Intervaly spoľahlivosti. Interval spoľahlivosti
A ďalšie.Všetky sú to odhady ich teoretických náprotivkov, ktoré by sa dali získať, keby neexistovala vzorka, ale všeobecná populácia. Ale bohužiaľ, bežná populácia je veľmi drahá a často nedostupná.
Pojem intervalového odhadu
Akýkoľvek odhad vzorky má určitý rozptyl, pretože je náhodná premenná v závislosti od hodnôt v konkrétnej vzorke. Preto pre spoľahlivejšie štatistické závery treba poznať nielen bodový odhad, ale aj interval, ktorý s vysokou pravdepodobnosťou γ (gama) pokrýva odhadovaný ukazovateľ θ (theta).
Formálne sú to dve takéto hodnoty (štatistika) T1(X) a T2(X), čo T1< T 2 , pre ktoré pri danej úrovni pravdepodobnosti γ podmienka je splnená:
Je to skrátka pravdepodobné γ alebo viac, skutočná hodnota je medzi bodmi T1(X) a T2(X), ktoré sa nazývajú dolná a horná hranica interval spoľahlivosti.
Jednou z podmienok konštrukcie intervalov spoľahlivosti je jeho maximálna úzka, t.j. mala by byť čo najkratšia. Túžba je celkom prirodzená, pretože. výskumník sa snaží presnejšie lokalizovať zistenie požadovaného parametra.
Z toho vyplýva, že interval spoľahlivosti by mal pokrývať maximálne pravdepodobnosti rozdelenia. a samotné hodnotenie bude v centre.
![]()
To znamená, že pravdepodobnosť odchýlky (skutočného ukazovateľa od odhadu) smerom nahor sa rovná pravdepodobnosti odchýlky smerom nadol. Treba tiež poznamenať, že pre zošikmené distribúcie sa interval vpravo nerovná intervalu vľavo.
Vyššie uvedený obrázok jasne ukazuje, že čím vyššia je úroveň spoľahlivosti, tým širší je interval - priamy vzťah.
Toto bol malý úvod do teórie intervalového odhadu neznámych parametrov. Prejdime k hľadaniu hraníc spoľahlivosti pre matematické očakávania.
Interval spoľahlivosti pre matematické očakávania
Ak sú pôvodné údaje rozdelené na , priemer bude normálna hodnota. Vyplýva to z pravidla, že lineárna kombinácia normálnych hodnôt má tiež normálne rozdelenie. Preto by sme na výpočet pravdepodobností mohli použiť matematický aparát zákona normálneho rozdelenia.
To si však bude vyžadovať znalosť dvoch parametrov – očakávanej hodnoty a rozptylu, ktoré väčšinou nie sú známe. Namiesto parametrov môžete samozrejme použiť odhady (aritmetický priemer a ), ale potom rozdelenie priemeru nebude celkom normálne, bude mierne sploštené. Írsky občan William Gosset si túto skutočnosť šikovne všimol, keď svoj objav zverejnil v marci 1908 v časopise Biometrica. Z dôvodu utajenia podpísal Gosset so Študentom. Takto sa objavilo Študentovo t-rozdelenie.
Normálna distribúcia údajov, ktorú používa K. Gauss pri analýze chýb v astronomických pozorovaniach, je však v pozemskom živote extrémne vzácna a je dosť ťažké ju určiť (na vysokú presnosť je potrebných asi 2 000 pozorovaní). Preto je najlepšie upustiť od predpokladu normality a použiť metódy, ktoré nezávisia od distribúcie pôvodných údajov.
Vzniká otázka: aké je rozdelenie aritmetického priemeru, ak sa vypočítava z údajov neznámeho rozdelenia? Odpoveď dáva dobre známy z teórie pravdepodobnosti Centrálna limitná veta(CPT). V matematike existuje niekoľko jeho verzií (formulácie sa v priebehu rokov zdokonaľovali), ale všetky, zhruba povedané, vedú k konštatovaniu, že súčet veľkého počtu nezávislých náhodných premenných sa riadi zákonom normálneho rozdelenia.
Pri výpočte aritmetického priemeru sa používa súčet náhodných premenných. Z toho vyplýva, že aritmetický priemer má normálne rozdelenie, v ktorom očakávaná hodnota je očakávaná hodnota počiatočných údajov a rozptyl je .
Chytrí ľudia vedia dokázať CLT, ale overíme si to pomocou experimentu v Exceli. Simulujme vzorku 50 rovnomerne rozdelených náhodných premenných (pomocou excelovej funkcie RANDOMBETWEEN). Potom urobíme 1000 takýchto vzoriek a pre každú vypočítame aritmetický priemer. Pozrime sa na ich distribúciu.

Je vidieť, že rozdelenie priemeru sa blíži normálnemu zákonu. Ak sa objem vzoriek a ich počet ešte zväčšia, podobnosť bude ešte lepšia.
Teraz, keď sme na vlastné oči videli platnosť CLT, môžeme pomocou , vypočítať intervaly spoľahlivosti pre aritmetický priemer, ktoré pokrývajú skutočný priemer alebo matematické očakávania s danou pravdepodobnosťou.
Na stanovenie hornej a dolnej hranice je potrebné poznať parametre normálneho rozdelenia. Spravidla nie sú, preto sa používajú odhady: aritmetický priemer a vzorový rozptyl. Táto metóda opäť poskytuje dobrú aproximáciu iba pre veľké vzorky. Keď sú vzorky malé, často sa odporúča použiť Studentovu distribúciu. Neverte! Študentovo rozdelenie pre priemer sa vyskytuje iba vtedy, keď pôvodné údaje majú normálne rozdelenie, teda takmer nikdy. Preto je lepšie okamžite nastaviť minimálnu latku pre množstvo požadovaných údajov a použiť asymptoticky správne metódy. Hovorí sa, že stačí 30 pozorovaní. Vezmite 50 - nemôžete sa pokaziť.
![]()
T 1.2 sú dolné a horné hranice intervalu spoľahlivosti
– vzorový aritmetický priemer
s0– vzorová štandardná odchýlka (nezaujatá)
n - veľkosť vzorky
γ – úroveň spoľahlivosti (zvyčajne sa rovná 0,9, 0,95 alebo 0,99)
c γ =Φ -1 ((1+γ)/2) je prevrátená hodnota funkcie štandardného normálneho rozdelenia. Jednoducho povedané, ide o počet štandardných chýb od aritmetického priemeru po dolnú alebo hornú hranicu (uvedené tri pravdepodobnosti zodpovedajú hodnotám 1,64, 1,96 a 2,58).
Podstatou vzorca je, že sa vezme aritmetický priemer a potom sa z neho vyčlení určitá čiastka ( s γ) štandardné chyby ( s 0 /√n). Všetko je známe, vezmite a počítajte.
Pred masovým používaním PC na získanie hodnôt funkcie normálneho rozdelenia a jeho inverznej hodnoty používali . Stále sa používajú, ale efektívnejšie je obrátiť sa na hotové vzorce Excelu. Všetky prvky z vyššie uvedeného vzorca ( , a ) možno jednoducho vypočítať v Exceli. Existuje však aj hotový vzorec na výpočet intervalu spoľahlivosti - NORMÁLNA DÔVERA. Jeho syntax je nasledovná.
CONFIDENCE NORM(alfa; štandardný_vývoj; veľkosť)
alfa– hladina významnosti alebo hladina spoľahlivosti, ktorá sa vo vyššie uvedenom zápise rovná 1-γ, t.j. pravdepodobnosť, že matematickéočakávanie bude mimo intervalu spoľahlivosti. S úrovňou spoľahlivosti 0,95 je alfa 0,05 atď.
štandard_vyp je štandardná odchýlka údajov vzorky. Nemusíte počítať štandardnú chybu, Excel bude deliť odmocninou z n.
veľkosť– veľkosť vzorky (n).
Výsledkom funkcie CONFIDENCE.NORM je druhý člen zo vzorca na výpočet intervalu spoľahlivosti, t.j. polovičný interval. V súlade s tým sú dolné a horné body priemer ± získaná hodnota.
Je teda možné vytvoriť univerzálny algoritmus na výpočet intervalov spoľahlivosti pre aritmetický priemer, ktorý nezávisí od distribúcie počiatočných údajov. Cenou za univerzálnosť je jej asymptotická povaha, t.j. nutnosť použiť relatívne veľké vzorky. V dobe moderných technológií však zhromaždenie správneho množstva údajov zvyčajne nie je ťažké.
Testovanie štatistických hypotéz pomocou intervalu spoľahlivosti
(modul 111)
Jedným z hlavných problémov riešených v štatistike je. Stručne povedané, jeho podstatou je toto. Vychádza sa napríklad z predpokladu, že očakávanie bežnej populácie sa rovná nejakej hodnote. Potom sa skonštruuje distribúcia priemerov vzorky, ktorú možno pozorovať s daným očakávaním. Ďalej sa pozrieme na to, kde sa v tomto podmienenom rozdelení nachádza skutočný priemer. Ak prekročí povolené limity, potom je výskyt takéhoto priemeru veľmi nepravdepodobný a pri jedinom opakovaní experimentu je takmer nemožný, čo je v rozpore s predloženou hypotézou, ktorá sa úspešne zamieta. Ak priemer neprekročí kritickú úroveň, hypotéza sa nezamietne (ale ani sa nepotvrdí!).
Takže pomocou intervalov spoľahlivosti, v našom prípade pre očakávanie, môžete otestovať aj niektoré hypotézy. Je to veľmi jednoduché. Predpokladajme, že aritmetický priemer pre nejakú vzorku je 100. Testuje sa hypotéza, že očakávaná hodnota je povedzme 90. To znamená, že ak otázku položíme primitívne, znie to takto: môže to byť so skutočnou hodnotou priemer rovný 90, pozorovaný priemer bol 100?
Na zodpovedanie tejto otázky budú potrebné ďalšie informácie o štandardnej odchýlke a veľkosti vzorky. Povedzme, že štandardná odchýlka je 30 a počet pozorovaní je 64 (na ľahké extrahovanie koreňa). Potom je štandardná chyba priemeru 30/8 alebo 3,75. Na výpočet 95 % intervalu spoľahlivosti budete musieť vyčleniť dve štandardné chyby na oboch stranách priemeru (presnejšie 1,96). Interval spoľahlivosti bude približne 100 ± 7,5 alebo od 92,5 do 107,5.
Ďalšie zdôvodnenie je nasledovné. Ak testovaná hodnota spadá do intervalu spoľahlivosti, potom to nie je v rozpore s hypotézou, pretože zapadá do limitov náhodných výkyvov (s pravdepodobnosťou 95 %). Ak je testovaný bod mimo intervalu spoľahlivosti, potom je pravdepodobnosť takejto udalosti veľmi malá, v každom prípade pod prijateľnou úrovňou. Preto sa hypotéza zamieta, pretože je v rozpore s pozorovanými údajmi. V našom prípade je hypotéza očakávania mimo intervalu spoľahlivosti (testovaná hodnota 90 nie je zahrnutá v intervale 100±7,5), preto ju treba zamietnuť. Pri odpovedi na vyššie uvedenú primitívnu otázku by sa malo povedať: nie, nemôže, v žiadnom prípade sa to stáva veľmi zriedka. Často to naznačuje konkrétnu pravdepodobnosť chybného zamietnutia hypotézy (úroveň p), a nie danú úroveň, podľa ktorej bol interval spoľahlivosti zostavený, ale o tom inokedy.
Ako vidíte, nie je ťažké vytvoriť interval spoľahlivosti pre priemer (alebo matematické očakávania). Hlavná vec je zachytiť podstatu a potom to pôjde. V praxi väčšina používa 95 % interval spoľahlivosti, čo sú približne dve štandardné chyby široké na oboch stranách priemeru.
To je zatiaľ všetko. Všetko najlepšie!
Odhad intervalov spoľahlivosti
Učebné ciele
Štatistiky zohľadňujú nasledovné dve hlavné úlohy:
Máme nejaký odhad založený na vzorových údajoch a chceme urobiť nejaké pravdepodobnostné vyhlásenie o tom, kde je skutočná hodnota odhadovaného parametra.
Máme konkrétnu hypotézu, ktorú je potrebné otestovať na základe vzorových údajov.
V tejto téme uvažujeme o prvom probléme. Zavádzame aj definíciu intervalu spoľahlivosti.
Interval spoľahlivosti je interval, ktorý je vytvorený okolo odhadovanej hodnoty parametra a ukazuje, kde leží skutočná hodnota odhadovaného parametra s a priori danou pravdepodobnosťou.
Po preštudovaní materiálu na túto tému:
zistiť, aký je interval spoľahlivosti odhadu;
naučiť sa klasifikovať štatistické problémy;
osvojiť si techniku konštrukcie intervalov spoľahlivosti pomocou štatistických vzorcov aj pomocou softvérových nástrojov;
naučiť sa určovať požadované veľkosti vzoriek na dosiahnutie určitých parametrov presnosti štatistických odhadov.
Rozdelenie charakteristík vzorky
T-distribúcia
Ako bolo uvedené vyššie, rozdelenie náhodnej premennej je blízke štandardizovanému normálnemu rozdeleniu s parametrami 0 a 1. Keďže nepoznáme hodnotu σ, nahradíme ju nejakým odhadom s . Množstvo má už iné rozdelenie, a to, príp Študentská distribúcia, ktorý je určený parametrom n -1 (počet stupňov voľnosti). Toto rozdelenie je blízke normálnemu rozdeleniu (čím väčšie n, tým bližšie sú rozdelenia).
Na obr. 95  Prezentuje sa študentské rozdelenie s 30 stupňami voľnosti. Ako vidíte, je veľmi blízko normálnemu rozdeleniu.
Prezentuje sa študentské rozdelenie s 30 stupňami voľnosti. Ako vidíte, je veľmi blízko normálnemu rozdeleniu.
Podobne ako funkcie pre prácu s normálnym rozdelením NORMDIST a NORMINV existujú funkcie pre prácu s t-rozdelením - STUDIST (TDIST) a STUDRASPBR (TINV). Príklad použitia týchto funkcií nájdete v súbore STUDRIST.XLS (šablóna a riešenie) a na obr. 96  .
.
Rozdelenie iných charakteristík
Ako už vieme, na určenie presnosti odhadu očakávania potrebujeme t-distribúciu. Na odhadnutie iných parametrov, ako je rozptyl, sú potrebné iné rozdelenia. Dve z nich sú F-distribúcia a x 2 -distribúcia.
Interval spoľahlivosti pre priemer
Interval spoľahlivosti je interval, ktorý je vytvorený okolo odhadovanej hodnoty parametra a ukazuje, kde leží skutočná hodnota odhadovaného parametra s apriórne danou pravdepodobnosťou.
Nastáva konštrukcia intervalu spoľahlivosti pre strednú hodnotu nasledujúcim spôsobom:
Príklad
Rýchle občerstvenie plánuje rozšíriť sortiment o nový typ chlebíčkov. Aby manažér mohol odhadnúť dopyt po ňom, plánuje náhodne vybrať 40 návštevníkov spomedzi tých, ktorí ho už vyskúšali, a požiadať ich, aby ohodnotili svoj postoj k novému produktu na stupnici od 1 do 10. Manažér chce odhadnúť očakávaný počet bodov, ktoré nový produkt získa, a zostrojte pre tento odhad 95 % interval spoľahlivosti. Ako to spraviť? (pozri súbor SANDWICH1.XLS (šablóna a riešenie).
Riešenie
Na vyriešenie tohto problému môžete použiť . Výsledky sú uvedené na obr. 97  .
.
Interval spoľahlivosti pre celkovú hodnotu
Niekedy je podľa vzorových údajov potrebné odhadnúť nie matematické očakávanie, ale celkový súčet hodnôt. Napríklad v situácii s audítorom môže byť zaujímavé odhadnúť nie priemernú hodnotu faktúry, ale súčet všetkých faktúr.
Nech N je celkový počet prvkov, n je veľkosť vzorky, T3 je súčet hodnôt vo vzorke, T" je odhad súčtu za celú populáciu, potom ![]() a interval spoľahlivosti sa vypočíta podľa vzorca , kde s je odhad štandardnej odchýlky pre vzorku, je odhad priemeru pre vzorku.
a interval spoľahlivosti sa vypočíta podľa vzorca , kde s je odhad štandardnej odchýlky pre vzorku, je odhad priemeru pre vzorku.
Príklad
Povedzme, že daňový úrad chce odhadnúť výšku celkových vrátených daní pre 10 000 daňovníkov. Daňovník buď dostane refundáciu, alebo zaplatí dodatočné dane. Nájdite 95 % interval spoľahlivosti pre vrátenú sumu za predpokladu veľkosti vzorky 500 ľudí (pozri súbor REFUND AMOUNT.XLS (šablóna a riešenie).
Riešenie
V programe StatPro neexistuje pre tento prípad žiadny špeciálny postup, môžete však vidieť, že hranice možno získať z hraníc pre priemer pomocou vyššie uvedených vzorcov (Obr. 98  ).
).
Interval spoľahlivosti pre pomer
Nech p je očakávaný podiel zákazníkov a pv je odhad tohto podielu získaný zo vzorky veľkosti n. Dá sa ukázať, že pre dostatočne veľké  distribúcia odhadu bude blízko normálu so strednou hodnotou p a štandardnou odchýlkou
distribúcia odhadu bude blízko normálu so strednou hodnotou p a štandardnou odchýlkou ![]() . Štandardná chyba odhadu je v tomto prípade vyjadrená ako
. Štandardná chyba odhadu je v tomto prípade vyjadrená ako  a interval spoľahlivosti ako
a interval spoľahlivosti ako  .
.
Príklad
Rýchle občerstvenie plánuje rozšíriť sortiment o nový typ chlebíčkov. Aby manažér odhadol dopyt po ňom, náhodne vybral 40 návštevníkov spomedzi tých, ktorí ho už vyskúšali, a požiadal ich, aby ohodnotili svoj postoj k novému produktu na stupnici od 1 do 10. Manažér chce odhadnúť očakávaný podiel zákazníkov, ktorí ohodnotia nový produkt aspoň 6 bodmi (očakáva, že títo zákazníci budú spotrebiteľmi nového produktu).
Riešenie
Spočiatku vytvoríme nový stĺpec na základe 1, ak skóre klienta bolo viac ako 6 bodov, a 0 v opačnom prípade (pozri súbor SANDWICH2.XLS (šablóna a riešenie).
Metóda 1
Počítaním sumy 1 odhadneme podiel a potom použijeme vzorce.
Hodnota z cr je prevzatá zo špeciálnych tabuliek normálneho rozdelenia (napríklad 1,96 pre 95 % interval spoľahlivosti).
Použitím tohto prístupu a konkrétnych údajov na konštrukciu 95 % intervalu získame nasledujúce výsledky (obr. 99).  ). Kritická hodnota parametra z cr je 1,96. Štandardná chyba odhadu je 0,077. Dolná hranica intervalu spoľahlivosti je 0,475. Horná hranica intervalu spoľahlivosti je 0,775. Manažér teda môže s 95 % istotou predpokladať, že percento zákazníkov, ktorí ohodnotia nový produkt 6 a viac bodov, bude medzi 47,5 a 77,5.
). Kritická hodnota parametra z cr je 1,96. Štandardná chyba odhadu je 0,077. Dolná hranica intervalu spoľahlivosti je 0,475. Horná hranica intervalu spoľahlivosti je 0,775. Manažér teda môže s 95 % istotou predpokladať, že percento zákazníkov, ktorí ohodnotia nový produkt 6 a viac bodov, bude medzi 47,5 a 77,5.
Metóda 2
Tento problém je možné vyriešiť pomocou štandardných nástrojov StatPro. Na to stačí poznamenať, že podiel sa v tomto prípade zhoduje s priemernou hodnotou stĺpca Typ. Ďalej aplikujte StatPro/štatistická inferencia/analýza jednej vzorky na vytvorenie intervalu spoľahlivosti pre strednú hodnotu (odhad očakávania) pre stĺpec Typ. Výsledky získané v tomto prípade budú veľmi blízke výsledkom 1. metódy (obr. 99).
Interval spoľahlivosti pre štandardnú odchýlku
s sa používa ako odhad štandardnej odchýlky (vzorec je uvedený v časti 1). Funkcia hustoty odhadu s je funkcia chí-kvadrát, ktorá má podobne ako t-rozdelenie n-1 stupňov voľnosti. Pre prácu s touto distribúciou existujú špeciálne funkcie CHI2DIST (CHIDIST) a CHI2OBR (CHIINV) .
Interval spoľahlivosti v tomto prípade už nebude symetrický. Podmienená schéma hraníc je znázornená na obr. 100 .
Príklad
Stroj by mal vyrábať diely s priemerom 10 cm.Vplyvom rôznych okolností však dochádza k chybám. Kontrolór kvality sa obáva dvoch vecí: po prvé, priemerná hodnota by mala byť 10 cm; po druhé, aj v tomto prípade, ak sú odchýlky veľké, mnohé detaily budú zamietnuté. Každý deň vyrobí vzorku 50 dielov (pozri súbor KONTROLA KVALITY.XLS (šablóna a riešenie). Aké závery môže takáto vzorka poskytnúť?
Riešenie
Konštruujeme 95 % intervaly spoľahlivosti pre priemer a pre štandardnú odchýlku pomocou StatPro/Štatistická inferencia/ Analýza jednej vzorky(Obr. 101  ).
).
Ďalej, za predpokladu normálneho rozdelenia priemerov, vypočítame podiel chybných výrobkov, pričom nastavíme maximálnu odchýlku 0,065. Pomocou možností vyhľadávacej tabuľky (prípad dvoch parametrov) zostrojíme závislosť percenta zmetkov od strednej hodnoty a smerodajnej odchýlky (obr. 102  ).
).
Interval spoľahlivosti pre rozdiel dvoch priemerov
Ide o jednu z najdôležitejších aplikácií štatistických metód. Príklady situácie.
Vedúci obchodu s odevmi by rád vedel, koľko viac alebo menej minie priemerná nakupujúca žena v obchode ako muž.
Obe letecké spoločnosti lietajú na podobných trasách. Spotrebiteľská organizácia by chcela porovnať rozdiel medzi priemerným očakávaným meškaním letu pre obe letecké spoločnosti.
Spoločnosť v jednom meste rozposiela kupóny na určité druhy tovaru a v inom nerozposiela. Manažéri chcú porovnať priemerné nákupy týchto položiek počas nasledujúcich dvoch mesiacov.
Predajca áut často rieši manželské páry na prezentáciách. Aby sme porozumeli ich osobným reakciám na prezentáciu, páry často vedú rozhovory oddelene. Manažér chce zhodnotiť rozdiel v hodnotení u mužov a žien.
Prípad nezávislých vzoriek
Stredný rozdiel bude mať t-distribúciu s n 1 + n 2 - 2 stupňami voľnosti. Interval spoľahlivosti pre μ 1 - μ 2 je vyjadrený pomerom:

Tento problém môžu vyriešiť nielen vyššie uvedené vzorce, ale aj štandardné nástroje StatPro. K tomu stačí podať žiadosť
Interval spoľahlivosti pre rozdiel medzi proporciami
Nech sú matematické očakávania akcií. Nech sú ich vzorové odhady postavené na vzorkách veľkosti n 1 a n 2, v tomto poradí. Potom je uvedený odhad rozdielu. Preto je interval spoľahlivosti pre tento rozdiel vyjadrený ako:
Tu z cr je hodnota získaná z normálneho rozdelenia špeciálnych tabuliek (napríklad 1,96 pre 95 % interval spoľahlivosti).
Smerodajná chyba odhadu je v tomto prípade vyjadrená vzťahom:
 .
.
Príklad
Obchod v rámci prípravy na veľký výpredaj vykonal nasledujúci marketingový prieskum. Bolo vybraných 300 najlepších kupujúcich a náhodne rozdelení do dvoch skupín po 150 členoch. Všetkým vybraným kupujúcim boli zaslané pozvánky na účasť na predaji, avšak len pre členov prvej skupiny bol priložený kupón s právom na zľavu 5 %. Pri predaji boli zaznamenané nákupy všetkých 300 vybraných kupujúcich. Ako môže manažér interpretovať výsledky a urobiť úsudok o efektívnosti kupónovania? (Pozri súbor COUPONS.XLS (šablóna a riešenie)).
Riešenie
Pre náš konkrétny prípad zo 150 zákazníkov, ktorí dostali zľavový kupón, 55 nakúpilo vo výpredaji a spomedzi 150, ktorí kupón nedostali, nakúpilo iba 35 (obr. 103  ). Potom sú hodnoty podielov vzorky 0,3667 a 0,2333. A vzorový rozdiel medzi nimi je rovný 0,1333, resp. Za predpokladu intervalu spoľahlivosti 95 % zistíme z tabuľky normálneho rozdelenia z cr = 1,96. Výpočet štandardnej chyby rozdielu vzorky je 0,0524. Nakoniec dostaneme, že spodná hranica 95% intervalu spoľahlivosti je 0,0307 a horná hranica je 0,2359. Získané výsledky možno interpretovať tak, že na každých 100 zákazníkov, ktorí získali zľavový kupón, môžeme očakávať od 3 do 23 nových zákazníkov. Treba však mať na pamäti, že tento záver sám o sebe neznamená efektívnosť využitia kupónov (pretože poskytnutím zľavy prichádzame o zisk!). Ukážme si to na konkrétnych údajoch. Predpokladajme, že priemerná suma nákupu je 400 rubľov, z toho 50 rubľov. je tam zisk obchodu. Potom sa očakávaný zisk na 100 zákazníkov, ktorí nedostali kupón, rovná:
). Potom sú hodnoty podielov vzorky 0,3667 a 0,2333. A vzorový rozdiel medzi nimi je rovný 0,1333, resp. Za predpokladu intervalu spoľahlivosti 95 % zistíme z tabuľky normálneho rozdelenia z cr = 1,96. Výpočet štandardnej chyby rozdielu vzorky je 0,0524. Nakoniec dostaneme, že spodná hranica 95% intervalu spoľahlivosti je 0,0307 a horná hranica je 0,2359. Získané výsledky možno interpretovať tak, že na každých 100 zákazníkov, ktorí získali zľavový kupón, môžeme očakávať od 3 do 23 nových zákazníkov. Treba však mať na pamäti, že tento záver sám o sebe neznamená efektívnosť využitia kupónov (pretože poskytnutím zľavy prichádzame o zisk!). Ukážme si to na konkrétnych údajoch. Predpokladajme, že priemerná suma nákupu je 400 rubľov, z toho 50 rubľov. je tam zisk obchodu. Potom sa očakávaný zisk na 100 zákazníkov, ktorí nedostali kupón, rovná:
50 0,2333 100 \u003d 1166,50 rubľov.
Podobné výpočty pre 100 kupujúcich, ktorí dostali kupón, uvádzajú:
30 0,3667 100 \u003d 1100,10 rubľov.
Pokles priemerného zisku na 30 sa vysvetľuje skutočnosťou, že pri použití zľavy kupujúci, ktorí dostali kupón, nakúpia v priemere za 380 rubľov.
Konečný záver teda naznačuje neefektívnosť používania takýchto kupónov v tejto konkrétnej situácii.
Komentujte. Tento problém je možné vyriešiť pomocou štandardných nástrojov StatPro. Na to stačí zredukovať tento problém na problém odhadu rozdielu dvoch priemerov metódou a potom použiť StatPro/Štatistická inferencia/Dvojvzorková analýza vytvoriť interval spoľahlivosti pre rozdiel medzi dvoma strednými hodnotami.
Kontrola intervalu spoľahlivosti
Dĺžka intervalu spoľahlivosti závisí od nasledujúcich podmienok:
priamo údaje (štandardná odchýlka);
úroveň významnosti;
veľkosť vzorky.
Veľkosť vzorky na odhad priemeru
Najprv zvážime problém vo všeobecnom prípade. Označme hodnotu polovice dĺžky intervalu spoľahlivosti, ktorý nám bol daný ako B (obr. 104  ). Vieme, že interval spoľahlivosti pre strednú hodnotu nejakej náhodnej premennej X je vyjadrený ako
). Vieme, že interval spoľahlivosti pre strednú hodnotu nejakej náhodnej premennej X je vyjadrený ako ![]() , kde
, kde ![]() . Za predpokladu, že:
. Za predpokladu, že:
![]() a vyjadrením n dostaneme .
a vyjadrením n dostaneme .
Žiaľ, presnú hodnotu rozptylu náhodnej premennej X nepoznáme. Okrem toho nepoznáme hodnotu t cr , pretože závisí od n prostredníctvom počtu stupňov voľnosti. V tejto situácii môžeme urobiť nasledovné. Namiesto rozptylu s používame nejaký odhad rozptylu pre niektoré dostupné realizácie skúmanej náhodnej premennej. Namiesto hodnoty t cr použijeme pre normálne rozdelenie hodnotu z cr. To je celkom prijateľné, pretože funkcie hustoty pre normálne a t-rozdelenie sú veľmi blízke (okrem prípadu malého n ). Požadovaný vzorec má teda tvar:
 .
.
Keďže vzorec dáva, všeobecne povedané, neceločíselné výsledky, za požadovanú veľkosť vzorky sa považuje zaokrúhlenie s nadbytkom výsledku.
Príklad
Rýchle občerstvenie plánuje rozšíriť sortiment o nový typ chlebíčkov. Aby manažér odhadol dopyt po ňom, náhodne plánuje vybrať určitý počet návštevníkov spomedzi tých, ktorí ho už vyskúšali, a požiadať ich, aby ohodnotili svoj postoj k novému produktu na stupnici od 1 do 10. Manažér chce odhadnúť očakávaný počet bodov, ktoré nový produkt získa, a vykresliť 95 % interval spoľahlivosti tohto odhadu. Zároveň chce, aby polovičná šírka intervalu spoľahlivosti nepresiahla 0,3. Koľko návštevníkov potrebuje na hlasovanie?
nasledovne:

Tu r ots je odhad zlomku p a B je daná polovica dĺžky intervalu spoľahlivosti. Nafúknutú hodnotu pre n možno získať pomocou hodnoty r ots= 0,5. V tomto prípade dĺžka intervalu spoľahlivosti nepresiahne danú hodnotu B pre žiadnu skutočnú hodnotu p.
Príklad
Nechajte manažéra z predchádzajúceho príkladu, aby odhadol podiel zákazníkov, ktorí preferujú nový typ produktu. Chce vytvoriť 90% interval spoľahlivosti, ktorého polovičná dĺžka je menšia alebo rovná 0,05. Koľko klientov by malo byť náhodne vybratých?
Riešenie
V našom prípade je hodnota z cr = 1,645. Preto sa požadované množstvo vypočíta ako  .
.
Ak by mal manažér dôvod domnievať sa, že požadovaná hodnota p je napríklad asi 0,3, tak dosadením tejto hodnoty do vyššie uvedeného vzorca by sme dostali menšiu hodnotu náhodnej vzorky, konkrétne 228.
Vzorec na určenie náhodné veľkosti vzoriek v prípade rozdielu medzi dvoma priemermi napísané ako:
 .
.
Príklad
Niektoré počítačové spoločnosti majú centrum služieb zákazníkom. V poslednom čase sa zvýšil počet sťažností zákazníkov na zlú kvalitu služieb. Stredisko služieb zamestnáva prevažne dva typy zamestnancov: tých, ktorí majú málo skúseností, no absolvovali špeciálne školenia, a tých, ktorí majú rozsiahle praktické skúsenosti, no neabsolvovali špeciálne kurzy. Spoločnosť chce analyzovať sťažnosti zákazníkov za posledných šesť mesiacov a porovnať ich priemerné počty na každú z dvoch skupín zamestnancov. Predpokladá sa, že počty vo vzorkách pre obe skupiny budú rovnaké. Koľko zamestnancov musí byť zahrnutých do vzorky, aby sme získali 95 % interval s polovičnou dĺžkou nie väčšou ako 2?
Riešenie
Tu σ ots je odhad štandardnej odchýlky oboch náhodných premenných za predpokladu, že sú blízko. V našej úlohe teda musíme nejakým spôsobom získať tento odhad. Dá sa to urobiť napríklad takto. Pri pohľade na údaje o sťažnostiach zákazníkov za posledných šesť mesiacov si manažér môže všimnúť, že vo všeobecnosti existuje 6 až 36 sťažností na zamestnanca. S vedomím, že pre normálne rozdelenie sú prakticky všetky hodnoty v rámci troch štandardných odchýlok od priemeru, môže odôvodnene veriť, že:
![]() , odkiaľ σ ots = 5.
, odkiaľ σ ots = 5.
Dosadením tejto hodnoty do vzorca dostaneme  .
.
Vzorec na určenie veľkosť náhodnej vzorky v prípade odhadu rozdielu medzi podielmi vyzerá ako:

Príklad
Niektorá spoločnosť má dve továrne na výrobu podobných produktov. Manažér spoločnosti chce porovnať chybovosť oboch tovární. Podľa dostupných informácií je miera odmietnutia v oboch továrňach od 3 do 5 %. Predpokladá sa, že vytvorí 99 % interval spoľahlivosti s polovičnou dĺžkou maximálne 0,005 (alebo 0,5 %). Koľko produktov by sa malo vybrať z každej továrne?
Riešenie
Tu p 1ot a p 2ot sú odhady dvoch neznámych zlomkov odpadu v 1. a 2. továrni. Ak dáme p 1ots \u003d p 2ots \u003d 0,5, potom dostaneme nadhodnotenú hodnotu pre n. Ale keďže v našom prípade máme nejaké a priori informácie o týchto podieloch, berieme horný odhad týchto podielov, a to 0,05. Dostaneme
Pri odhadovaní niektorých parametrov populácie zo vzorových údajov je užitočné poskytnúť nielen bodový odhad parametra, ale aj interval spoľahlivosti, ktorý naznačuje, kde môže ležať presná hodnota odhadovaného parametra.
V tejto kapitole sme sa oboznámili aj s kvantitatívnymi vzťahmi, ktoré nám umožňujú zostaviť takéto intervaly pre rôzne parametre; naučené spôsoby kontroly dĺžky intervalu spoľahlivosti.
Upozorňujeme tiež, že problém odhadu veľkosti vzorky (problém plánovania experimentu) možno vyriešiť pomocou štandardných nástrojov StatPro, a to StatPro/Statistical Inference/Sample Size Selection.
INTERVALY BEZPEČNOSTI PRE FREKVENCIE A ČASTI
© 2008
Národný inštitút verejného zdravia, Oslo, Nórsko
Článok popisuje a rozoberá výpočet intervalov spoľahlivosti pre frekvencie a proporcie pomocou Waldovej, Wilsonovej, Klopperovej-Pearsonovej metódy, pomocou uhlovej transformácie a Waldovej metódy s Agresti-Cowllovou korekciou. Predkladaný materiál poskytuje všeobecné informácie o metódach výpočtu intervalov spoľahlivosti pre frekvencie a podiely a má vzbudiť záujem čitateľov časopisu nielen o používanie intervalov spoľahlivosti pri prezentovaní výsledkov vlastného výskumu, ale aj o prečítanie odbornej literatúry pred začať pracovať na budúcich publikáciách.
Kľúčové slová: interval spoľahlivosti, frekvencia, podiel
V jednej z predchádzajúcich publikácií bol stručne spomenutý popis kvalitatívnych údajov a bolo oznámené, že ich intervalový odhad je vhodnejší ako bodový odhad na popis frekvencie výskytu študovanej charakteristiky v bežnej populácii. Vzhľadom na to, že štúdie sa vykonávajú s použitím údajov zo vzorky, projekcia výsledkov na všeobecnú populáciu musí obsahovať prvok nepresnosti v odhade vzorky. Interval spoľahlivosti je mierou presnosti odhadovaného parametra. Je zaujímavé, že v niektorých knihách o základoch štatistiky pre lekárov je téma intervalov spoľahlivosti pre frekvencie úplne ignorovaná. V tomto článku zvážime niekoľko spôsobov, ako vypočítať intervaly spoľahlivosti pre frekvencie, za predpokladu charakteristík vzorky, ako je neopakovanie sa a reprezentatívnosť, ako aj nezávislosť pozorovaní od seba navzájom. Frekvencia v tomto článku nie je chápaná ako absolútne číslo, ktoré ukazuje, koľkokrát sa tá či oná hodnota vyskytuje v súhrne, ale ako relatívna hodnota, ktorá určuje podiel účastníkov štúdie, ktorí majú danú vlastnosť.
V biomedicínskom výskume sa najčastejšie používajú 95% intervaly spoľahlivosti. Tento interval spoľahlivosti je oblasť, do ktorej skutočný podiel spadá v 95 % prípadov. Inými slovami, s 95% istotou možno povedať, že skutočná hodnota frekvencie výskytu znaku v bežnej populácii bude v rámci 95% intervalu spoľahlivosti.
Väčšina štatistických učebníc pre medicínskych výskumníkov uvádza, že frekvenčná chyba sa vypočítava pomocou vzorca
kde p je frekvencia výskytu znaku vo vzorke (hodnota od 0 do 1). Vo väčšine domácich vedeckých článkov sa uvádza hodnota frekvencie výskytu znaku vo vzorke (p), ako aj jeho chyba (s) v tvare p ± s. Je však účelnejšie uviesť 95 % interval spoľahlivosti pre frekvenciu výskytu znaku vo všeobecnej populácii, ktorý bude zahŕňať hodnoty od
 |
 predtým.
predtým.
V niektorých učebniciach sa pri malých vzorkách odporúča nahradiť hodnotu 1,96 hodnotou t pre N - 1 stupňov voľnosti, kde N je počet pozorovaní vo vzorke. Hodnota t sa nachádza v tabuľkách pre t-rozdelenie, ktoré sú dostupné takmer vo všetkých učebniciach štatistiky. Použitie distribúcie t pre Waldovu metódu neposkytuje viditeľné výhody oproti iným metódam diskutovaným nižšie, a preto nie je niektorými autormi vítané.
Vyššie uvedená metóda na výpočet intervalov spoľahlivosti pre frekvencie alebo proporcie je pomenovaná po Abrahamovi Waldovi (Abraham Wald, 1902–1950), pretože sa začala široko používať po publikácii Walda a Wolfowitza v roku 1939. Samotnú metódu však navrhol Pierre Simon Laplace (1749–1827) už v roku 1812.
Waldova metóda je veľmi populárna, no jej aplikácia je spojená so značnými problémami. Metóda sa neodporúča pre malé veľkosti vzoriek, ako aj v prípadoch, keď frekvencia výskytu prvku má tendenciu k 0 alebo 1 (0 % alebo 100 %) a jednoducho nie je možná pre frekvencie 0 a 1. Okrem toho, aproximácia normálneho rozdelenia, ktorá sa používa pri výpočte chyby, "nefunguje" v prípadoch, keď n p< 5 или n · (1 – p) < 5 . Более консервативные статистики считают, что n · p и n · (1 – p) должны быть не менее 10 . Более детальное рассмотрение метода Вальда показало, что полученные с его помощью доверительные интервалы в большинстве случаев слишком узки, то есть их применение ошибочно создает слишком оптимистичную картину, особенно при удалении частоты встречаемости признака от 0,5, или 50 % . К тому же при приближении частоты к 0 или 1 доверительный интревал может принимать отрицательные значения или превышать 1, что выглядит абсурдно для частот. Многие авторы совершенно справедливо не рекомендуют применять данный метод не только в уже упомянутых случаях, но и тогда, когда частота встречаемости признака менее 25 % или более 75 % . Таким образом, несмотря на простоту расчетов, метод Вальда может применяться лишь в очень ограниченном числе случаев. Зарубежные исследователи более категоричны в своих выводах и однозначно рекомендуют не применять этот метод для небольших выборок , а ведь именно с такими выборками часто приходится иметь дело исследователям-медикам.
Keďže nová premenná je normálne rozdelená, dolná a horná hranica 95 % intervalu spoľahlivosti pre premennú φ bude φ-1,96 a φ+1,96 vľavo">


Namiesto 1,96 pre malé vzorky sa odporúča nahradiť hodnotu t za N - 1 stupňov voľnosti. Táto metóda nedáva záporné hodnoty a umožňuje presnejšie odhadnúť intervaly spoľahlivosti pre frekvencie ako Waldova metóda. Okrem toho je opísaný v mnohých domácich referenčných knihách o lekárskej štatistike, čo však neviedlo k jeho širokému použitiu v lekárskom výskume. Výpočet intervalov spoľahlivosti pomocou uhlovej transformácie sa neodporúča pre frekvencie blížiace sa k 0 alebo 1.
Tu popis metód na odhadovanie intervalov spoľahlivosti vo väčšine kníh o základoch štatistiky pre medicínskych výskumníkov zvyčajne končí a tento problém je typický nielen pre domácu, ale aj zahraničnú literatúru. Obe metódy sú založené na centrálnej limitnej vete, čo znamená veľkú vzorku.
Berúc do úvahy nedostatky odhadu intervalov spoľahlivosti pomocou vyššie uvedených metód, Clopper (Clopper) a Pearson (Pearson) navrhli v roku 1934 metódu na výpočet takzvaného presného intervalu spoľahlivosti, berúc do úvahy binomickú distribúciu študovaného znaku. Táto metóda je dostupná v mnohých online kalkulačkách, avšak takto získané intervaly spoľahlivosti sú vo väčšine prípadov príliš široké. Zároveň sa táto metóda odporúča použiť v prípadoch, keď je potrebný konzervatívny odhad. Stupeň konzervatívnosti metódy sa zvyšuje so znižovaním veľkosti vzorky, najmä pre N< 15 . описывает применение функции биномиального распределения для анализа качественных данных с использованием MS Excel, в том числе и для определения доверительных интервалов, однако расчет последних для частот в электронных таблицах не «затабулирован» в удобном для пользователя виде, а потому, вероятно, и не используется большинством исследователей.
Podľa mnohých štatistikov sa najoptimálnejší odhad intervalov spoľahlivosti pre frekvencie vykonáva Wilsonovou metódou, navrhnutou už v roku 1927, ale v domácom biomedicínskom výskume sa prakticky nepoužíva. Táto metóda nielenže umožňuje odhadnúť intervaly spoľahlivosti pre veľmi malé aj veľmi vysoké frekvencie, ale je použiteľná aj pre malý počet pozorovaní. Vo všeobecnosti má interval spoľahlivosti podľa Wilsonovho vzorca tvar od
 |
 |
kde pri výpočte 95 % intervalu spoľahlivosti nadobúda hodnotu 1,96, N je počet pozorovaní a p je frekvencia znaku vo vzorke. Táto metóda je dostupná v online kalkulačkách, takže jej aplikácia nie je problematická. a neodporúčame používať túto metódu pre n p< 4 или n · (1 – p) < 4 по причине слишком грубого приближения распределения р к нормальному в такой ситуации, однако зарубежные статистики считают метод Уилсона применимым и для малых выборок .
Okrem Wilsonovej metódy sa tiež verí, že Waldova metóda korigovaná Agresti-Caull poskytuje optimálny odhad intervalu spoľahlivosti pre frekvencie. Agresti-Coullova korekcia je vo Waldovom vzorci nahradením frekvencie výskytu znaku vo vzorke (p) za p`, pri výpočte, ktorá 2 sa pripočítava do čitateľa a 4 do menovateľa, tj. , p` = (X + 2) / (N + 4), kde X je počet účastníkov štúdie, ktorí majú skúmanú vlastnosť, a N je veľkosť vzorky. Táto modifikácia poskytuje výsledky veľmi podobné výsledkom Wilsonovho vzorca, s výnimkou prípadov, keď sa frekvencia udalostí blíži k 0 % alebo 100 % a vzorka je malá. Okrem vyššie uvedených metód na výpočet intervalov spoľahlivosti pre frekvencie boli navrhnuté korekcie kontinuity pre Waldovu metódu aj Wilsonovu metódu pre malé vzorky, ale štúdie ukázali, že ich použitie je nevhodné.
Zvážte použitie vyššie uvedených metód na výpočet intervalov spoľahlivosti pomocou dvoch príkladov. V prvom prípade študujeme veľkú vzorku 1000 náhodne vybraných účastníkov štúdie, z ktorých 450 má skúmanú vlastnosť (môže to byť rizikový faktor, výsledok alebo akýkoľvek iný znak), čo je frekvencia 0,45, resp. 45 %. V druhom prípade sa štúdia uskutočňuje na malej vzorke, povedzme, iba 20 ľudí a iba 1 účastník štúdie (5 %) má skúmanú vlastnosť. Intervaly spoľahlivosti pre Waldovu metódu, Waldovu metódu s Agresti-Coll korekciou, Wilsonovu metódu boli vypočítané pomocou online kalkulačky vyvinutej Jeffom Saurom (http://www./wald.htm). Wilsonove intervaly spoľahlivosti korigované na kontinuitu boli vypočítané pomocou kalkulačky poskytnutej Wassar Stats: Web Site for Statistical Computation (http://faculty.vassar.edu/lowry/prop1.html). Výpočty pomocou Fisherovej uhlovej transformácie sa uskutočňovali "ručne" s použitím kritickej hodnoty t pre 19 a 999 stupňov voľnosti. Výsledky výpočtu sú uvedené v tabuľke pre oba príklady.
Intervaly spoľahlivosti vypočítané šiestimi rôznymi spôsobmi pre dva príklady opísané v texte
Metóda výpočtu intervalu spoľahlivosti |
P = 0,0500 alebo 5 % | 95 % CI pre X = 450, N = 1 000, P = 0,4500 alebo 45 % |
–0,0455–0,2541 | ||
Walda s korekciou Agresti-Coll | <,0001–0,2541 | |
Wilson s korekciou kontinuity | ||
Klopper-Pearsonova "presná metóda" | ||
Uhlová transformácia | <0,0001–0,1967 |
Ako je možné vidieť z tabuľky, v prvom príklade interval spoľahlivosti vypočítaný „všeobecne akceptovanou“ Waldovou metódou ide do zápornej oblasti, čo nemôže byť prípad frekvencií. Žiaľ, takéto incidenty nie sú v ruskej literatúre nezvyčajné. Tradičný spôsob reprezentácie údajov ako frekvencie a jej chyba tento problém čiastočne maskuje. Napríklad, ak je frekvencia výskytu vlastnosti (v percentách) prezentovaná ako 2,1 ± 1,4, potom to nie je také „dráždivé“ ako 2,1 % (95 % CI: –0,7; 4,9), hoci a znamená to isté. Waldova metóda s Agresti-Coullovou korekciou a výpočtom pomocou uhlovej transformácie dáva dolnú hranicu smerujúcu k nule. Wilsonova metóda s korekciou kontinuity a „presná metóda“ poskytujú širšie intervaly spoľahlivosti ako Wilsonova metóda. V druhom príklade všetky metódy poskytujú približne rovnaké intervaly spoľahlivosti (rozdiely sa objavujú iba v tisícinách), čo nie je prekvapujúce, pretože frekvencia udalosti v tomto príklade sa príliš nelíši od 50 % a veľkosť vzorky je dosť veľká. .
Čitateľom, ktorých zaujíma tento problém, môžeme odporučiť práce R. G. Newcomba a Browna, Caia a Dasguptu, ktoré uvádzajú klady a zápory použitia 7 a 10 rôznych metód na výpočet intervalov spoľahlivosti, resp. Z domácich príručiek sa odporúča kniha a, v ktorej sú okrem podrobného opisu teórie uvedené aj Waldova a Wilsonova metóda, ako aj metóda na výpočet intervalov spoľahlivosti s prihliadnutím na binomické rozdelenie frekvencií. Okrem bezplatných online kalkulačiek (http://www./wald.htm a http://faculty.vassar.edu/lowry/prop1.html) možno intervaly spoľahlivosti pre frekvencie (nielen!) vypočítať pomocou Program CIA (Confidence Intervals Analysis), ktorý si môžete stiahnuť z http://www. lekárska škola. soton. ac. uk/cia/ .
Nasledujúci článok sa bude zaoberať jednorozmernými spôsobmi porovnávania kvalitatívnych údajov.
Bibliografia
Banerjee A. Lekárska štatistika v jednoduchom jazyku: úvodný kurz / A. Banerzhi. - M. : Praktické lekárstvo, 2007. - 287 s. Lekárska štatistika / . - M. : Lekárska informačná agentúra, 2007. - 475 s. Glanz S. Mediko-biologická štatistika / S. Glants. - M. : Prax, 1998. Typy údajov, overovanie distribúcie a popisná štatistika / // Ekológia človeka - 2008. - č. 1. - S. 52–58. Zhizhin K.S.. Lekárska štatistika: učebnica / . - Rostov n / D: Phoenix, 2007. - 160 s. Aplikovaná lekárska štatistika / , . - St. Petersburg. : Folio, 2003. - 428 s. Lakin G. F. Biometria / . - M. : Vyššia škola, 1990. - 350 s. Medik V. A. Matematická štatistika v medicíne / , . - M. : Financie a štatistika, 2007. - 798 s. Matematická štatistika v klinickom výskume / , . - M. : GEOTAR-MED, 2001. - 256 s. Junkerov V. A. Medicínsko-štatistické spracovanie údajov medicínskeho výskumu /,. - St. Petersburg. : VmedA, 2002. - 266 s. Agresti A. Pre intervalový odhad binomických proporcií je približné lepšie ako presné / A. Agresti, B. Coull // Americký štatistik. - 1998. - N 52. - S. 119-126. Altman D.Štatistika s istotou // D. Altman, D. Machin, T. Bryant, M. J. Gardner. - Londýn: BMJ Books, 2000. - 240 s. Brown L.D. Intervalový odhad pre binomický podiel / L. D. Brown, T. T. Cai, A. Dasgupta // Štatistická veda. - 2001. - N 2. - S. 101-133. Clopper C.J. Použitie spoľahlivosti alebo fiduciálnych limitov ilustrované v prípade binomickej / C. J. Clopper, E. S. Pearson // Biometrika. - 1934. - N 26. - S. 404-413. Garcia-Perez M.A. O intervale spoľahlivosti pre binomický parameter / M. A. Garcia-Perez // Kvalita a kvantita. - 2005. - N 39. - S. 467-481. Motulsky H. Intuitívna bioštatistika // H. Motulsky. - Oxford: Oxford University Press, 1995. - 386 s. Newcombe R.G. Obojstranné intervaly spoľahlivosti pre jednu proporciu: Porovnanie siedmich metód / R. G. Newcombe // Štatistika v medicíne. - 1998. - N. 17. - S. 857–872. Sauro J. Odhadovanie miery dokončenia z malých vzoriek pomocou binomických intervalov spoľahlivosti: porovnania a odporúčania / J. Sauro, J. R. Lewis // Zborník výročného stretnutia spoločnosti pre ľudské faktory a ergonómiu. – Orlando, FL, 2005. Wald A. Medze spoľahlivosti pre spojité distribučné funkcie // A. Wald, J. Wolfovitz // Annals of Mathematical Statistics. - 1939. - N 10. - S. 105–118. Wilson E. B. Pravdepodobná inferencia, zákon nástupníctva a štatistická inferencia / E. B. Wilson // Journal of American Statistical Association. - 1927. - N 22. - S. 209-212.INTERVALY DÔVERY PRE PROPORCIE
A. M. Grjibovski
Národný inštitút verejného zdravia, Oslo, Nórsko
Článok predstavuje niekoľko metód na výpočty intervalov spoľahlivosti pre binomické proporcie, a to Waldovu, Wilsonovu, arcsínusovú, Agresti-Coullovu a presnú Clopper-Pearsonovu metódu. Príspevok poskytuje len všeobecný úvod do problému odhadu intervalu spoľahlivosti binomickej proporcie a jeho cieľom je nielen podnietiť čitateľov k používaniu intervalov spoľahlivosti pri prezentovaní výsledkov vlastných empirických výskumných intervalov, ale aj podnietiť ich, aby si prezreli štatistické knihy pred na analýzu vlastných údajov a prípravu rukopisov.
Kľúčové slová: interval spoľahlivosti, podiel
Kontaktné informácie:
– Senior Advisor, National Institute of Public Health, Oslo, Nórsko
Akákoľvek vzorka poskytuje iba približnú predstavu o všeobecnej populácii a všetky štatistické charakteristiky vzorky (priemer, režim, rozptyl ...) sú aproximáciou alebo odhadom všeobecných parametrov, ktoré sa vo väčšine prípadov nedajú vypočítať z dôvodu neprístupnosť bežnej populácie (obrázok 20) .
Obrázok 20. Chyba pri odbere vzoriek
Môžete však určiť interval, v ktorom s určitou mierou pravdepodobnosti leží skutočná (všeobecná) hodnota štatistickej charakteristiky. Tento interval sa nazýva d interval spoľahlivosti (CI).
Takže všeobecný priemer s pravdepodobnosťou 95 % leží v rámci
od do, (20)
kde t - tabuľková hodnota študentského kritéria pre α = 0,05 a f= n-1
V tomto prípade možno nájsť 99% CI t vybraný pre α =0,01.
Aký je praktický význam intervalu spoľahlivosti?
Široký interval spoľahlivosti naznačuje, že priemer vzorky presne neodráža priemer populácie. Je to zvyčajne spôsobené nedostatočnou veľkosťou vzorky, prípadne jej heterogenitou, t.j. veľký rozptyl. Obidve poskytujú veľkú chybu v priemere, a teda aj širší CI. A to je dôvod vrátiť sa do fázy plánovania výskumu.
Horná a dolná hranica CI hodnotia, či budú výsledky klinicky významné
Zastavme sa podrobnejšie pri otázke štatistickej a klinickej významnosti výsledkov štúdia skupinových vlastností. Pripomeňme, že úlohou štatistiky je na základe vzorových údajov odhaliť aspoň nejaké rozdiely vo všeobecných populáciách. Úlohou lekára je nájsť také (nie žiadne) rozdiely, ktoré pomôžu diagnostike alebo liečbe. A nie vždy štatistické závery sú základom pre klinické závery. Štatisticky významný pokles hemoglobínu o 3 g/l teda nie je dôvodom na obavy. A naopak, ak nejaký problém v ľudskom tele nemá masový charakter na úrovni celej populácie, nie je to dôvod, aby sme sa týmto problémom nezaoberali.
|
Túto pozíciu zvážime v príklad. Vedcov zaujímalo, či chlapci, ktorí mali nejaké infekčné ochorenie, nezaostávajú v raste za svojimi rovesníkmi. Za týmto účelom bola vykonaná selektívna štúdia, ktorej sa zúčastnilo 10 chlapcov, ktorí mali toto ochorenie. Výsledky sú uvedené v tabuľke 23. Tabuľka 23. Štatistické výsledky
Z týchto výpočtov vyplýva, že selektívna priemerná výška 10-ročných chlapcov, ktorí prekonali nejaký druh infekčného ochorenia, sa blíži k normálu (132,5 cm). Spodná hranica intervalu spoľahlivosti (126,6 cm) však naznačuje, že existuje 95 % pravdepodobnosť, že skutočná priemerná výška týchto detí zodpovedá pojmu „nízky vzrast“, t.j. tieto deti sú zakrpatené. V tomto príklade sú výsledky výpočtov intervalu spoľahlivosti klinicky významné. |
|||||||||||||||||||
Cieľ– naučiť študentov algoritmy na výpočet intervalov spoľahlivosti štatistických parametrov.
Počas štatistického spracovania údajov by vypočítaný aritmetický priemer, variačný koeficient, korelačný koeficient, rozdielové kritériá a ďalšie bodové štatistiky mali dostať kvantitatívne medze spoľahlivosti, ktoré naznačujú možné kolísanie ukazovateľa smerom nahor a nadol v rámci intervalu spoľahlivosti.
Príklad 3.1
.
Distribúcia vápnika v krvnom sére opíc, ako už bolo stanovené, je charakterizovaná nasledujúcimi selektívnymi ukazovateľmi: = 11,94 mg%;  = 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (
= 0,127 mg%; n= 100. Je potrebné určiť interval spoľahlivosti pre všeobecný priemer (  ) s úrovňou spoľahlivosti P
= 0,95.
) s úrovňou spoľahlivosti P
= 0,95.
Všeobecný priemer je s určitou pravdepodobnosťou v intervale:
 , kde
, kde  – vzorový aritmetický priemer; t- Študentské kritérium;
– vzorový aritmetický priemer; t- Študentské kritérium;  je chyba aritmetického priemeru.
je chyba aritmetického priemeru.
Podľa tabuľky „Hodnoty študentského kritéria“ nájdeme hodnotu
 s úrovňou spoľahlivosti 0,95 a počtom stupňov voľnosti k\u003d 100-1 \u003d 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
s úrovňou spoľahlivosti 0,95 a počtom stupňov voľnosti k\u003d 100-1 \u003d 99. Rovná sa 1,982. Spolu s hodnotami aritmetického priemeru a štatistickej chyby dosadíme do vzorca:
alebo 11.69  12,19
12,19
S pravdepodobnosťou 95 % teda možno tvrdiť, že všeobecný priemer tohto normálneho rozdelenia je medzi 11,69 a 12,19 mg %.
Príklad 3.2
. Určite hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl (  ) distribúcia vápnika v krvi opíc, ak je známe, že
) distribúcia vápnika v krvi opíc, ak je známe, že  = 1,60, s n
= 100.
= 1,60, s n
= 100.
Na vyriešenie problému môžete použiť nasledujúci vzorec:
Kde  je štatistická chyba rozptylu.
je štatistická chyba rozptylu.
Nájdite chybu rozptylu vzorky pomocou vzorca:  . Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
. Rovná sa 0,11. Význam t- kritérium s pravdepodobnosťou spoľahlivosti 0,95 a počtom stupňov voľnosti k= 100–1 = 99 je známe z predchádzajúceho príkladu.
Použime vzorec a získame:
alebo 1,38  1,82
1,82
Presnejší interval spoľahlivosti pre všeobecný rozptyl možno skonštruovať pomocou  (chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria
(chí-kvadrát) - Pearsonov test. Kritické body pre toto kritérium sú uvedené v špeciálnej tabuľke. Pri použití kritéria  na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta podľa vzorca
na vytvorenie intervalu spoľahlivosti sa používa obojstranná hladina významnosti. Pre dolnú hranicu sa hladina významnosti vypočíta podľa vzorca  , pre hornú časť
, pre hornú časť  . Napríklad pre úroveň dôvery
. Napríklad pre úroveň dôvery  =
0,99
=
0,99 = 0,010,
= 0,010, = 0,990. V súlade s tým podľa tabuľky rozdelenia kritických hodnôt
= 0,990. V súlade s tým podľa tabuľky rozdelenia kritických hodnôt  s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty
s vypočítanými hladinami spoľahlivosti a počtom stupňov voľnosti k= 100 – 1= 99, nájdite hodnoty  a
a  . Dostaneme
. Dostaneme  rovná sa 135,80 a
rovná sa 135,80 a  rovná sa 70,06.
rovná sa 70,06.
Na nájdenie hraníc spoľahlivosti všeobecného rozptylu pomocou  používame vzorce: pre dolnú hranicu
používame vzorce: pre dolnú hranicu  , pre hornú hranicu
, pre hornú hranicu  . Nájdené hodnoty nahraďte údajmi úlohy
. Nájdené hodnoty nahraďte údajmi úlohy  do vzorcov:
do vzorcov:  =
1,17;
=
1,17; = 2,26. Teda s úrovňou dôvery P= 0,99 alebo 99 % bude všeobecný rozptyl ležať v rozsahu od 1,17 do 2,26 mg % vrátane.
= 2,26. Teda s úrovňou dôvery P= 0,99 alebo 99 % bude všeobecný rozptyl ležať v rozsahu od 1,17 do 2,26 mg % vrátane.
Príklad 3.3 . Medzi 1000 semenami pšenice z dávky, ktoré dorazili k výťahu, sa našlo 120 semien infikovaných námeľom. Je potrebné určiť pravdepodobné hranice celkového podielu infikovaných semien v danej partii pšenice.
Hranice spoľahlivosti pre všeobecný podiel pre všetky jeho možné hodnoty by sa mali určiť podľa vzorca:
 ,
,
Kde n je počet pozorovaní; m je absolútne číslo jednej zo skupín; t je normalizovaná odchýlka.
Frakcia vzorky infikovaných semien sa rovná  alebo 12 %. S úrovňou dôvery R= 95 % normalizovaná odchýlka ( t-Študentské kritérium pre k
=
alebo 12 %. S úrovňou dôvery R= 95 % normalizovaná odchýlka ( t-Študentské kritérium pre k
=
 )t
= 1,960.
)t
= 1,960.
Dostupné údaje dosadíme do vzorca:
Preto sú hranice intervalu spoľahlivosti  = 0,122–0,041 = 0,081 alebo 8,1 %;
= 0,122–0,041 = 0,081 alebo 8,1 %;  = 0,122 + 0,041 = 0,163 alebo 16,3 %.
= 0,122 + 0,041 = 0,163 alebo 16,3 %.
S hladinou spoľahlivosti 95 % možno teda konštatovať, že celkový podiel infikovaných semien sa pohybuje medzi 8,1 a 16,3 %.
Príklad 3.4 . Variačný koeficient, ktorý charakterizuje variáciu vápnika (mg %) v krvnom sére opíc, bol rovný 10,6 %. Veľkosť vzorky n= 100. Je potrebné určiť hranice 95 % intervalu spoľahlivosti pre všeobecný parameter životopis.
Hranice spoľahlivosti pre všeobecný variačný koeficient životopis sa určujú podľa nasledujúcich vzorcov:
 a
a  , kde K
medzihodnota vypočítaná podľa vzorca
, kde K
medzihodnota vypočítaná podľa vzorca  .
.
Vedieť to s mierou sebadôvery R= 95 % normalizovaná odchýlka (Studentov t-test pre k
=
 )t
= 1,960, vopred vypočítajte hodnotu KOMU:
)t
= 1,960, vopred vypočítajte hodnotu KOMU:
 .
.
 alebo 9,3 %
alebo 9,3 %
 alebo 12,3 %
alebo 12,3 %
Všeobecný variačný koeficient s pravdepodobnosťou spoľahlivosti 95 % teda leží v rozsahu od 9,3 do 12,3 %. Pri opakovaných vzorkách variačný koeficient nepresiahne 12,3 % a neklesne pod 9,3 % v 95 prípadoch zo 100.
Otázky na sebakontrolu:

Úlohy na samostatné riešenie.
1. Priemerné percento tuku v mlieku na laktáciu kráv krížencov Kholmogory bolo nasledovné: 3,4; 3,6; 3,2; 3,1; 2,9; 3,7; 3,2; 3,6; 4,0; 3,4; 4,1; 3,8; 3,4; 4,0; 3,3; 3,7; 3,5; 3,6; 3,4; 3.8. Nastavte intervaly spoľahlivosti pre celkový priemer na úrovni spoľahlivosti 95 % (20 bodov).
2. Na 400 rastlinách hybridnej raže sa prvé kvety objavili v priemere 70,5 dňa po zasiatí. Štandardná odchýlka bola 6,9 dňa. Určte chybu priemeru a intervalov spoľahlivosti pre priemer populácie a rozptyl na hladine významnosti W= 0,05 a W= 0,01 (25 bodov).
3. Pri štúdiu dĺžky listov 502 exemplárov záhradných jahôd sa získali tieto údaje:
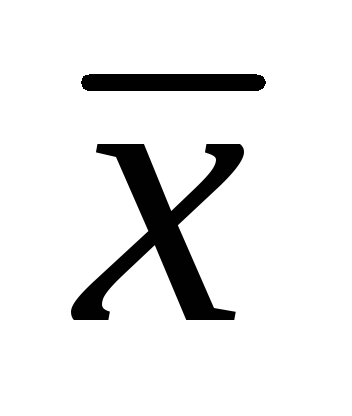 = 7,86 cm; σ = 1,32 cm,
= 7,86 cm; σ = 1,32 cm,  \u003d ± 0,06 cm. Určte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
\u003d ± 0,06 cm. Určte intervaly spoľahlivosti pre aritmetický priemer populácie s hladinami významnosti 0,01; 0,02; 0,05. (25 bodov).
4. Pri skúmaní 150 dospelých mužov bola priemerná výška 167 cm, a σ \u003d 6 cm. Aké sú hranice všeobecného priemeru a všeobecného rozptylu s pravdepodobnosťou spoľahlivosti 0,99 a 0,95? (25 bodov).
5. Distribúciu vápnika v krvnom sére opíc charakterizujú tieto selektívne ukazovatele:
 = 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte graf 95 % intervalu spoľahlivosti pre priemer populácie tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
= 11,94 mg %, σ
= 1,27, n
= 100. Zostrojte graf 95 % intervalu spoľahlivosti pre priemer populácie tohto rozdelenia. Vypočítajte variačný koeficient (25 bodov).
6. Bol študovaný celkový obsah dusíka v krvnej plazme potkanov albínov vo veku 37 a 180 dní. Výsledky sú vyjadrené v gramoch na 100 cm3 plazmy. Vo veku 37 dní malo 9 potkanov: 0,98; 0,83; 0,99; 0,86; 0,90; 0,81; 0,94; 0,92; 0,87. Vo veku 180 dní malo 8 potkanov: 1,20; 1,18; 1,33; 1,21; 1,20; 1,07; 1,13; 1.12. Nastavte intervaly spoľahlivosti pre rozdiel s úrovňou spoľahlivosti 0,95 (50 bodov).
7. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie vápnika (mg %) v krvnom sére opíc, ak pre toto rozdelenie je veľkosť vzorky n = 100, štatistická chyba rozptylu vzorky s σ 2 = 1,60 (40 bodov).
8. Určte hranice 95 % intervalu spoľahlivosti pre všeobecný rozptyl distribúcie 40 kláskov pšenice po dĺžke (σ 2 = 40,87 mm 2). (25 bodov).
9. Fajčenie sa považuje za hlavný predisponujúci faktor k obštrukčnej chorobe pľúc. Pasívne fajčenie sa za takýto faktor nepovažuje. Vedci spochybnili bezpečnosť pasívneho fajčenia a skúmali dýchacie cesty u nefajčiarov, pasívnych a aktívnych fajčiarov. Na charakterizáciu stavu dýchacieho traktu sme vzali jeden z ukazovateľov funkcie vonkajšieho dýchania - maximálnu objemovú rýchlosť stredu výdychu. Zníženie tohto indikátora je znakom zhoršenej priechodnosti dýchacích ciest. Údaje z prieskumu sú uvedené v tabuľke.
|
Počet vyšetrených |
Maximálny stredný výdychový prietok, l/s |
||
|
Smerodajná odchýlka |
|||
|
Nefajčiari |
|||
|
práca v nefajčiarskom priestore | |||
|
pracovať v zadymenej miestnosti | |||
|
fajčiarov |
|||
|
fajčenie malého počtu cigariet | |||
|
priemerný počet fajčiarov cigariet | |||
|
fajčenie veľkého množstva cigariet | |||
V tabuľke nájdite 95 % intervaly spoľahlivosti pre všeobecný priemer a všeobecný rozptyl pre každú zo skupín. Aké sú rozdiely medzi skupinami? Výsledky prezentujte graficky (25 bodov).
10. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný rozptyl počtu prasiatok v 64 pôrodoch, ak štatistická chyba rozptylu vzorky s σ 2 = 8,25 (30 bodov).
11. Je známe, že priemerná hmotnosť králikov je 2,1 kg. Určte hranice 95 % a 99 % intervalov spoľahlivosti pre všeobecný priemer a rozptyl kedy n= 30, σ = 0,56 kg (25 bodov).
12. V 100 klasoch sa meral obsah zrna v klase ( X), dĺžka hrotu ( Y) a hmotnosť zrna v klase ( Z). Nájdite intervaly spoľahlivosti pre všeobecný priemer a rozptyl pre P 1
= 0,95, P 2
= 0,99, P 3
= 0,999 ak
 = 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 bodov).
= 19, = 6,766 cm, = 0,554 g; σ x 2 = 29,153, σ y 2 = 2,111, σ z 2 = 0,064 (25 bodov).
13. V náhodne vybraných 100 klasoch ozimnej pšenice bol spočítaný počet kláskov. Súbor vzoriek bol charakterizovaný nasledujúcimi ukazovateľmi:
 = 15 kláskov a σ = 2,28 ks. Určite presnosť, s akou sa získa priemerný výsledok (
= 15 kláskov a σ = 2,28 ks. Určite presnosť, s akou sa získa priemerný výsledok (  ) a vyneste do grafu interval spoľahlivosti pre celkový priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
) a vyneste do grafu interval spoľahlivosti pre celkový priemer a rozptyl na hladinách významnosti 95 % a 99 % (30 bodov).
14. Počet rebier na schránkach fosílneho mäkkýša Ortambonity kaligrama:
To je známe n = 19, σ = 4,25. Určte hranice intervalu spoľahlivosti pre všeobecný priemer a všeobecný rozptyl na hladine významnosti W = 0,01 (25 bodov).
15. Na stanovenie dojivosti na komerčnej mliečnej farme bola denne stanovená úžitkovosť 15 kráv. Podľa údajov za rok dala každá krava v priemere za deň nasledovné množstvo mlieka (l): 22; 19; 25; dvadsať; 27; 17; tridsať; 21; osemnásť; 24; 26; 23; 25; dvadsať; 24. Nakreslite intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Môžeme očakávať priemernú ročnú dojivosť na kravu 10 000 litrov? (50 bodov).
16. Pre zistenie priemernej úrody pšenice na farme bola vykonaná kosba na vzorových pozemkoch o výmere 1, 3, 2, 5, 2, 6, 1, 3, 2, 11 a 2 ha. Úroda (c/ha) z pozemkov bola 39,4; 38; 35,8; 40; 35; 42,7; 39,3; 41,6; 33; 42; 29 resp. Nakreslite intervaly spoľahlivosti pre všeobecný rozptyl a aritmetický priemer. Dá sa očakávať, že priemerná úroda poľnohospodárskeho podniku bude 42 c/ha? (50 bodov).