önce belirlendiği gibi, aşağıdaki seçici göstergelerle karakterize edilir: = %11,94 mg;  = 0.127 mg %; n= 100. Genel ortalama için güven aralığının belirlenmesi gerekmektedir (
= 0.127 mg %; n= 100. Genel ortalama için güven aralığının belirlenmesi gerekmektedir (  ) güven olasılığı ile P
= 0,95.
) güven olasılığı ile P
= 0,95.
Genel ortalama, aralıkta belirli bir olasılıkla:
 , nerede
, nerede  – örnek aritmetik ortalama; t- Öğrencinin kriteri;
– örnek aritmetik ortalama; t- Öğrencinin kriteri;  aritmetik ortalamanın hatasıdır.
aritmetik ortalamanın hatasıdır.
"Öğrencinin Değerleri Ölçütü" tablosuna göre değeri buluyoruz
 0.95 güven seviyesi ve serbestlik derecesi sayısı ile k\u003d 100-1 \u003d 99. 1.982'ye eşittir. Aritmetik ortalama ve istatistiksel hatanın değerleriyle birlikte, bunu formülde değiştiririz:
0.95 güven seviyesi ve serbestlik derecesi sayısı ile k\u003d 100-1 \u003d 99. 1.982'ye eşittir. Aritmetik ortalama ve istatistiksel hatanın değerleriyle birlikte, bunu formülde değiştiririz:
veya 11.69  12,19
12,19
Böylece %95 olasılıkla bu normal dağılımın genel ortalamasının %11.69 ile %12.19 mg arasında olduğu söylenebilir.
Örnek 3.2
. Genel varyans için %95 güven aralığının sınırlarını belirleyin (  ) olduğu biliniyorsa, maymunların kanındaki kalsiyum dağılımı
) olduğu biliniyorsa, maymunların kanındaki kalsiyum dağılımı  = 1.60 ile n
= 100.
= 1.60 ile n
= 100.
Sorunu çözmek için aşağıdaki formülü kullanabilirsiniz:
Neresi  varyansın istatistiksel hatasıdır.
varyansın istatistiksel hatasıdır.
Aşağıdaki formülü kullanarak örnek varyans hatasını bulun:  . 0.11'e eşittir. Anlam t- 0,95 güven olasılığı ve serbestlik derecesi sayısı olan kriter k= 100–1 = 99 önceki örnekten bilinmektedir.
. 0.11'e eşittir. Anlam t- 0,95 güven olasılığı ve serbestlik derecesi sayısı olan kriter k= 100–1 = 99 önceki örnekten bilinmektedir.
Formülü kullanalım ve şunu elde edelim:
veya 1.38  1,82
1,82
Genel varyans için daha doğru bir güven aralığı kullanılarak oluşturulabilir.  (ki-kare) - Pearson testi. Bu kriter için kritik noktalar özel bir tabloda verilmiştir. Kriter kullanıldığında
(ki-kare) - Pearson testi. Bu kriter için kritik noktalar özel bir tabloda verilmiştir. Kriter kullanıldığında  bir güven aralığı oluşturmak için iki taraflı bir anlamlılık düzeyi kullanılır. Alt sınır için anlamlılık düzeyi şu formülle hesaplanır:
bir güven aralığı oluşturmak için iki taraflı bir anlamlılık düzeyi kullanılır. Alt sınır için anlamlılık düzeyi şu formülle hesaplanır:  , üst kısım için
, üst kısım için  . Örneğin, bir güven düzeyi için
. Örneğin, bir güven düzeyi için  =
0,99
=
0,99 = 0,010,
= 0,010, = 0.990. Buna göre kritik değerlerin dağılım tablosuna göre
= 0.990. Buna göre kritik değerlerin dağılım tablosuna göre  , hesaplanan güven seviyeleri ve serbestlik derecesi sayısı ile k= 100 – 1= 99, değerleri bulun
, hesaplanan güven seviyeleri ve serbestlik derecesi sayısı ile k= 100 – 1= 99, değerleri bulun  ve
ve  . alırız
. alırız  135.80'e eşittir ve
135.80'e eşittir ve  70.06'ya eşittir.
70.06'ya eşittir.
Genel varyansın güven sınırlarını bulmak için  formülleri kullanıyoruz: alt sınır için
formülleri kullanıyoruz: alt sınır için  , üst sınır için
, üst sınır için  . Bulunan değerler için görev verilerini değiştirin
. Bulunan değerler için görev verilerini değiştirin  formüller halinde:
formüller halinde:  =
1,17;
=
1,17; = 2.26. Böylece güven düzeyi ile P= 0.99 veya %99 genel varyans, % 1.17 ila % 2.26 mg aralığında olacaktır.
= 2.26. Böylece güven düzeyi ile P= 0.99 veya %99 genel varyans, % 1.17 ila % 2.26 mg aralığında olacaktır.
Örnek 3.3 . Elevatöre gelen partiden 1000 adet buğday tohumu arasında ergot bulaşmış 120 adet tohum bulundu. Belirli bir buğday partisindeki hastalıklı tohumların toplam oranının olası sınırlarını belirlemek gereklidir.
Tüm olası değerleri için genel pay için güven sınırları aşağıdaki formüle göre belirlenmelidir:
 ,
,
Neresi n gözlem sayısıdır; m gruplardan birinin mutlak sayısıdır; t normalleştirilmiş sapmadır.
Enfekte tohumların örnek fraksiyonu şuna eşittir:  veya %12. Bir güven seviyesi ile R= %95 normalleştirilmiş sapma ( t-Öğrencinin kriteri k
=
veya %12. Bir güven seviyesi ile R= %95 normalleştirilmiş sapma ( t-Öğrencinin kriteri k
=
 )t
= 1,960.
)t
= 1,960.
Mevcut verileri formülle değiştiriyoruz:
Bu nedenle, güven aralığının sınırları  = 0.122–0.041 = 0.081 veya %8,1;
= 0.122–0.041 = 0.081 veya %8,1;  = 0.122 + 0.041 = 0.163 veya %16.3.
= 0.122 + 0.041 = 0.163 veya %16.3.
Böylece, %95'lik bir güven düzeyi ile, enfekteli tohumların toplam oranının %8,1 ile %16,3 arasında olduğu ifade edilebilir.
Örnek 3.4 . Maymunların kan serumundaki kalsiyum varyasyonunu (%mg) karakterize eden varyasyon katsayısı %10,6'ya eşittir. Örnek boyut n= 100. Genel parametre için %95 güven aralığı sınırlarının belirlenmesi gereklidir. Özgeçmiş.
Genel varyasyon katsayısı için güven sınırları Özgeçmiş aşağıdaki formüllerle belirlenir:
 ve
ve  , nerede K
formülle hesaplanan ara değer
, nerede K
formülle hesaplanan ara değer  .
.
Bunu bir güven seviyesiyle bilmek R= %95 normalleştirilmiş sapma (Student's t-test for k
=
 )t
= 1.960, değeri önceden hesapla İLE:
)t
= 1.960, değeri önceden hesapla İLE:
 .
.
 veya %9,3
veya %9,3
 veya %12,3
veya %12,3
Bu nedenle, %95'lik bir güven olasılığı ile genel varyasyon katsayısı, %9,3 ila %12,3 aralığındadır. Tekrarlanan numunelerde, 100 üzerinden 95 vakada varyasyon katsayısı %12,3'ü geçmeyecek ve %9,3'ün altına düşmeyecektir.
Otokontrol için sorular:

Bağımsız çözüm için görevler.
1. Kholmogory melezlerinin ineklerinin laktasyonu için sütteki ortalama yağ yüzdesi aşağıdaki gibidir: 3.4; 3.6; 3.2; 3.1; 2.9; 3.7; 3.2; 3.6; 4.0; 3.4; 4.1; 3.8; 3.4; 4.0; 3.3; 3.7; 3.5; 3.6; 3.4; 3.8. Genel ortalama için güven aralıklarını %95 güven düzeyinde (20 puan) ayarlayın.
2. 400 melez çavdar bitkisinde, ilk çiçekler ekimden ortalama 70.5 gün sonra ortaya çıktı. Standart sapma 6.9 gündü. Önemlilik düzeyinde popülasyon ortalaması ve varyansı için ortalama ve güven aralıklarının hatasını belirleyin W= 0.05 ve W= 0,01 (25 puan).
3. 502 bahçe çileği örneğinin yapraklarının uzunluğunu incelerken, aşağıdaki veriler elde edildi:
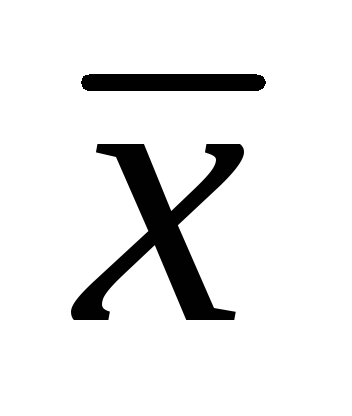 = 7,86 cm; σ = 1.32 cm,
= 7,86 cm; σ = 1.32 cm,  \u003d ± 0.06 cm Popülasyonun aritmetik ortalaması için güven aralıklarını 0,01 anlamlılık düzeyiyle belirleyin; 0.02; 0.05. (25 puan).
\u003d ± 0.06 cm Popülasyonun aritmetik ortalaması için güven aralıklarını 0,01 anlamlılık düzeyiyle belirleyin; 0.02; 0.05. (25 puan).
4. 150 yetişkin erkek incelendiğinde ortalama boy 167 cm idi ve σ \u003d 6 cm 0.99 ve 0.95 güven olasılığı ile genel ortalama ve genel varyansın sınırları nelerdir? (25 puan).
5. Maymunların kan serumundaki kalsiyum dağılımı, aşağıdaki seçici göstergelerle karakterize edilir:
 = %11,94 mg, σ
= 1,27, n
= 100. Bu dağılımın popülasyon ortalaması için %95'lik bir güven aralığı çizin. Varyasyon katsayısını hesaplayın (25 puan).
= %11,94 mg, σ
= 1,27, n
= 100. Bu dağılımın popülasyon ortalaması için %95'lik bir güven aralığı çizin. Varyasyon katsayısını hesaplayın (25 puan).
6. 37 ve 180 günlük albino sıçanların kan plazmasındaki toplam nitrojen içeriği incelenmiştir. Sonuçlar, 100 cm3 plazma başına gram olarak ifade edilir. 37 günlükken, 9 sıçan: 0.98; 0.83; 0.99; 0.86; 0.90; 0.81; 0.94; 0.92; 0.87. 180 günlükken, 8 sıçan: 1.20; 1.18; 1.33; 1.21; 1.20; 1.07; 1.13; 1.12. 0,95 (50 puan) güven düzeyi ile fark için güven aralıkları belirleyin.
7. Maymunların kan serumundaki kalsiyum dağılımının (%mg) genel varyansı için %95 güven aralığının sınırlarını belirleyin, bu dağılım için numune boyutu n = 100 ise, numune varyansının istatistiksel hatası s σ 2 = 1.60 (40 puan).
8. Boy boyunca 40 başakçıklı buğdayın dağılımının genel varyansı için %95 güven aralığının sınırlarını belirleyin (σ 2 = 40.87 mm 2). (25 puan).
9. Sigara, obstrüktif akciğer hastalığına zemin hazırlayan ana faktör olarak kabul edilir. Pasif içicilik böyle bir faktör olarak kabul edilmez. Bilim adamları, pasif içiciliğin güvenliğini sorguladı ve sigara içmeyenlerde, pasif ve aktif içicilerde hava yolunu inceledi. Solunum yolunun durumunu karakterize etmek için, ekshalasyonun ortasındaki maksimum hacimsel hız olan dış solunum fonksiyonunun göstergelerinden birini aldık. Bu göstergede bir azalma, bozulmuş hava yolu açıklığının bir işaretidir. Anket verileri tabloda gösterilmektedir.
|
İncelenen sayısı |
Maksimum ekspirasyon ortası akış hızı, l/s |
||
|
Standart sapma |
|||
|
sigara içmeyenler |
|||
|
sigara içilmeyen bir alanda çalışmak | |||
|
dumanlı bir odada çalışmak | |||
|
sigara içenler |
|||
|
az sayıda sigara içmek | |||
|
ortalama sigara tiryakisi sayısı | |||
|
çok sayıda sigara içmek | |||
Tablodan, grupların her biri için genel ortalama ve genel varyans için %95 güven aralıklarını bulun. Gruplar arasındaki farklar nelerdir? Sonuçları grafik olarak sunun (25 puan).
10. Örnek varyansının istatistiksel hatası varsa, 64 yavrulamadaki domuz yavrularının sayısının genel varyansı için %95 ve %99 güven aralıklarının sınırlarını belirleyin. s σ 2 = 8,25 (30 puan).
11. Tavşanların ortalama ağırlığının 2,1 kg olduğu bilinmektedir. Aşağıdaki durumlarda genel ortalama ve varyans için %95 ve %99 güven aralıklarının sınırlarını belirleyin. n= 30, σ = 0,56 kg (25 puan).
12. 100 başakta, başakta tane içeriği ölçüldü ( X), başak uzunluğu ( Y) ve başakta tane kütlesi ( Z). Genel ortalama ve varyans için güven aralıklarını bulun P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 ise
 = 19, = 6.766 cm, = 0.554 gr; σ x 2 = 29.153, σ y 2 = 2.111, σ z 2 = 0.064. (25 puan).
= 19, = 6.766 cm, = 0.554 gr; σ x 2 = 29.153, σ y 2 = 2.111, σ z 2 = 0.064. (25 puan).
13. Rastgele seçilen 100 başak kış buğdayında başakçık sayısı sayılmıştır. Örnek set, aşağıdaki göstergelerle karakterize edildi:
 = 15 spikelet ve σ = 2.28 adet. Ortalama sonucun elde edildiği doğruluğu belirleyin (
= 15 spikelet ve σ = 2.28 adet. Ortalama sonucun elde edildiği doğruluğu belirleyin (  ) ve %95 ve %99 anlamlılık seviyelerinde (30 puan) genel ortalama ve varyans için güven aralığını çizin.
) ve %95 ve %99 anlamlılık seviyelerinde (30 puan) genel ortalama ve varyans için güven aralığını çizin.
14. Bir yumuşakça fosilinin kabuğundaki kaburga sayısı ortambonit hat yazısı:
olduğu biliniyor n = 19, σ = 4.25. Genel ortalama ve genel varyans için güven aralığının sınırlarını anlamlılık düzeyinde belirleyin W = 0,01 (25 puan).
15. Ticari bir süt çiftliğinde süt verimini belirlemek için günlük 15 ineğin verimliliği belirlendi. Yıl verilerine göre, her inek günde ortalama olarak aşağıdaki süt miktarını vermiştir (l): 22; on dokuz; 25; 20; 27; 17; otuz; 21; on sekiz; 24; 26; 23; 25; 20; 24. Genel varyans ve aritmetik ortalama için güven aralıklarını çizin. İnek başına ortalama yıllık süt veriminin 10.000 litre olmasını bekleyebilir miyiz? (50 puan).
16. Çiftlik için ortalama buğday verimini belirlemek için 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 ve 2 hektarlık örnek parsellerde biçme yapılmıştır. Parsellerden elde edilen verim (c/ha) 39.4; 38; 35.8; 40; 35; 42.7; 39.3; 41.6; 33; 42; 29 sırasıyla. Genel varyans ve aritmetik ortalama için güven aralıklarını çizin. Tarım işletmesi için ortalama verimin 42 c/ha olmasını beklemek mümkün müdür? (50 puan).